
What is Apache Hive?
Why did Meta create it years ago, and why don't you see it anymore

My ultimate goal is to help you break into the data engineering field and become a more impactful data engineer. I'm excited to introduce a paid membership option to take this a step further and dedicate even more time to creating in-depth, practical content.
This will allow me to produce even higher-quality articles, diving deeper into the topics that matter most for your growth and making this whole endeavor more sustainable.
To celebrate this new milestone, I’m offering a limited-time 50% discount on the annual plan.

Intro
When everybody is talking about Delta Lake, Iceberg, and Hudi, we might forget there was an early effort more than 15 years ago to achieve the same thing that these three table formats are trying to achieve: bringing the table abstraction to the data lake.
Meta built Apache Hive to make Hadoop a complete warehouse solution. Since it is open-source, Hive has gained a lot of attention and is supported by most query engines. However, it soon showed limitations and was gradually replaced by modern table formats.
I spent quite a lot of time learning Hive while researching the article “Why do we need open table formats like Delta Lake or Iceberg?” I thought having a dedicated article about Hive would be a good idea, given that I’ve already written about Delta Lake, Iceberg, and Hudi.
This article will explore Hive's motivation, architecture, pros and cons, and why it falls behind.
Overview
Meta released a paper in 2009 to officially introduce Hive, an open-source data warehousing solution built on top of Hadoop. But surely, Meta worked with Hive sooner than that, when Hadoop started to gain its place in the big data world.
In Hadoop’s prime time, MapReduce was the apparent option for data processing. However, this programming model is pretty low-level and requires users to define the Map and Reduce tasks explicitly.
Hive aims to provide a more intuitive way for users to build a MapReduce job. It lets users express the logic in SQL-like declarative language, which Hive translates into MapReduce jobs.

Hive also tried to provide a simple table abstraction on top of the files in HDFS. This abstraction helps Meta implement the capability of expressing MapReduce jobs in SQL. If someone tells you to query data using SQL, one of the first things that comes to mind would be “Which tables should I put in the FROM clause?“

Hive manages tables’ related information like schemas and statistics in the Hive-Metastore catalog.
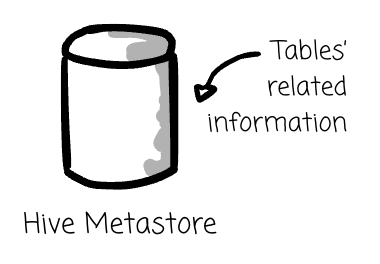
Hive generally tries to bring database features to the HDFS data lake; it provides a query compiler (SQL → MapReduce job), table abstraction, and system catalog. In the next section, we will explore the data model in Hive.
How Hive organizes data
It organizes data into folders:
Table: Each table has an HDFS directory.
Partitions: Each table can have partitions. Each partition corresponds to a subdirectory.
A `sales` table, which is partitioned by `date`, will have the following structure in Hive.

Table: root/folder_1/sales
Partitions: root/folder_1/sales/date=2025-01-01, root/folder_1/sales/date=2025-01-02, …
Besides tables and partitions, Hive also has the concept of buckets. The data will be distributed into buckets in each partition based on the column’s hash value. Each bucket is stored as a file in the partition directory.
Hive supports common column types (int, float, strings, dates, and bool) and more complex types such as array and map.
If users need their data to be stored with a custom type, they can define their own types programmatically.
Query Language
Users interact with Hive via an SQL-like language called HiveQL. This language supports select, join, aggregate, union, and subqueries. It also supports data definition statements to create tables with information such as serialization formats, partitioning schemes, and bucketing columns.
Users can load data from external sources and insert query results into Hive tables with data manipulation (DML) statements. Data modification can only be done on the partition level. A small change must replace all partitions. We will be able to dive into this later.
The user can define UDFs in Java for Hive to extend its processing functionalities.
The architecture
Hive has some primary components:

Interfaces: Users can interact with Hive via the CLI, the web UI, JDBC, or ODBC
The Hive Thrift Server: The server exposes a set of client API to execute HiveQL statements. The Thrift Hive clients are generated in different languages and used to build standard drivers like JDBC (Java) and ODBC (C++), or scripting drivers written in Python.
Thrift is a serialization and RPC framework for service communication. — Source —
The Metastore: This is the system catalog, which provides necessary information for all other components.
The Driver: The brain that manages HiveQL’s entire life cycle, from compilation to optimization and execution.
The Compiler: The Driver communicates with the Compiler to translate the HiveQL statement to the DAG of the MapReduce jobs.
Execution Engine: The driver then submits the DAG’s jobs to the Execution Engine in a topological order. At that time, Hive used Hadoop as its execution engine.
The Metastore
Like the database catalog, the Hive metastore contains metadata of all data in Hive. The metastore will record the metadata when users create Hive tables and serve this metadata for any component that needs it.
The store contains the following objects:

Database is the table’s namespace. Hive will use ‘default’ for the database name if the user does not specify the namespace.
Table: For a table, Hive records the column list and each column’s type, the table’s owner, the SerDe information, and the storage. Storage information includes the physical location of the table’s data, the data formats, and bucketing information. The SerDe provides information about serializer/deserializer methods.
Partition: A partition can have columns, SerDe, and storage information.
The metastore is backed by a traditional relational database like MySQL or PostgreSQL.
To get a broader view, you can check my previous article here, where I discuss the motivations of data warehouses, data lakes, and data lakehouses, the fall of Hive, and the rise of modern table formats like Delta Lake, Iceberg, and Hudi.

Why did Hive fall behind
Although Hive was widely adopted initially, people have forgotten it over time. In 2025, you might not see anybody around you using Hive in their organization.
As mentioned in the “Overview” section, for me, Meta tried to bring the database to the HDFS-based lake by developing a query compiler and a table abstraction atop HDFS’s files.
When people tried to replace MapReduce with more flexible and user-friendly programming models like Spark, Hive's SQL-MapReduce compiler has become obsolete.
So, there was only the table abstraction left. Although the Hive data model was initially simple and widely adopted, it soon showed limitations, especially when organizations moved their data lakes from the local HDFS to cloud object storage.
First, there was the mismatch in transaction guarantees between the two systems. Although the Hive’s relational database can ensure that partition information is modified in a transactional manner, the filesystem that manages the data does not guarantee any transaction. A file may contain corrupted data if the write process is interrupted before completion.

Thus, Hive initially only allowed users to modify data at the partition level. Users would modify the data while replicating the partition and then update the metastore to reflect the new partition’s location. A small data change would require operating on a whole partition. Later, Hive supports ACID guarantees only for ORC format in version 0.14.0.
Secondly, Apache Hive's data organization approach may degrade the performance of data operations in object storage. Although S3 or GCS allows users to store data in “subdirectories,” these object storage systems manage data differently from what we are familiar with in a filesystem. Unlike the filesystems’ hierarchical structure, the object storage structure is flat. The path you see in the object storage, like bucket/country/date/…, is the prefix of your objects.
Cloud object storage suggests that data read operations should have as many different prefixes as possible so that they can be handled by other servers in cloud object storage.
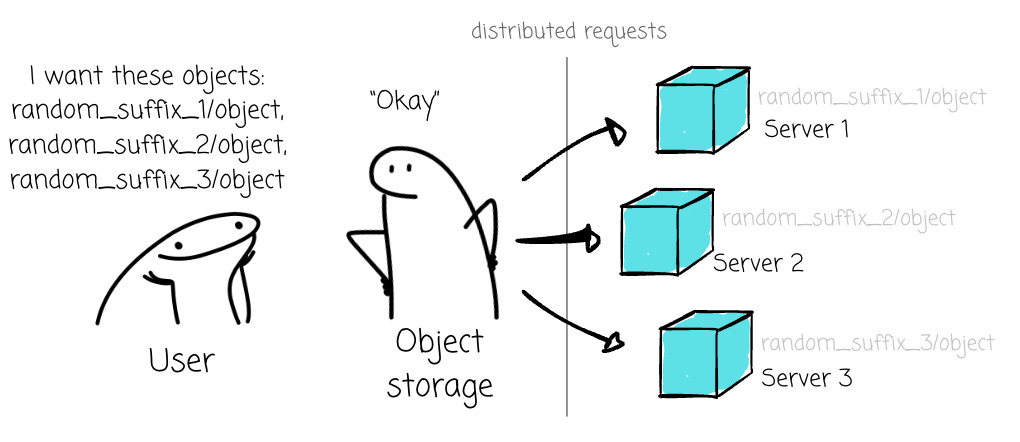
With Hive, data for the same partitions (prefixes on object storage) is usually retrieved together, which might cause all the requests not to be distributed evenly, thus reducing the performance.

The next Hive’s problem is file listing. Before reading files in a partition, the engine must list them in a directory to determine which files it will read. This can take a considerable amount of time for a large partition. This problem worsens when people try to deploy the Hive data lake using object storage.

In addition, table concurrent writing in Hive is tough to achieve. Users must implement locks on the Hive Metastore to enable multiple people to modify the table safely. The general idea is that a writer can only change a table if they can acquire the lock. This affects the system's throughput.

Over time, formats like Delta Lake, Iceberg, and Hudi have been trying to provide a more robust table abstraction than Hive. Unlike Hive, they were designed to work efficiently on object storage with the support of schema evolution, efficient data management, physical layout techniques, and ACID support.
Hive has tried to catch up, but it might not be enough. Although it supports ACID in later versions, this feature is only available for the ORC format.
Outro
Hive doesn’t have as much adoption as it used to. If a company wants to build a lakehouse architecture in 2025, Iceberg, Delta Lake, and Hudi would be at the top of their minds.
However, we can’t set Hive aside in the data lakehouse evolution. It pioneered table abstraction atop a bunch of files in the lake. Without Hive, we might not see the growth of Iceberg, Delta Lake, and Hudi. It paved the way for the later development of these formats.
Reference
[1] Facebook Data Infrastructure Team, Hive - A Warehousing Solution Over a Map-Reduce Framework (2009)
thanks for this great high level overview about the Hive. I remember that time when we discussed about Impala or Hive is the better. :)
I agree with your outro, without Hive, we wouldn't have Iceberg, Delta Table or Hudi. However, I think, it is time to let it go now.