
Batch and Stream Processing
What they are and how they're implemented. Fundamental knowledge that can be applied to any processing framework.

I will publish a paid article every Tuesday. I wrote these with one goal in mind: to offer my readers, whether they are feeling overwhelmed when beginning the journey or seeking a deeper understanding of the field, 15 minutes of practical lessons and insights on nearly everything related to data engineering.
Intro
One of the data engineer's responsibilities is to capture the real-life data, add spices, cook, and serve it. There are different ways to do it. We wait for the collected data to reach a certain threshold (e.g., daily, weekly,…), then process them all at once. This is called batch processing.
That might be too long. Instead of waiting, we can process a piece of data right after it happens. After completing this piece, the next one will follow, and things will continue to unfold in this manner. This is called stream processing.
In this article, we delve deep into these data processing concepts, what they are, how they differ, the trade-offs, and the key considerations.
tl;dr
Batch: A Simple and more familiar data processing paradigm. The complete view of the data simplifies the data processing and re-processing. However, users have to wait → High latency.
Stream: Far lower latency and treat data as an unbounded flow. To facilitate efficient and reliable data processing, users must consider several key aspects, including windowing, event-time vs processing time, watermark state, and checkpointing. This approach, however, introduces a higher learning curve. Implement this only if your organization truly gets benefit from stream processing.
Batch
Batch processing is the most straightforward to understand. You assemble the data over a period and then process it in a single operation.
You read a CSV file, load it into memory, process it with Spark, and then write the results to the database. That is batch processing. You take a snapshot of an OLTP database, transform it with SQL, and load it into the data warehouse. That is batch processing.
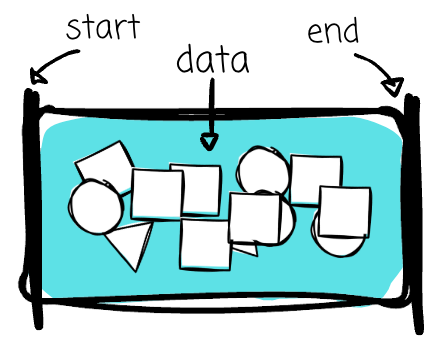
A CSV file or a database snapshot shares a characteristic: they capture the data in a defined boundary, which might be an hour, a day, 3 days, or a week of data. When a system processes data in a batch, it knows the size of the processed data beforehand. This finite view significantly simplifies the data processing.
Essentially, aggregation and joining are searching for records with the same key. With batch processing, the system knows beforehand the scope of the searching process. This is sound obvious, but when it comes to stream processing (the system doesn’t see the scope for search), you will understand clearly this advantage of batch processing.
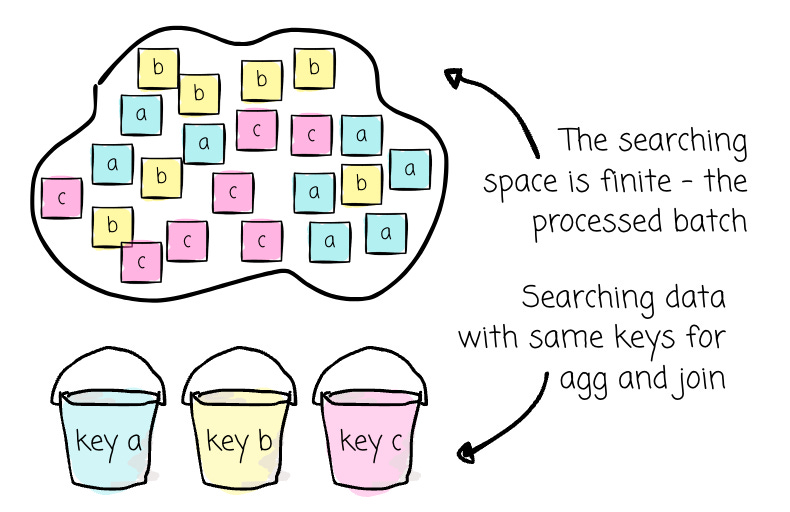
In addition, achieving fault tolerance or the re-processing ability is straightforward if we have these three conditions:
The data source is available when we need to reprocess.
We can control this by keeping the data source for a while (placing the CSV data or database snapshot in the object storage)
The processing is deterministic. With the same input, the processing guarantees to produce the same output no matter how many times it runs. This guarantees we can reproduce the output with the same process logic and input data.
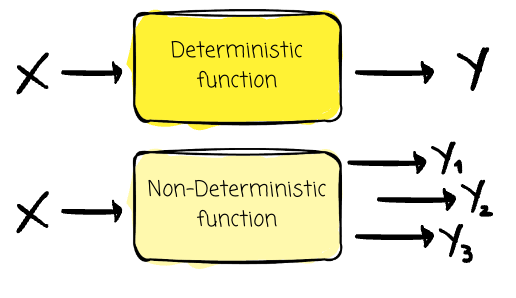
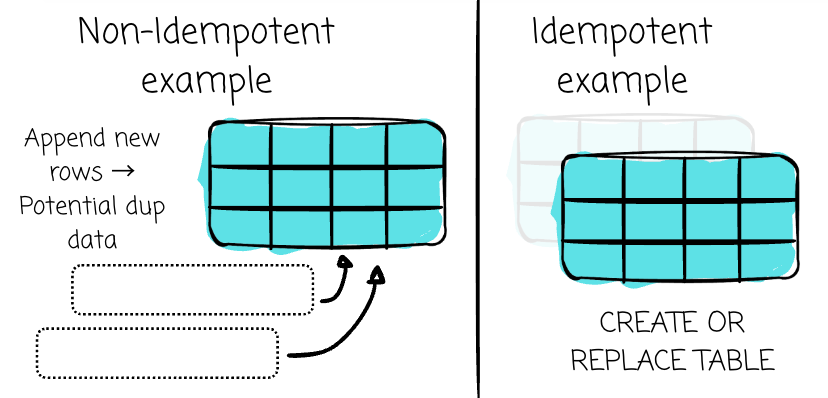
The effect of the processing is idempotent. In simpler terms, idempotence means that doing something once has the same effect as doing it many times.
For example, f(x) = 1*x is an idempotent function, as we can get the same result when running this function multiple times for the same input.
In batch processing, to achieve idempotence, the next run with the same input must replace entirely any previous output of the prior run
This guarantees we don’t cause side effects with subsequent runs (e.g., append duplicate data or mix up data between runs)
We can control this by using an idempotent operation to materialize the data. `CREATE OR REPLACE TABLE` and dbt’s insert overwrite strategy are examples.
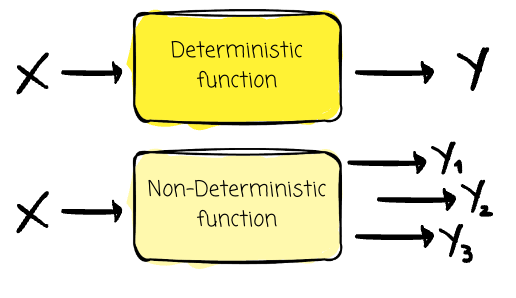
Note: Deterministic refers to the output, while idempotence pertains to the effect of the output on the system.
Systems like Spark enhance fault tolerance efficiency by re-processing only the affected data, rather than all of it. Spark’s unit of computation is RDD. Spark keeps track of each RDD’s dependencies on other RDDs, the series of transformations that created it.
Suppose any partition of an RDD is lost due to a node failure or other issues. Spark can reconstruct the lost data by reapplying the transformations to the original dataset described by the lineage.
Batch processing is implemented quite similarly in many systems. From being aware of the boundary dataset, planning the processing (in the most optimized way), to scheduling the physical processing on the worker(s).
The data boundary
Batch processing is excellent in terms of operational complexity and ease of use. However, it's bad at one thing: it has to wait for the data to reach a threshold. Sometimes, users don’t want to wait (too long). Some businesses require the data to be processed as soon as it happens: a recommendation system needs to react to the user's actions, or a payment service needs to detect an anomalous transaction as quickly as possible.
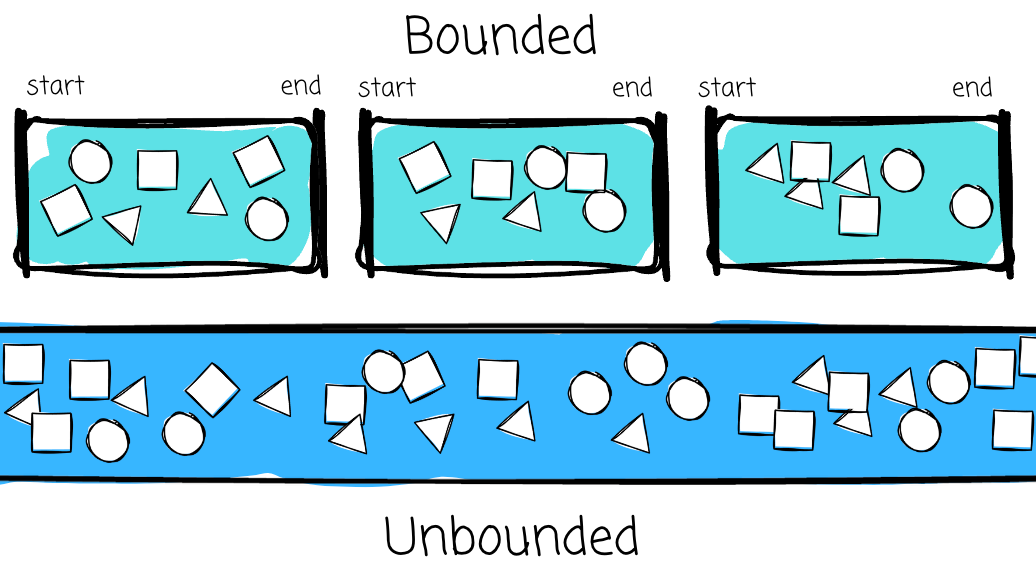
We enter the realm of stream processing, which promises far lower latency compared to batch and enables us to deal with the data in its natural form, a continuous flow.
Let’s take a look around and think about it. Most of the data we work with doesn’t have a natural boundary; in other words, it is unbounded: from the user interaction on the website (unless the website is down) to data from IoT sensors (unless the sensor runs out of power).
With batch processing, we impose artificial boundaries (e.g., one day of data) to simplify the data processing. Unbounded or bounded data is a crucial characteristic when it comes to distinguishing between batch and real-time processing.
Stream processing
There are two approaches to implement stream processing: the first is micro-batching (Spark Structured Streaming) and record-by-record, which is also referred to as accurate stream processing, or Flink. The insight in this section could be applied to both of the approaches.