To complete the data-engineering system design series (after the three parts: serving, sourcing, and orchestration), we will now turn to the final part: data processing.
It’s the last part until I feel it necessary to cover some other aspects :D
The format will be the same.
There is a set of data processing problems that I believe are crucial. Each problem will be discussed in its own section, which includes my personal thoughts on why and how we’ll solve it. The 9 problems are:
Batch or stream processing?
What are the business rules?
How do you ensure data quality at the processing layer?
How do you ensure the processing logic is correct?
What if the pipeline fails?
Can the pipeline be backfilled?
What is the side effect of reruns?
How are credentials and configurations managed?
How do you observe the processing?
Note: What is discussed in this article is based solely on my observations and experience; feel free to provide feedback on anything you see I may have missed.
Mental Model
Data processing is the layer that sits between the source and the sink. I want to refer to this layer as “middle steps“ as “processing” does not cover everything that happens here.
This layer takes what the source gives you and shapes it into what the sink needs.
The source doesn’t care about your output requirements.
The sink doesn’t care about what the source looks like.
The “middle steps“ absorb the gap between them and make sure the gap is filled.
Just keep in mind that, to fill that gap, many things need to be evaluated and resolved; it is not only about choosing between Flink and Spark. Business logic, data quality decisions, failure handling, schema changes, processing framework, distributed vs. single-node, and other concerns.
Batch or stream processing?
This is the question that shapes every infrastructure decision that follows. The way you should think about it depends on whether you’re building a batch or streaming pipeline.
The choice between batch and stream processing should be defined based on serving and sourcing information/requirements.
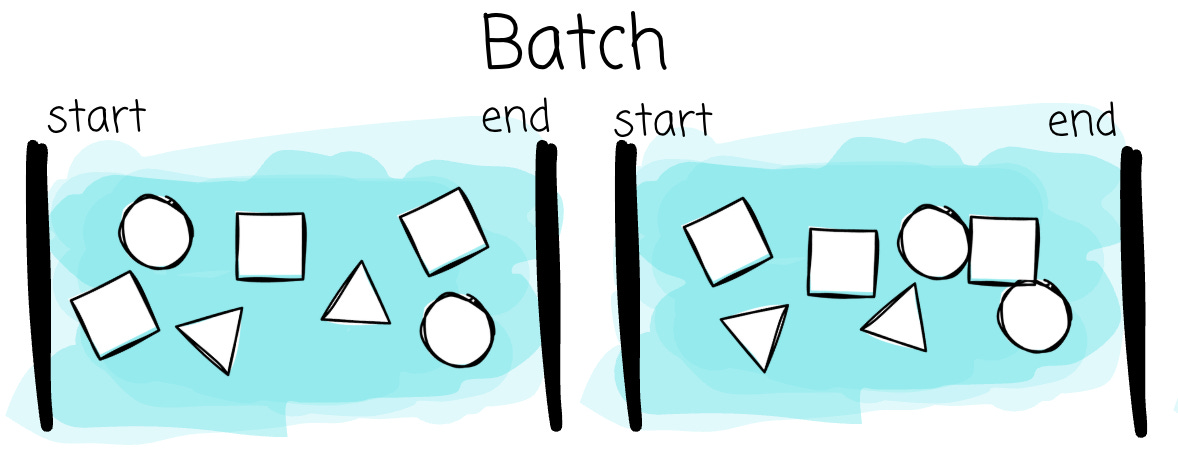
Batch
In a batch, the natural questions are straightforward:
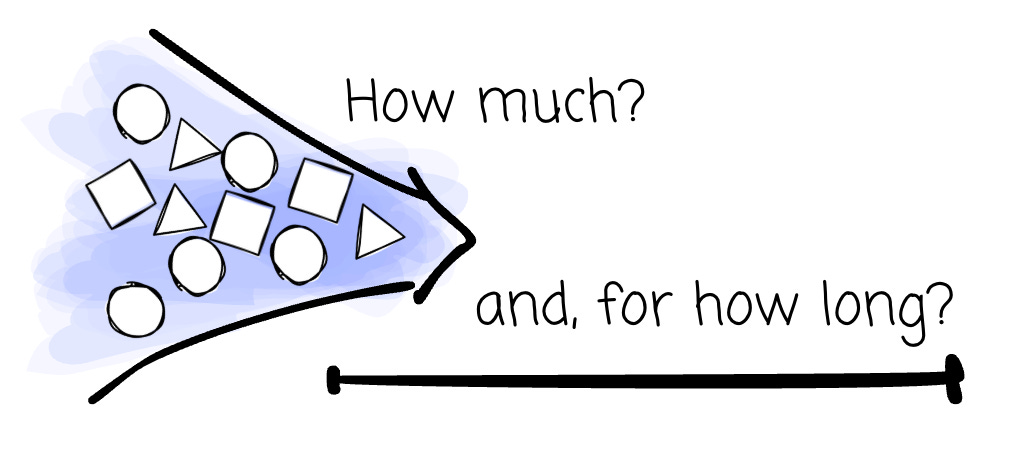
How much data?
And how long does the data processing have to finish?
The two questions work together to help you identify a less straightforward problem: your system's throughput.
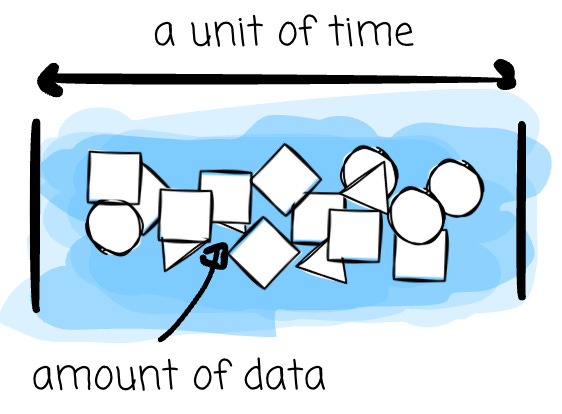
Throughput is the sustained rate your system needs to maintain: records per second, gigabytes per hour, or terabytes per day. For me, throughput is the one that helps you estimate the resource, not the data volume. Processing 1TB of data in 20 hours is different from processing it in 30 minutes.
You need higher throughput when:
You increase the data, but keep the time window the same
You shorten the time window and keep the input data the same
Higher throughput usually means more RAM/CPUs per worker and a large number of workers. In return, you will have higher billing.
Lower throughput happens when:
You decrease the data but keep the time window the same.
You lengthen the time window and keep the input data the same.
Lower throughput usually means fewer resources are needed, which in turn can save costs.
In high-throughput use cases, we can consider DuckDB or Polars with high RAM/CPU/Disk, and move to Spark or SQL-based distributed processing systems such as Snowflake, BigQuery, Databricks, or Trino if the required resources no longer fit on a single node. The tuning of all resources should also center on throughput rather than solely on data volume.
Stream
I invite you to join my paid membership list for only 7$/month (pay annually) to get access to:
This article + other 200+ deep-dive data engineering articles