
The Data Engineer Roadmap
The right way to become a useful data engineer

I’m offering 50% off the annual subscription. The offer ends soon; grab it now to get full access to nearly 200 high-quality data engineering articles.
Intro
After 6 years of being a data engineer, I’ve realized that data engineering is not an easy field. Moving data from A to B seems like a simple flow at a high level. However, extracting insights from raw data is not easy; reliably ingesting, transforming, storing, and serving it at scale requires significant time and expertise. This is especially true today, when data is generated faster and in more diverse formats than ever before. And data consumers are no longer just humans; AI models and agents are just as hungry as business users.
The challenge of becoming a valuable data engineer does not stop there. Compared to software engineering, data engineering is a relatively new field. The unique characteristics of data products make it extremely hard to provide templates and guidelines for data projects, as each project has different requirements for reliability, scalability, performance, and usability.
In this article, I share my personal roadmap for learning to become a data engineer in 2026. You will see a mix of skills, tools, and my personal experience/sharing.
This article will definitely help you if:
You want to learn data engineering from scratch.
You aim to switch your career from software engineering, data analyst, data science,…
Or you want to grow more as a data engineer.
Some notes before we begin:
First, I assume that you’re aware of a data engineer’s responsibility. This factor is not part of the roadmap, but it drives you to follow it. Make sure you understand it before moving on. You can find my note here.
You shouldn’t be demotivated, as someone on the internet says that AI will do everything for us, from coding to building a pipeline. Given the complexity of data engineering, AI needs our intervention and auditing to work well. And, to guide an AI agent, you must first know how to do things right
This article only focuses on the technical skills/tools. This does not mean that technical skills are everything a data engineer needs. Problem-solving, communication, and a user-oriented mindset are other key factors, but I won’t mention them here to keep the article concise.
TL;DR
I’m offering 50% off the annual subscription. The offer ends soon; grab it now to get full access to nearly 200 high-quality data engineering articles.
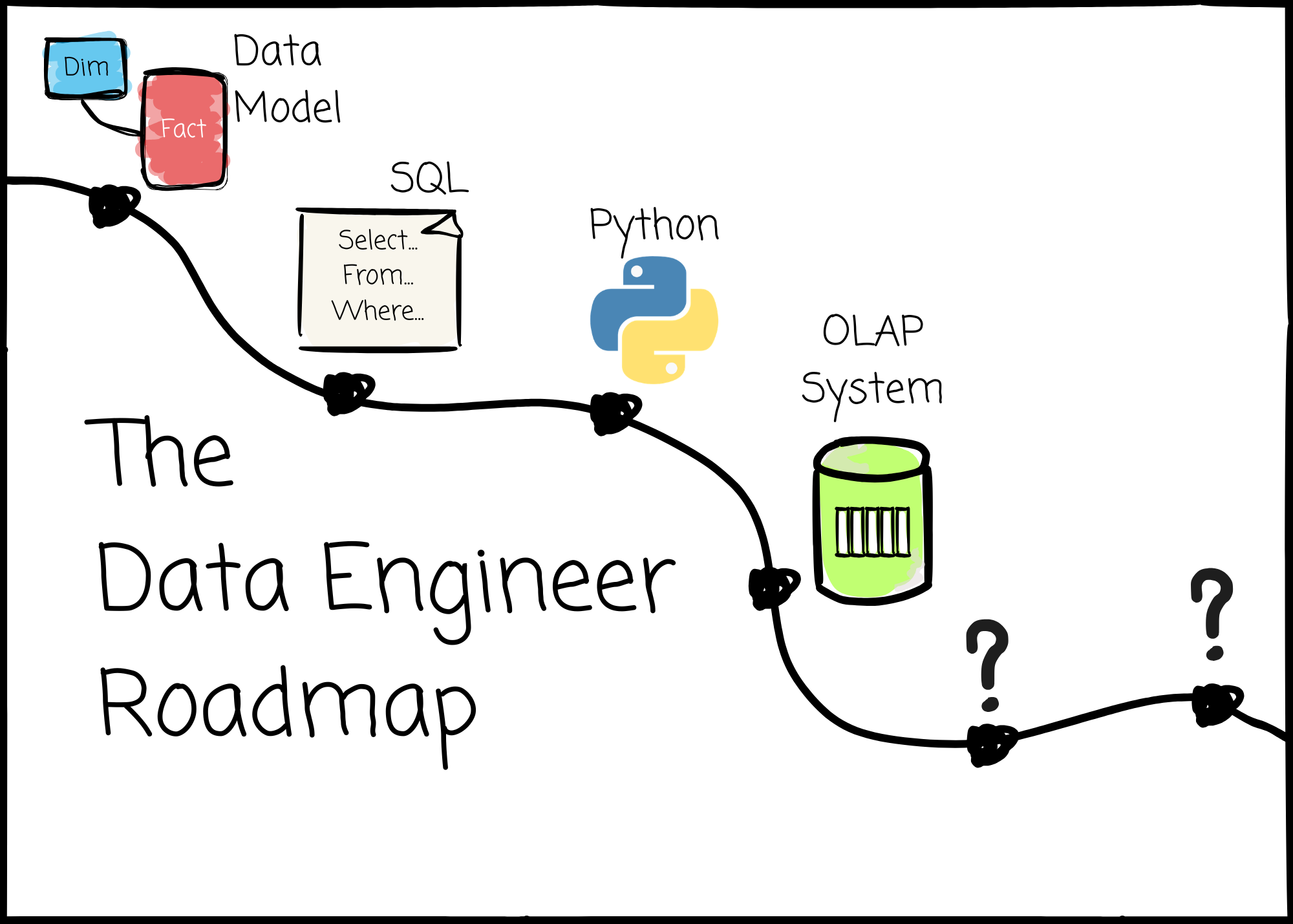
Things a data engineer should learn in order, based on my experience:
Data Modeling
SQL
Python
OLAP systems: cloud data warehouses, DuckDB, open table formats
dbt
Data formats: CSV, JSON, Avro, Parquet (disk), Arrow (memory)
Processing engine: Spark and Polars
Data orchestration: Airflow
Software engineering: Git, CI/CD, Testing, Docker, k8s (optional)
Message system: Kafka
Stream processing: Flink
AI-related: Basic LLM, Agent, Vector database, and how to guide AI do things for us.
Data Modeling
From raw to insight, you must answer these two questions:
How do I transform the data?
How do I organize the data so it can be served and used efficiently?
You can go case by case at first. For example, a user A needs this kind of table, so you build a pipeline for it. Then user B needs another table, so you build another pipeline for it. Things work. However, as the use case expands, the number of sources increases, and the way data is served changes, we will have trouble.
Ambiguous terms (finance “customer” vs sale “customer”?), silo data, adding a new source requires at least 2 weeks, different results on the same metric, slow queries, and no trust from business users.
All because we lack a bigger picture.
Based on Joe Reis, the author of the famous Fundamentals of Data Engineering book:
A data model is a structured representation that organizes and standardizes data to enable and guide human and machine behavior, inform decision-making, and facilitate actions. — Joe Reis
With data modeling, we will have:
A Common Language: With data modeling, we have a shared, unified view of the organization’s data, facilitating clear communication between stakeholders.
Data Quality and Integrity: Modeling constraints and relationships gives us a good starting point for ensuring data quality.
Reduces Errors: A data analyst knows exactly how to query a piece of insight. A data engineer knows exactly where the data will be loaded. All necessary transformations are performed beforehand, leaving the data well-organized and ready to serve. A good data model minimizes errors.
—
If I read a data engineering roadmap online and it doesn't include learning data modeling as one of the first steps, I will skip it right away.
The rise of “Putting more resources into the cloud data warehouse“ and “AI can do everything “ usually makes people think data modeling is not needed anymore. However, I think that’s not true; if we want AI to plug in and answer analytics questions, it must first understand the semantics of the data.
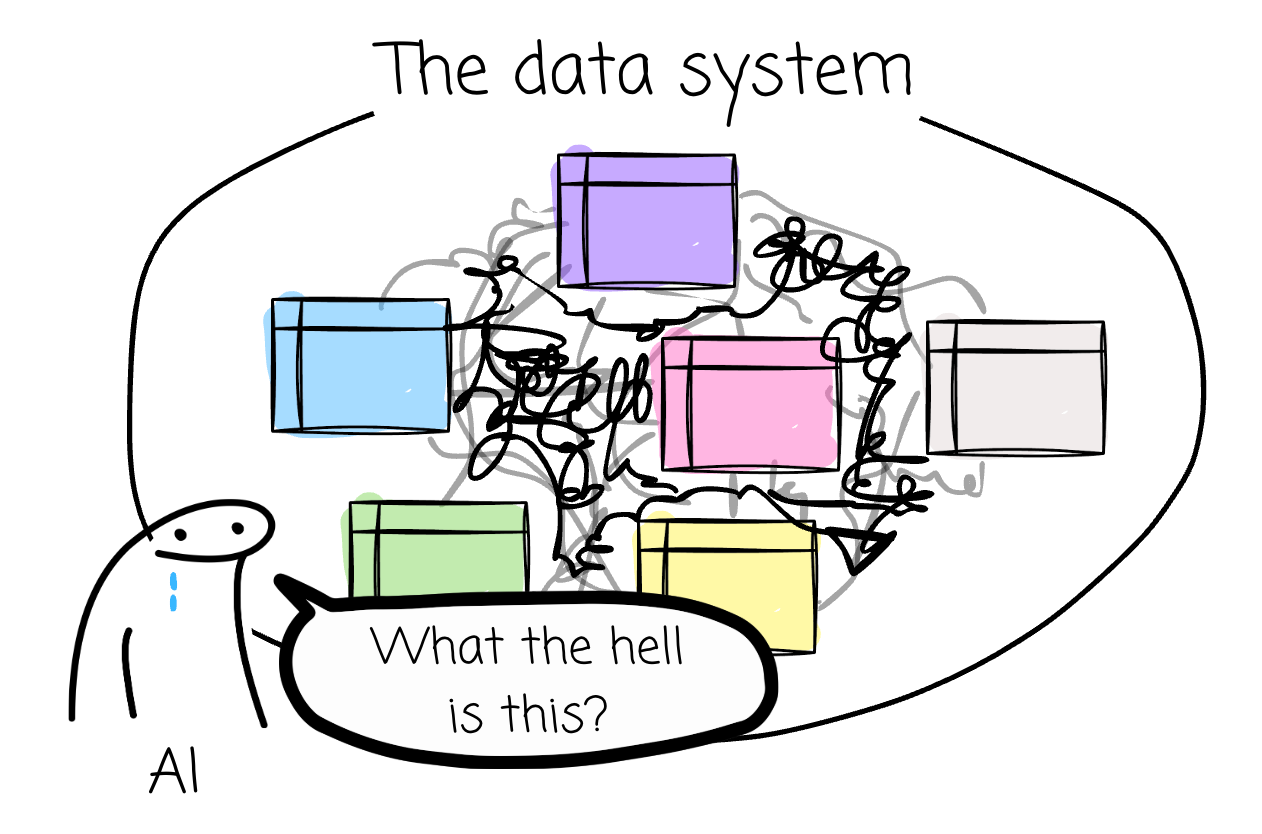
Some say we can put the semantic layer right on top of raw data, and the problem is solved. I don’t agree with that. For me, data modeling is the core of any analytical data foundation, while the semantic layer sits on top, providing context and meaning. There are two typical processes in the semantic layer:
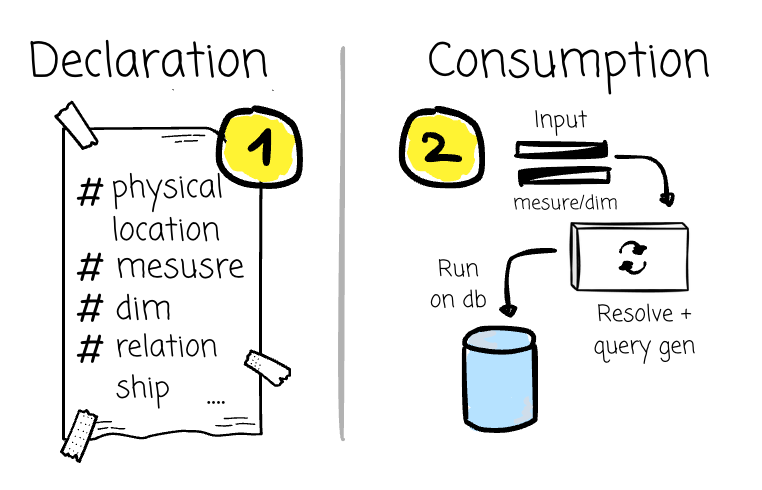
Declaration: You onboard data assets along with their relationships, define calculations, and might perform lightweight transformations.
Consumption: Users navigate and select the desired metrics and dimensions exposed by the semantic layer (with more user-friendly names). The input is then converted into an SQL query that leverages the information from the Declaration stage.
The performance and usability of the consumption stage depend on the declaration stage. The declaration stage, in turn, depends on how your company stores and organizes data. And data modeling controls those processes. If you don’t have data modeling at all, your semantic layer will also be a mess.
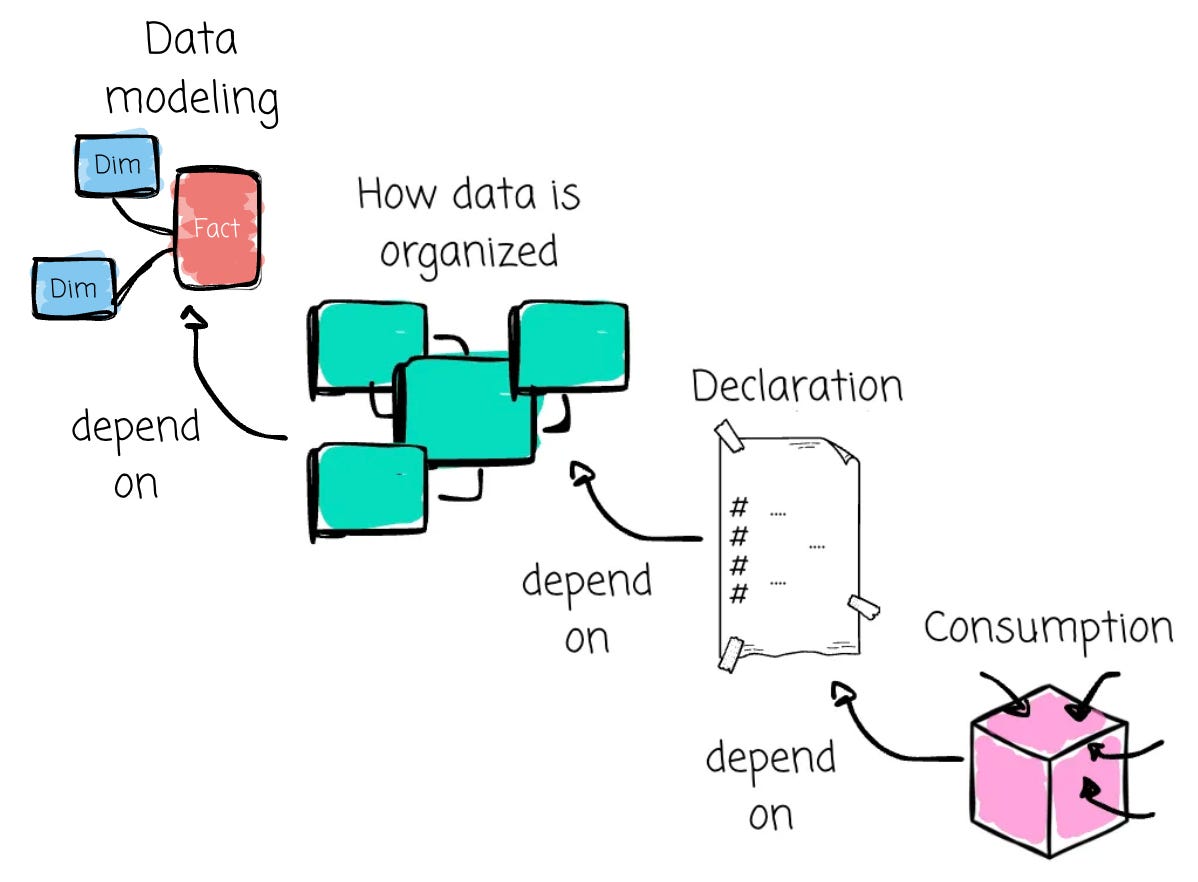
In short, learn data modeling, or more precisely, the mindset of “data must be organized in a way that it can support and reflect the company's business.”
Get started with dimensional modeling. Read the first 3,4 chapters of the book The Data Warehouse Toolkit and build some simple models. Dimensional modeling is easy to get started with and is adopted by many companies. You might need to learn other modeling techniques later, but dimensional modeling should be your first.
Here are my previous articles to help you get started with Kimball:



SQL
If you work in the data field, you “speak“ SQL. The language was designed in the 1970s to manipulate and retrieve data from relational databases. Since then, it has gained increasing adoption worldwide as the primary interface for working with these databases.
The evolution of OLAP databases and the rise of transformation tools, such as dbt, make SQL an attractive choice for data transformation, which was previously handled by procedural languages like Java or Python. Some cloud data warehouses, such as BigQuery, even allow users to use SQL for machine learning.
If you can write SQL, you can turn raw data into insights when the data is already in the database.
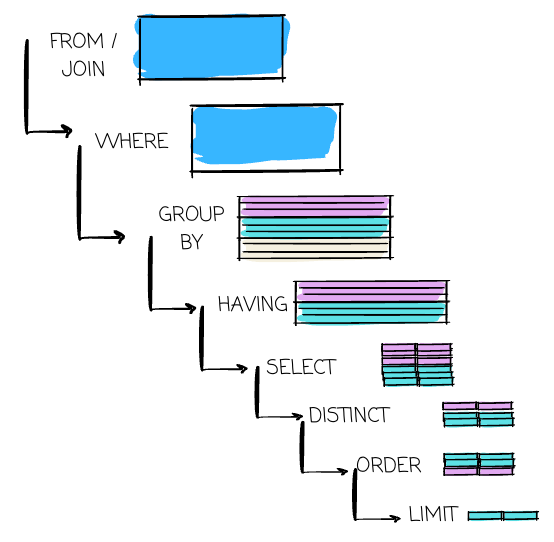
So, make sure you learn SQL at the start of the journey. You can learn it alongside data modeling so you can practice both simultaneously (e.g., use SQL to transform raw data into predefined models). Make yourself familiar with grouping, aggregation, ordering, different types of joins, CTEs, and window functions.
Then, take a closer look at how things are carried out behind a SQL query. As data engineers, we must write scalable, readable, and runnable queries. Understanding the internal allows you to debug and optimize the query.
Also, when you practice the SQL question, please make sure your first step is to fully understand the question and the provided data schema.
Here is my article to help you get started with SQL:

Python
Data practitioners utilize SQL for many purposes, but not for everything. Python can make up for that.
You see repetitive tasks and want to automate them. Python can do it.
You face complex transformations that are difficult to express in SQL. Python with PySpark, Pandas, or Polars can help.
Data comes from many systems. Python can help pull them via the REST API.
You need to orchestrate many data pipeline steps. Python can help with tools like Airflow or Dagster.
Or, you want to build a data application. Python can help with Streamlit or a backend framework like FastAPI.
You must learn Python.
Learning Python is easier than other languages because its syntax is simpler. There are numerous resources available to help us learn how to write a function, an if clause, or a class in Python.
However, learning syntax is never enough. Writing code is not hard, but writing readable, maintainable, and extendable code needs time. We need to care for others. No matter how good your Python program performs, if your colleagues don’t understand what you’re doing or find it extremely challenging to extend your work, your shiny code is useless.
You can first start by learning the syntax, getting familiar with data processing with NumPy/Pandas, and making API calls. If you could, write a simple class to manage API requests, including making requests, handling responses, and paginating. Don’t rush to use Python directly in PySpark or Airflow; the goal is to master the syntax and understand how well the code is written in Python (idiomatic Python).
Pay attention to writing organized code as soon as possible. Learning design patterns (Python-general or data-pipeline-specific), coding principles like SOLID, or reading the Clean Code book.
OLAP
Your transformed data must be stored somewhere to serve end users, and an OLAP database is the most common destination of a data pipeline. It’s the physical implementation of your data warehouse.
I’m offering 50% off the annual subscription. The offer ends soon; grab it now to get full access to nearly 200 high-quality data engineering articles.
