
Is Your Data Valid? Why Bufstream Guarantees What Kafka Can't
Semantic validation with Bufstream, the drop-in Kafka replacement that puts a premium on data quality.

I will publish a paid article every Tuesday. I wrote these with one goal in mind: to offer my readers, whether they are feeling overwhelmed when beginning the journey or seeking a deeper understanding of the field, 15 minutes of practical lessons and insights on nearly everything related to data engineering.
Intro
Compared to 20 years ago, the way we ingest, process, and serve data has undergone significant changes.
We solved the storage problem by transitioning from local data servers to pay-as-you-go storage services that can adapt to nearly any use case.
We solved the processing problem by transitioning from the expensive MapReduce to more flexible options, such as Spark or cloud data warehouses like Databricks, Snowflake, or BigQuery.
However, a problem still remains: the quality of the data. Everybody knows about the garbage-in-garbage-out, how poor the model or reports are if low-quality data is entered. Still, preventing bad data is not an easy task. Data engineers are on the front lines of this challenge, tasked with not only moving massive volumes of data but also ensuring its integrity at every step.
Apache Kafka, thanks to its widely adopted protocol, has become the primary method for data ingestion to the data lake, particularly in an era when more companies recognize the value of streaming data.
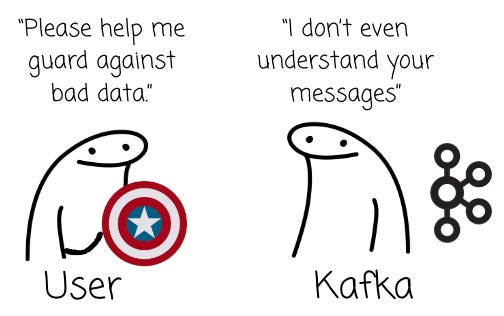
You might think: “So, data from the source is step 0, and entering Kafka is step 1. If we filter out the bad data from steps 0 to 1, we significantly improve the quality of the pipeline.”
I agree with that; invalid data must be rejected as soon as possible. So, let’s do this: let’s add a “security” layer in Kafka, and only good data can enter the pipeline.
Does it really?
In this article, we will first examine some significant data quality challenges associated with streaming data, particularly within the Kafka ecosystem: how Apache Kafka itself can’t act as the “security” layer and the inefficient client-data-validation with Confluent Schema Registry. It doesn’t stop there; the structure of the data, the schema, also faces challenges in its management.
Only after that will we try to find a better way to deal with all these problems.
Spoiler alert: It’s Bufstream.
The problems
How does Kafka see your data?
In the scope of this article, I won’t dive too much into Kafka’s architecture or how it works internally. For that purpose, you can read my previous article here: If you’re learning Kafka, this article is for you.
Kafka is popular because it provides an efficient way to decouple the sender of data (producers) from the receiver of data (consumers). The idea is straightforward: Messages are sent and persisted in the broker; the consumer contacts this broker to read the messages.

Engineers at LinkedIn built Kafka for high throughput. Several key decisions were made to support this choice, including exploiting the sequential access pattern, batching messages, and implementing zero-copy data transfer.
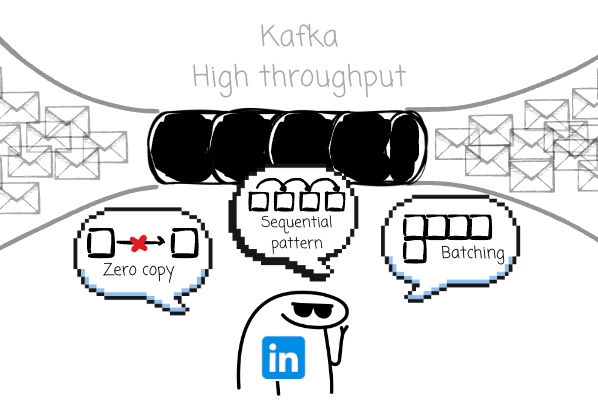
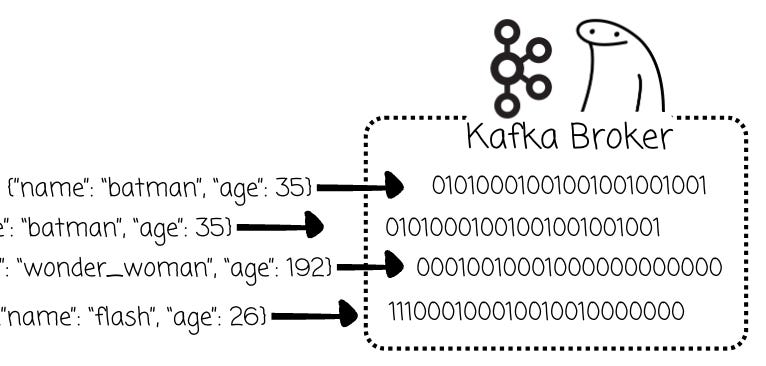
Besides that, I believe there is another decision that contributes to Kafka’s performance: the broker doesn’t need to understand your messages.
Kafka brokers see them as just an array of bytes. They will have less work to do; the responsibility for serialization and deserialization is left to the producers and consumers.
That’s great, until you actually need a Kafka broker to act as the gatekeeper for your data pipeline.
You expect all the messages to have five fields.
You expect the message’s field to have an integer value instead of a string.
Kafka brokers can’t do that. They can’t check whether your data follows a schema or not because all they see is a sequence of 0s and 1s.
The clients must do the validation
Therefore, data validation must occur outside of Kafka.
In the Kafka ecosystem, a component exists to help manage the schema of your messages. It is the Confluent Schema Registry (CSR), a centralized service that oversees and enforces data schemas for your Kafka topics, ensuring compatibility between producers and consumers. The producer and consumer must communicate with the registry (typically via a RESTful API) to verify that the messages comply with the schema.
Now you can enforce data validation for your messages; however, it must occur before the producers send them to the broker and after consumers read them.
On the producer side:
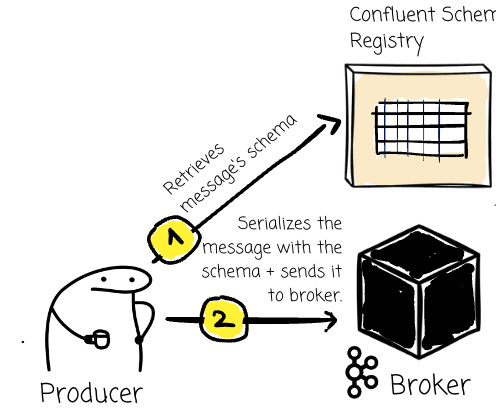
The producer will initiate two clients, one for the broker and one for the CSR.
The producer checks if the schema exists in the Registry. If it doesn’t, the producer sends a request to register it. (If auto-registration is enabled)
The Schema Registry returns the schema ID
The producer serializes the message with this ID.
It sends the message to the broker.
On the consumer side:
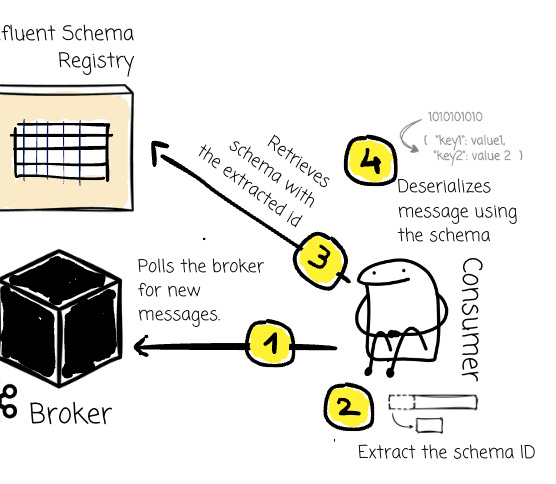
The consumer also initiates two clients.
The consumer polls the Kafka broker for new messages.
It parses the schema ID from the beginning of the message.
It then issues a request to the Registry with the ID to retrieve the schema.
The consumer deserializes the message according to the schema
Great, the problem is solved.
Until disaster happens.
First of all, the process involves humans. The clients (producers and consumers) are responsible for ensuring data validation. A senior engineer might forget to validate the data due to a strict deadline, and a new-hire may not even be aware of the need to do so.
If data governance is opt-in, it’s NOT data governance.
Plus, the client logic has become more complex. Setting aside how to publish and consume the messages most effectively, they must maintain the process of contacting the registry, retrieving the schema, and serializing/deserializing the messages—resulting in more lines of code and increased chances for inconsistency.
Compatible vs breaking schema changes
The challenges don’t stop at data validation.
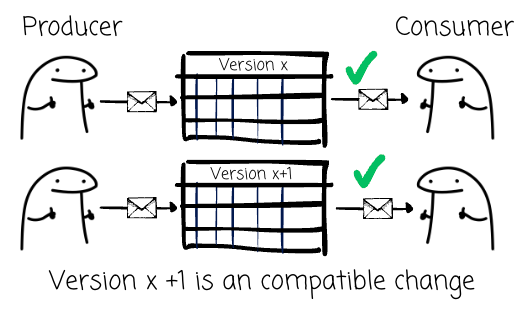
Don’t forget the structure of the data; the schema can change as the business evolves. Some changes allow you to proceed, while others could bring the entire system down. In the world of streaming, compatible schema changes are those that would enable producers and consumers to continue operating without any issues.
In contrast, breaking schema changes prevents either new or existing clients from successfully processing messages.
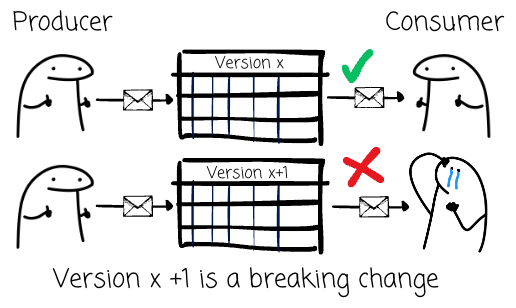
With the CSR, we can tell the schema registry to check the compatibility of the schema changes.
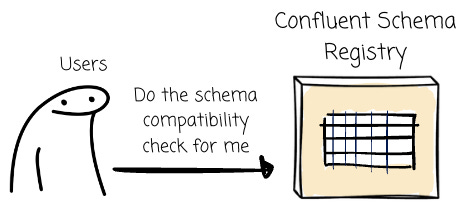
When a client attempts to register a new schema version, the Schema Registry verifies the proposed schema against the existing versions.
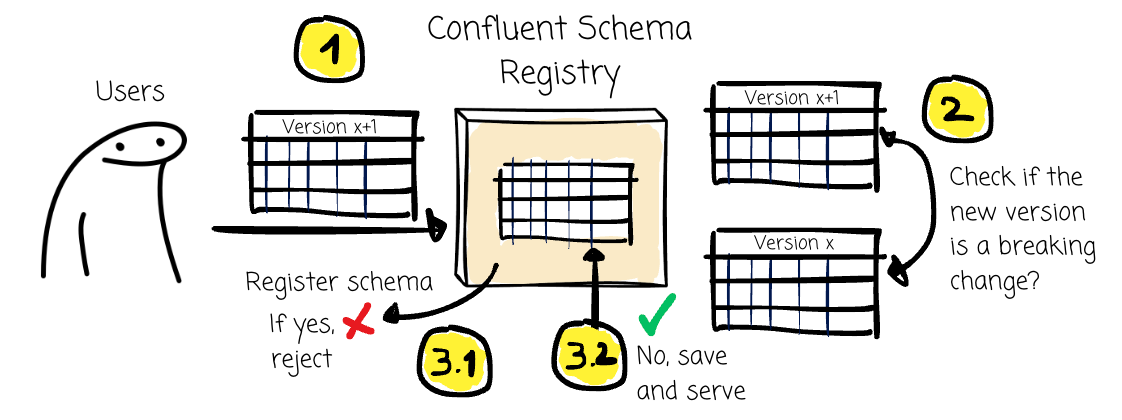
The downside of this approach is, again, that it involves the human factor. The users can opt to skip the compatibility check.
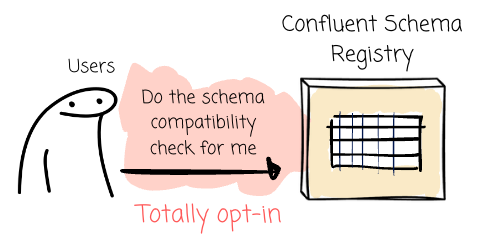
Additionally, the schema registry enables the client to register the schema automatically by default. This means that with a registry that has the compatibility check turned off, the producer can add schemas in any way they want, without any guardrails.
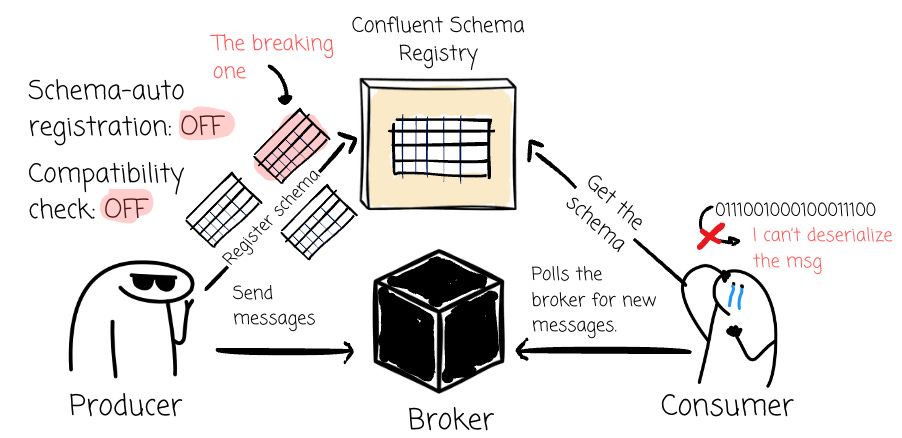
You can argue that that’s not going to happen; we are not amateurs when it comes to production environments. You’re right, we will be more cautious, but how do we ensure that the mistakes don’t happen?
You configure the registry at 2:00 AM
Your internal users urge you to fix the bug in 7 minutes
You have a bad day and lose focus.
Someone feels the compatibility check is annoying and decides to turn it off.
…
Breaking changes still manage to enter.
There are cases where Kafka’s administrators do their job most professionally; they instruct the registry to check for compatibility and reject the request to register the schema at runtime.
Still, the breaking schema manages to enter.
Assume you define a schema like this in Protobuf:
message SuperHero {
string hero_id = 1;
string power = 2;
string real_identity = 3;
uint32 age = 4;
}Each field has a field tag. The `hero_id` has the field tag 1, the `power` has field tag 2, and so on. Protobuf uses tag numbers, not the name, to identify fields.
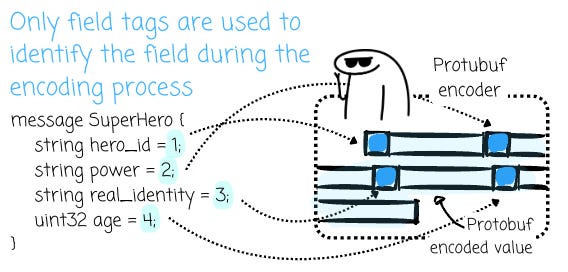
This means that if you change a field’s name, it still functions as intended, because the field never refers to its name.
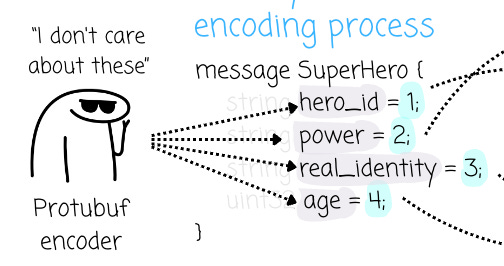
If you change the `power` to `super_power`, nothing will happen because the field tag remains 2. Imagine we register this schema with the registry, first with the `power` field name, then later register a new version with `super_power`. The compatibility check is passed because the process is based purely on how Protobuf leverages the field tag, rather than the field name.
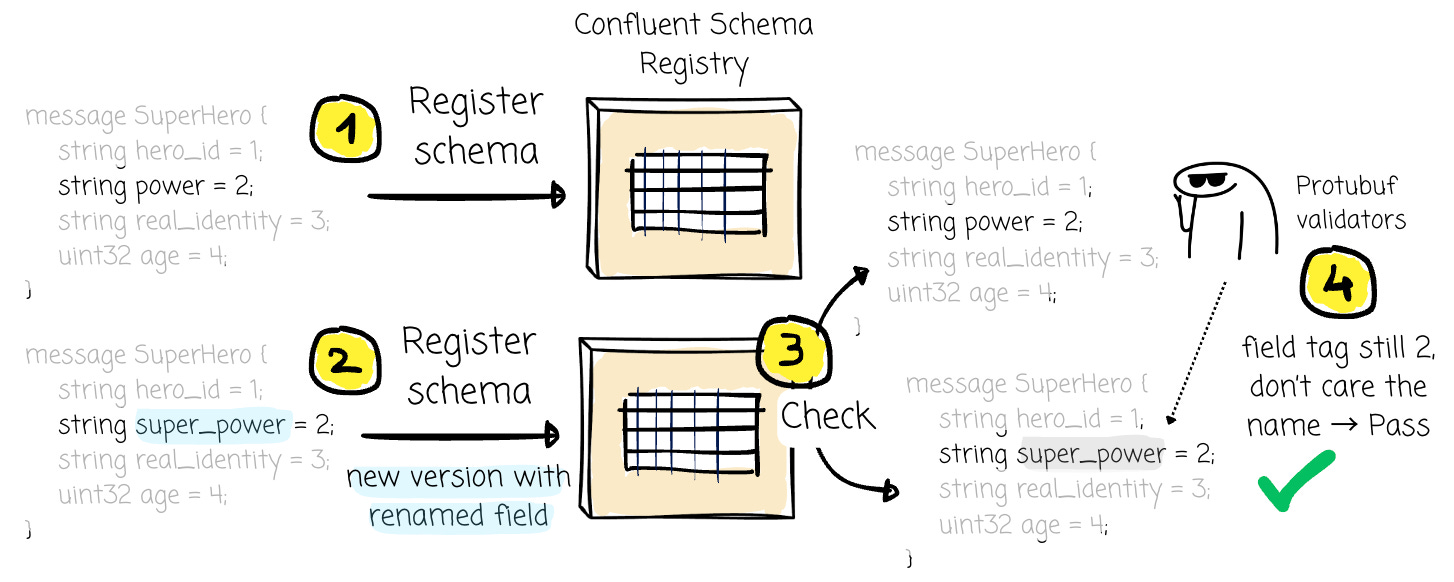
However, this does not always align with how the data is ultimately used. Protobuf data is widely mapped to JSON payloads for interoperability. Because the JSON representation relies on field names for keys, a consumer expecting the key `power` will fail to find it and instead encounter the new key “super_power”.
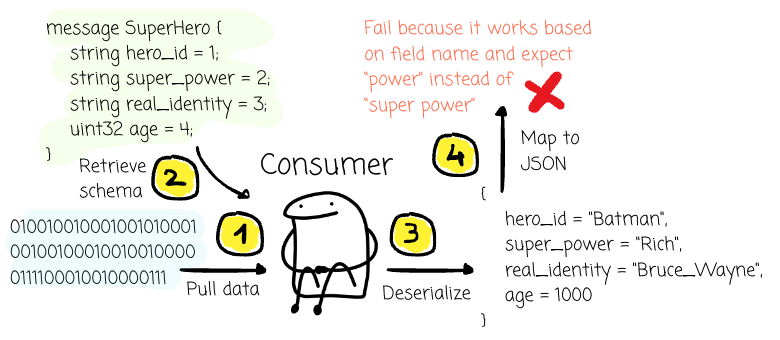
That’s how a schema that is considered passed by the compatibility check from the CSR can cause your whole pipeline to go down.
Bufstream
This is when Bufstream comes to the rescue.
Bufstream is built by Buf Technologies (often referred to as Buf). Buf is a software company founded in 2020 whose mission is to improve the developer experience and operational rigor of working with Protobuf and the gRPC ecosystem. One of the outstanding products from Buf is the Buf Schema Registry (BSR).
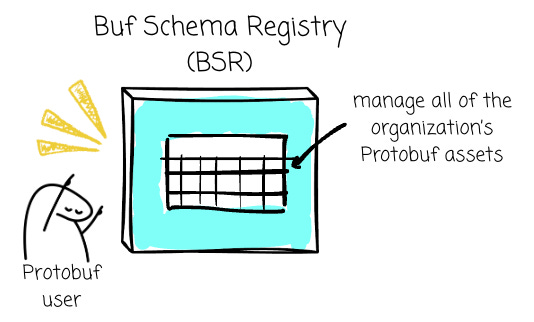
The BSR is a platform that serves as the single source of truth—the package manager and governance layer—for all of the organization’s Protobuf assets. It solves dependency sharing, enforces server-side policies, and provides automatic documentation and plugins.
As BSR grew, Buf saw more customers wanting these capabilities for data streaming use cases, specifically those sending Protobuf payloads over Kafka. These customers use Protobuf for Kafka’s message and leverage BSR to enforce field-level RBAC.
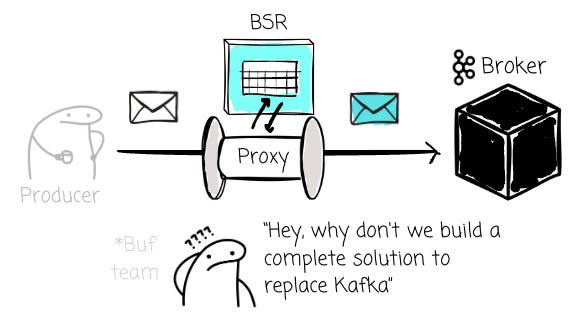
Initially, Buf only built a proxy that leveraged BSR to provide validation, automatic enveloping, and field-level RBAC for Kafka messages. During that time, object-store-based Kafka emerged (e.g., WarpStream, AutoMQ), and they realized they could offer a more complete solution.
Buf built Bufstream, a cost-effective Kafka drop-in replacement that offloads data to object storage, transforms your Kafka messages into Iceberg tables without a separate ETL pipeline, and, more importantly, solves the quality issues of streaming data.
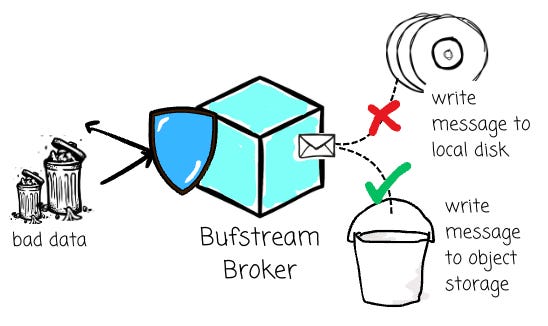
In the scope of this article, I won’t go into the details of Bufstream. To learn more about this solution, I wrote a deep-dive article here: Bufstream: Stream Kafka Messages to Iceberg Tables in Minutes. This article instead focuses on the approach that Bufstream takes to ensure data quality.
Before examining how Bufstream does that, let’s first take a look at Protobuf.
Protobuf
Developed by Google, Protobuf is an extensible, language-neutral, and efficient mechanism for serializing data.
Unlike JSON, which is a text-based and human-readable format, Protobuf serializes data into a highly compact binary format with the help of a predefined schema in language-agnostic .proto files. As mentioned, it uses unique, numbered field tags instead of verbose field names to identify fields, thereby saving significant space.
Relying on the field tags allows the Protobuf schema to be evolved quite flexibly. Adding fields is straightforward, as older code will ignore the new field number when deserializing (forward compatibility). Fields being deleted must reserve their field number to prevent its reuse, ensuring that old data can still be parsed by new code (backward compatibility).
With extensive experience working with Protobuf, Buf believes it is the right choice to represent Kafka messages. Compared to a text-based format like JSON, Protobuf is more performant. Avro is a strong candidate too; however, Buf sees that the format is less widely adopted outside the big-data world compared to Protobuf.
Broker-side schema awareness
With the introduction of Bufstream, the BSR is also leveraged to provide a Protobuf-first implementation of the Confluent Schema Registry (CSR) API, making Protobuf an enterprise-ready format for high-throughput streaming systems. With the latest release of Bufstream, things get simpler as you can directly use BSR without the CSR API.
It does not mean Bufstream allows only Protobuf, as I know they’re working to support Avro and JSON. However, as discussed, Protobuf is recommended in Bufstream.
Compared to Kafka, Bufstream takes a different approach by shifting the responsibility for validating the data to the broker. When a producer sends a message to the broker, it can reject messages that don’t match the topic’s schema. The schema is retrieved via any schema that implements the Confluent Schema Registry API, including the Buf Schema Registry (BSR).
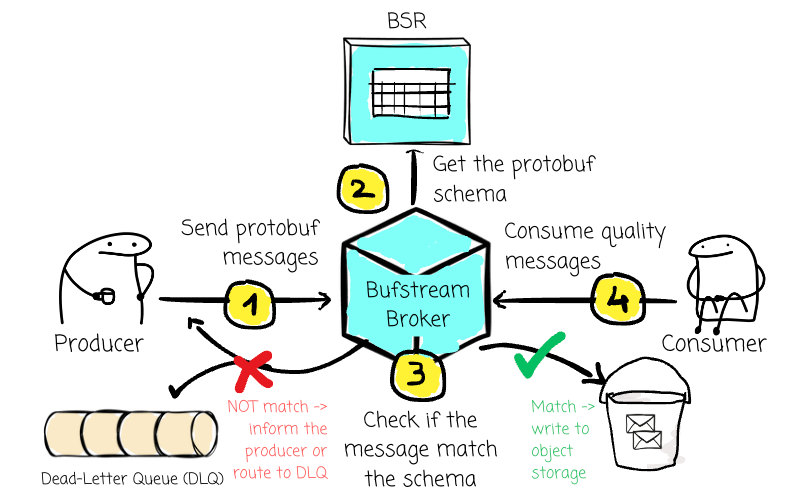
The clients can now focus more on sending and receiving messages. No more complex logic of data validation; no one will ever forget to perform the validation check because they no longer need to.
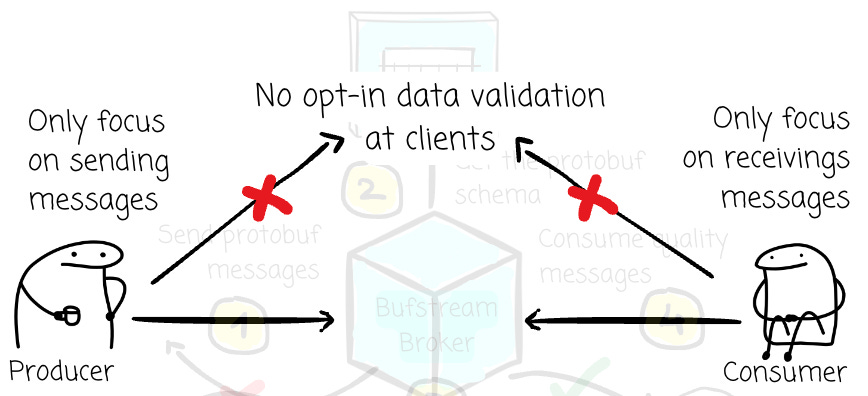
Yes, the brokers now have more work to do because it consumes more CPU, as it needs to understand the messages. The latency and throughput might be affected slightly, but it is a bargain given the simplicity and robustness that Bufstream can provide to end users.
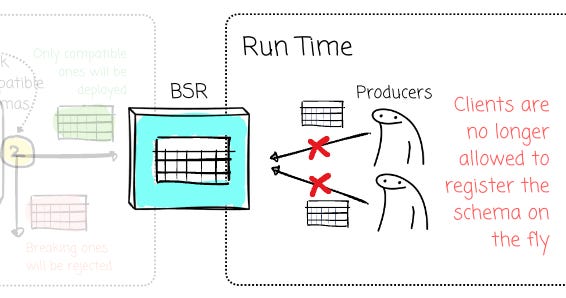
No schema changes at run time
Recall that producers can register a new breaking-change schema? This risk exists essentially because of a simple reason: things can be changed at runtime.
To address this, Bufstream adheres to a reliable yet straightforward practice: changes should only be made at build time, after ensuring they are safe to exist in the production environment.
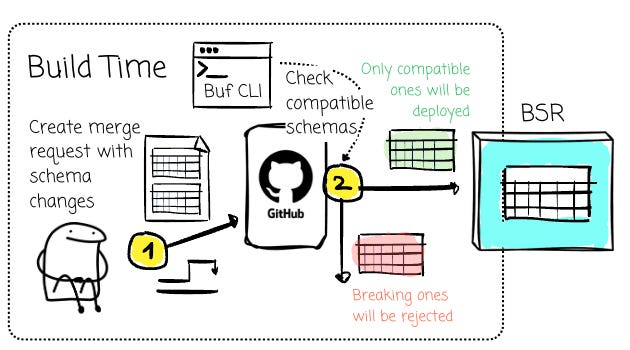
Bufstream no longer allows clients to register the schema on the fly. All changes must follow a typical software development process: you update the schema, push to the version control system, create a merge request, and the CI/CD pipeline kicks in; only compatible schemas will be deployed.
This is where the Buf CLI truly shines, offering the ability to efficiently detect breaking changes in Protobuf schemas. You can ensure that, when the `buf breaking` doesn’t return any errors, no breaking schema will enter the BSR.
The Buf CLI is designed to professionalize the local Protobuf development workflow. It unifies a series of fragmented tools into a single, high-performance binary with numerous features, including Protobuf compilation, linting, and the ability to validate Protobuf schema changes against previous versions.
Buf pioneered breaking change detection for Protobuf before Google even considered it. They promise to cover every edge case.
Less flexibility for the schema registering process, but far more reliability for your pipeline.
The semantic meaning of your data
All the things we just discussed focus only on the structure of the data. The schema of the data is indeed essential; however, it is not the whole story. In fact, there are generally three levels of validation: the schema ID, the schema, and semantic validation.
Schema ID validation
This is the most basic level of validation. In “Confluent Wire Format”, Kafka messages traveling across the wire start with a Magic Byte (byte 0), followed by a 4-byte Schema ID (bytes 1-4), and then the actual Payload (byte 5 onwards).
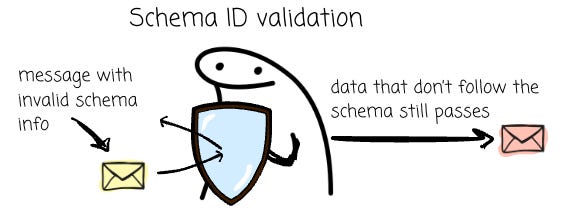
Schema ID validation only checks if the 4-byte ID is an existing, valid schema identifier in the schema registry. It does not verify the actual data payload and does not care if the payload is a valid encoding for the schema identified by the ID.
Schema validation
This is the level we discussed the most in this article. It validates that the payload is a valid encoding of the specified schema. If the schema expects a field to be an `integer`, it will pass if the field is an integer; if a producer tries to put a string value for that field, the validation process will reject this message.
Semantic validation
Schema validation the most comprehensive and complete method for validating data. It helps you with missing fields and incorrect data types.
What if there are cases where you expect an `integer`, one ingests an `integer`, and it is still bad data?
Back to the SuperHero example above:
message SuperHero {
string hero_id = 1;
string power = 2;
string real_identity = 3;
uint32 age = 4;
}A record comes in:
{
hero_id = "Batman",
power = "Rich",
real_identity = "Bruce_Wayne",
age = 1000
}“Batman” is a string. Check. “Rich” is a string. Check
“Bruce_Wayne” is a string. Check. 1000 is an integer. Check
Wait. Does Bruce Wayne live to be 1000 years old?
That question can’t be answered by simply validating the schema, as you can see, it passes the check; nothing was wrong, 1000 is still an integer. A separate process must be implemented to address this problem.

This is when we need semantic validation, as it checks both structure and business logic. Data must adhere to both the predefined schema and the business rules; for instance, a human can’t live longer than 200 years, an email should include an ‘@’ symbol, and the `id` field must be in a valid UUID format.
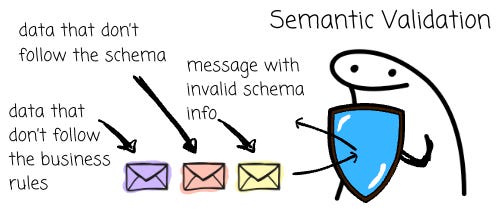
Bufstream provides semantic validation. Besides broker-schema awareness and preventing schema changes at runtime to ensure schema ID and schema validation, users can leverage Protovalidate. This library allows developers to annotate Protobuf schemas with hundreds of supported rules. Protovalidate also enables you to customize your rule to fit your organization’s specific needs.
All rules in Protovalidate are defined in CEL (Common Expression Language), an open-source expression language designed by Google to be safe, fast, and portable. Custom rules are simply rules where users write their own CEL expressions. They can register these as their own extensions and use them as predefined rules later.
The SuperHero example above is now added with a business rule like this:
message SuperHero {
string hero_id = 1 [(buf.validate.field).string.uuid = true];
string power = 2;
string real_identity = 3;
uint32 age = 4; [(buf.validate.field).uint32.gte = 1, (buf.validate.field).uint32.lte = 200];
}After defining your rules, Bufstream can now perform broker-side semantic validation using Protovalidate. Breaking schemas will never enter, and only code-reviewed, compatible schemas will be shipped. Bufstream performs broker-side schema validation and understands the schema of each topic, so it’s impossible to send bad data to your topic.
“But I heard Confluent Schema Registry also supports semantic validation”
You might say, Confluent Schema Registry also supports message semantic validation. Yeah, you’re right, you can check if Batman can live longer than 200 years. However, the limitation comes down to the design of Kafka here: Kafka doesn’t understand your messages, so validation must be handled by the client, even the semantic validation.
Great, again, clients have even more work to do, besides checking if the data has a valid schema; producers now need to check the data against the business rules. Again, the story will be the same, as it involves the human factor:
Producers and consumers can forget and bypass the validation steps because, essentially, the process is opt-in.
The clients configure the semantic validation using a plugin that can be easily misconfigured.
Not every client can do semantic validation. Only Java clients are supported. Python, Go, Node, and other clients can’t do that.
It is worth reiterating that opt-in data validation at the client side does not mean true validation.
Some of my thoughts
The most effective way to prevent bad data from flowing through your pipeline is to address it in the very first steps. The solution that enables efficient data exchange between systems, such as Apache Kafka, is a good starting point for our data-quality checking process.
However, Kafka wasn’t built with this concern in mind. It doesn’t understand your data, so the validation process must happen outside the brokers. The integration between clients and the schema registry surely brings complexity and unreliability.
Bufstream, a cost-effective Kafka replacement, aims to address this exact problem. The broker validation, blocking schema changes at runtime, and the semantic validation feature are all built on the principle of treating data quality as a first-class citizen, alongside the robust ecosystem surrounding the Protobuf format.
I think it’s time for us to take the quality of the data more seriously and ensure that every data record meets the standards we expect. And if you run into the data quality issues with Kafka, you know where to look—Bufstream.
Outro
In this article, we revisit how Kafka interprets our messages to understand why the data validation process must occur outside the broker. Next, we examine issues that still happen with Kafka and Schema Registry integration.
From the defined problems, we move on to discover a solution that promises to do better: Bufstream. Unlike Kafka, Bufstream leaves the data validation job to the brokers; clients can’t register the schema at run time. The semantic validation also enables you to ensure that data adheres to your defined business rules and constraints.
Thank you for reading this far. See you in my next article.
Reference
[1] Gwen Shapira, Todd Palino, Rajini Sivaram, Krit Petty, Kafka The Definitive Guide Real-Time Data and Stream Processing at Scale (2021)
[2] Confluent, Schema Registry Clients in Action (2024)
[3] Scott Haines, Streaming data quality is broken. Semantic validation is the solution (2025)
[4] Team Buf, Cheap Kafka is cool. Schema-driven development with Kafka is cooler (2025)
This piece really made me think. Consistent, sharp data analysis.
> Not every client can do semantic validation. Only Java clients are supported. Python, Go, Node, and other clients can’t do that.
Correction: semantic validation is currently supported in Confluent Schema Registry clients for Java, Python, Go, Node, C# and C++.