
SQL For Data Engineers
A note on everything a data engineer should know about SQL

To celebrate Lunar New Year (the true New Year holiday in Vietnam), I’m offering 50% off the annual subscription. The offer ends soon; grab it now to get full access to nearly 200 high-quality data engineering articles.
Intro
I was wrong in many things, one of them was learning SQL too late. I used to believe that I should put full effort into Python, and I would be fine. The fact is, everybody speaks SQL in the data world!
This article is a reflection on my experience after several years of learning SQL as a data engineer. The goal is to provide you and me with a strong foundation in this query language; from there, learning or working with SQL will be more effective.
History
Edgar F. Codd. In June 1970, while working at IBM, Codd published his paper, “A Relational Model of Data for Large Shared Data Banks.” This paper introduced a new model for managing data, now accepted as the dominant approach for Relational Database Management Systems (RDBMS).
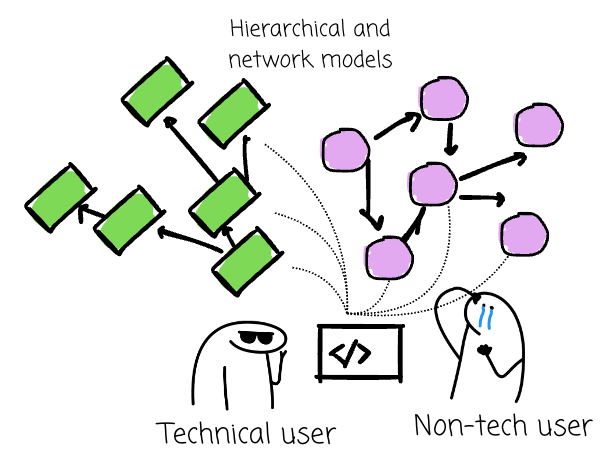
Before Codd’s work, databases were dominated by navigational models, such as the hierarchical and network models. Data was accessed by “navigating” through records using pointers and predefined paths. The programmer must specify the exact step-by-step procedure—the how—to retrieve a piece of information.
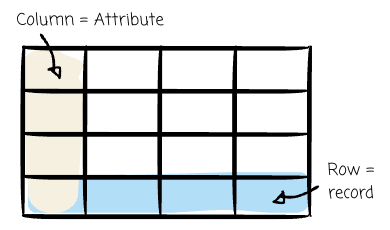
Codd doesn’t think it's a good idea because only heavily trained technical users can use these systems. His relational model suggested that data be organized into simple tables, called “relations,” composed of rows (”tuples”) and columns (”attributes”).
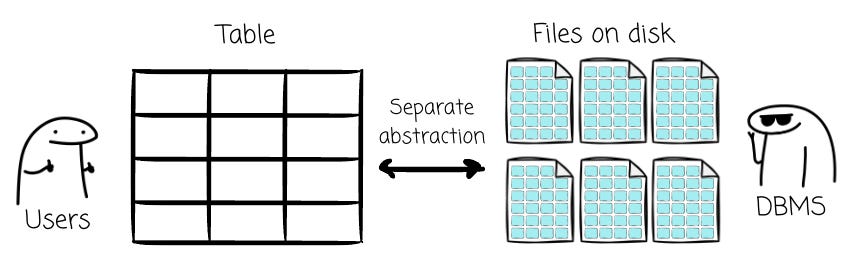
More importantly, it separated the logical representation of data from its physical storage and access methods. This abstraction enabled the creation of a more declarative language to work with data.
It allows a user to specify what data they want, leaving the complex task of retrieving it to the database management system. Following the publication of Codd’s model, IBM scientists Donald Chamberlin and Raymond Boyce developed a language to implement it, which they called Structured English Query Language (SEQUEL).
This was later shortened to SQL (often still pronounced “sequel”). The first commercially available implementation of SQL was introduced in 1979 by Relational Software, Inc., the company that would later become Oracle Corporation. The American National Standards Institute (ANSI) standardized SQL in 1986, followed by the International Organization for Standardization (ISO) in 1987.
Relation algebra
SQL is declarative. It’s cool. However, the database still needs to translate the SQL query into “procedural steps“ (e.g., reading these tables, selecting this field,…). The mathematical framework for this step is Relational Algebra. It comprises a set of operators that operate on relations. The fundamental operators of relational algebra are as follows:
Selection (σ): This unary operator filters the tuples (rows) of a relation based on a specified condition or predicate. It corresponds directly to the WHERE clause (surprisingly, it’s not the SELECT). For example, the expression σsalary>500(Employees) is equivalent to SELECT * FROM Employees WHERE salary > 500;.

Projection (Π): This unary operator selects a subset of the attributes (columns) of a relation. It corresponds to the SELECT. For example,
Πname, department(Employees) is equivalent to SELECT name, department FROM Employees;.

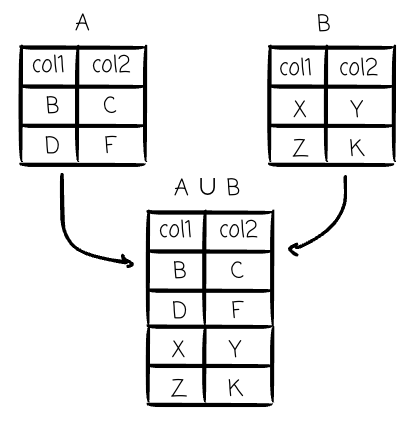
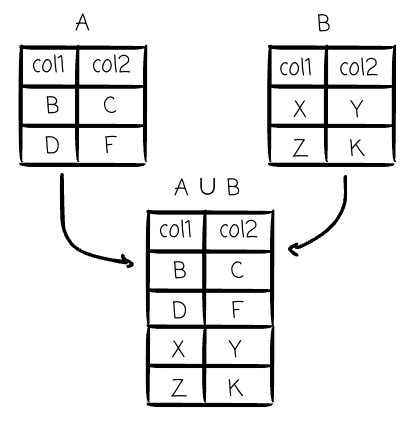
Union (∪): This binary operator combines two “union-compatible” relations (they must have the same set of columns). The result contains all tuples that appear in either or both relations, with duplicates removed. This maps to the UNION operator in SQL.
Set Difference (−): This binary operator returns all tuples that are in the first relation but not in the second.
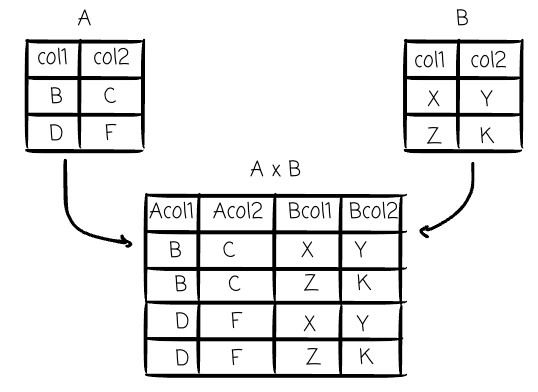
Cartesian Product (×): This binary operator combines every tuple from the first relation with every tuple from the second relation. It is the foundational operation for all SQL JOINs and is explicitly implemented by the CROSS JOIN operator.
Join (⨝): This is a binary operator that combines data from two relations based on conditions. It is fundamentally a Cartesian product followed by a selection.
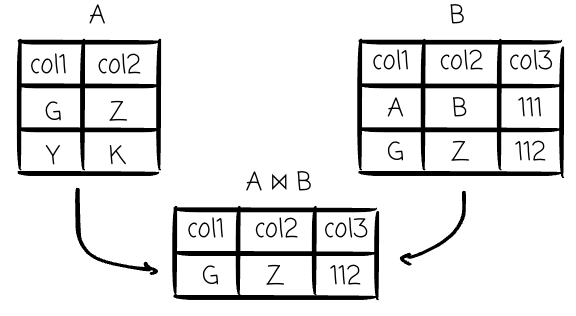
For instance, an equi-join is a Cartesian product followed by a selection that keeps only the rows where the join keys are equal.
This concept maps to the entire family of JOIN clauses in SQL (INNER JOIN, OUTER JOIN, etc.).
Intersection (∩): This binary operator returns all tuples that are common to both relations. It can be derived using the set difference operator (A-B = A∩−(A−B)). Unlike the Join operator, this operator requires the two relations to have the same schema.
This maps directly to the INTERSECT operator in SQL. It is rarely seen in SQL implementations; however, it remains part of the ANSI SQL standard (optional)


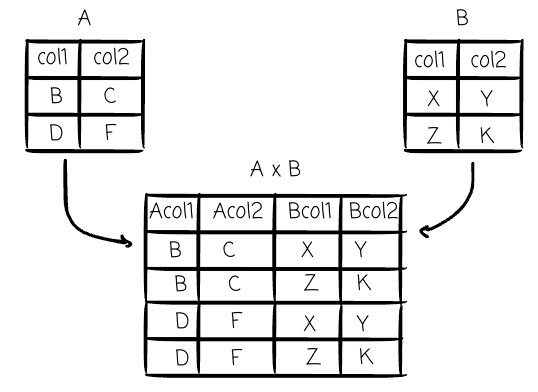
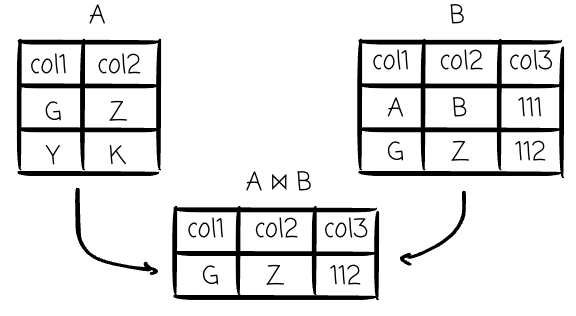
Clauses
This article only covers the DQL’s clauses; you won’t see DML’s clauses like INSERT, UPDATE, or DELETE here.
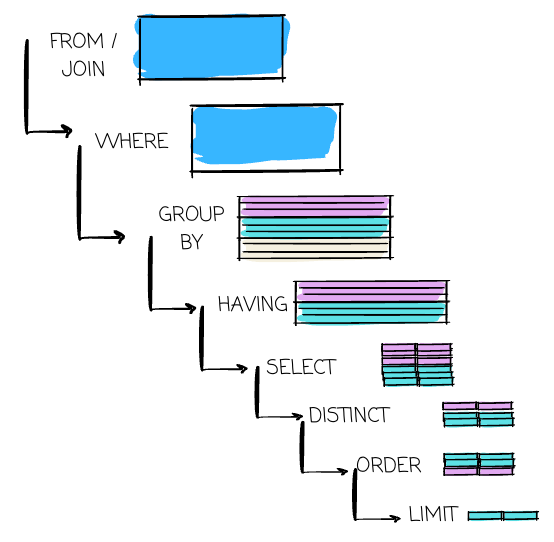
Because you tell the system what you want via SQL, there are clauses, the “verbs“ to describe the action you want with the data. The section will cover most of the 95% (at least to me) SQL queries. These will also be listed based on the order of the physical execution behind the scenes.
To celebrate Lunar New Year (the true New Year holiday in Vietnam), I’m offering 50% off the annual subscription. The offer ends soon; grab it now to get full access to nearly 200 high-quality data engineering articles.