
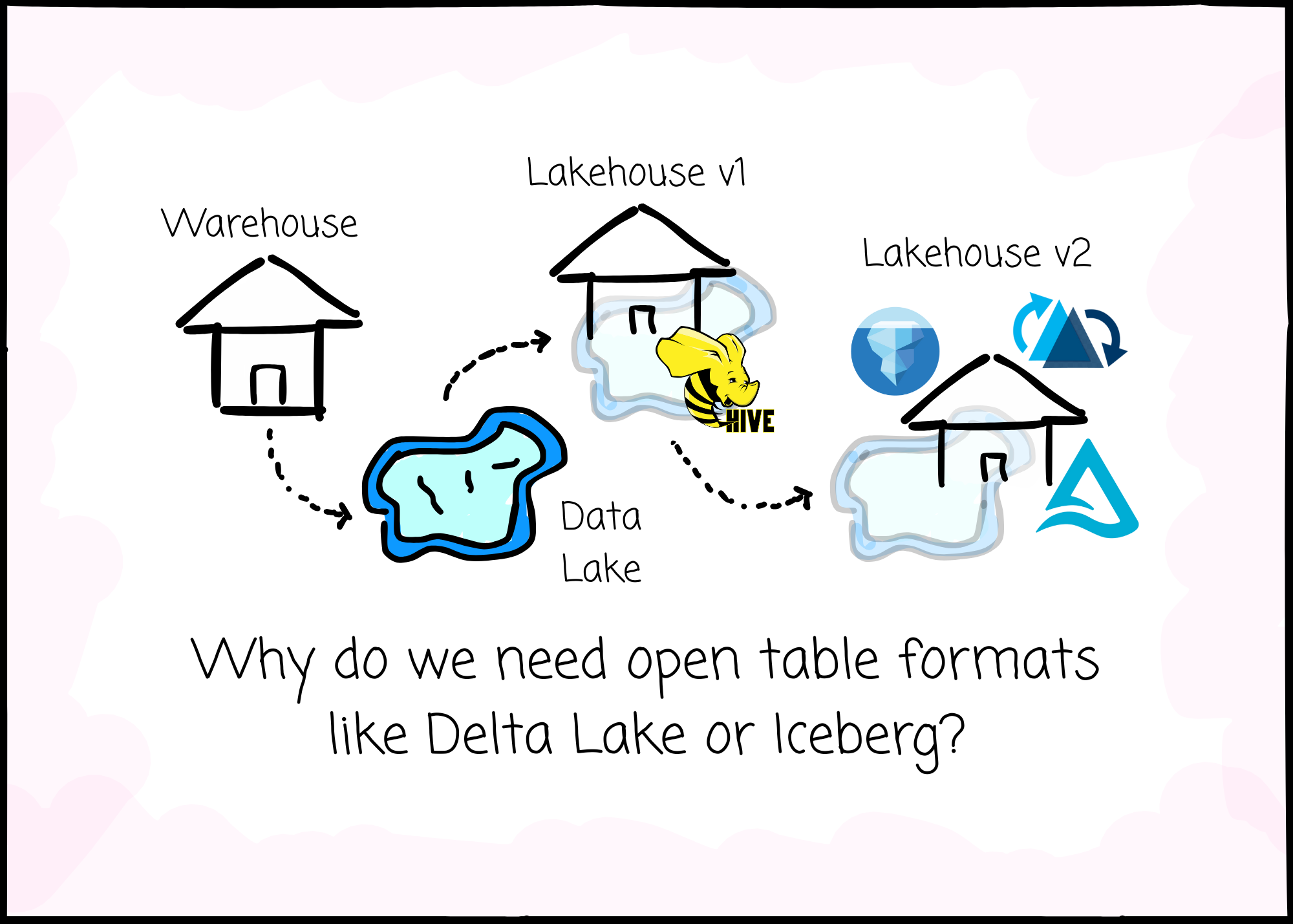
Why do we need open table formats like Delta Lake or Iceberg?
The hope of data lake + table format = data warehouse

To celebrate Lunar New Year (the true New Year holiday in Vietnam), I’m offering 50% off the annual subscription. The offer ends soon; grab it now to get full access to nearly 200 high-quality data engineering articles.
Intro
When I started self-learning for a data job 6 years ago, most resources on the Internet suggested that a data architecture should have two tiers, one to dump raw data to (the lake) and one to store clean data that’s ready for consumption (the warehouse)
Today, if you want to check the best approach to store, manage, and serve data, you still might see the two-tier architecture somewhere, but the one you start to see more and more is the lakehouse paradigm.
Following that are calls from nearly everywhere to equip yourself with the knowledge and hands-on experience of open table formats, the backbone of the lakehouse.
That makes me curious. Why?
I conducted a small research study, and this article is my note to answer the following questions: why the lakehouse is gaining popularity, and how the open table format, such as Delta Lake or Iceberg, fits into this story.
We will begin this article by learning the motivation behind the data warehouse, the data lake, and the lakehouse. Next, we examine Apache Hive and the emergence of modern table formats.
The data warehouse
Imagine a scenario like this.
You are the first member of the data team. Your boss asks you to create reports for the business team based on the data collected from the company's product.

At first, things are simple.

There is only one database that records transactional data; you extract data directly from it, do some transformation, and voilà.
Then, the company starts using a third-party service, and business users request data from this service to be included in reports. That’s still manageable.

You pull data from the database and the third-party API, perform some joins and aggregates, and you can still provide the reports users need.

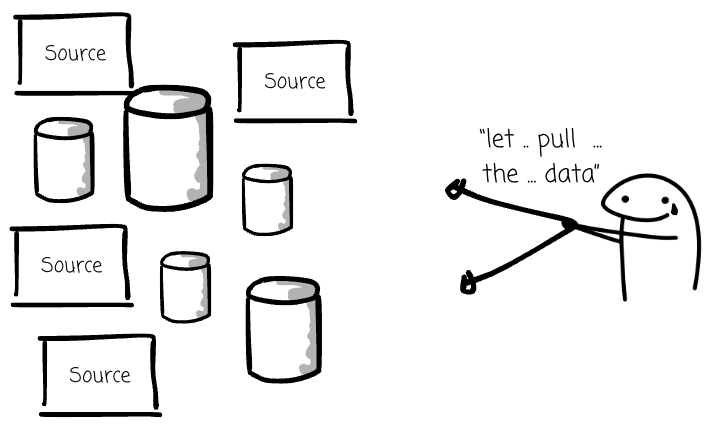
But over time, your company has more services and integrates with external tools, each generating its own data. End users want all this data incorporated into their reports.

At this point, you can't pull data from every source to compile the report like you used to. You need a more strategic approach. You need a data warehouse.
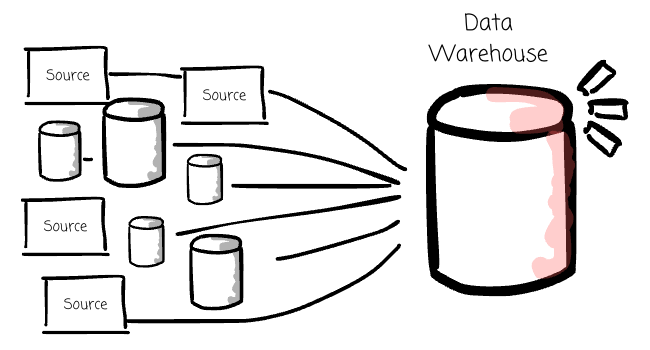
It is a repo where we can centralize, store, and manage large amounts of data from multiple data sources to serve the company's analytics workload.
Data is extracted from many sources, transformed into a predefined structure (schema-on-read), and loaded directly into the data warehouse. The data warehouse helps businesses and organizations manage data by providing a centralized repository for data storage and retrieval.
However, the data warehouse soon showed its limitations. Due to the rise of the Internet, the number of digital records has increased enormously. People realized they needed to collect, store, and process more data. Tabular data might not be enough; videos, documents, and images are also precious resources.
The data warehouse systems, primarily row-based relational databases at the time, did not readily adapt to the organization's needs. Data must be in a well-structured schema before loading into the warehouse. That’s caused an organizational problem: They still want a “single entry point“ for data management, but the data warehouse can’t handle unstructured data well.
The data lake
Let’s store all the data elsewhere.
To celebrate Lunar New Year (the true New Year holiday in Vietnam), I’m offering 50% off the annual subscription. The offer ends soon; grab it now to get full access to nearly 200 high-quality data engineering articles.
