
Bufstream: Stream Kafka Messages to Iceberg Tables in Minutes
8x cheaper than Kafka + native support for data quality and seamless transformation of Kafka topics into Iceberg tables.

I’m making my life less dull by spending time learning and researching “how it works“ in the data engineering field.
Here is a place where I share everything I’ve learned. Not subscribe yet? Here you go:
Intro
Nearly 50,000 companies use Apache Kafka.
Fourteen years ago, a team led by Jay Kreps built Kafka to meet LinkedIn's growing log processing demands. Since its open-source release, Kafka has become the de facto standard for distributed messaging.
But here’s the catch: Kafka’s design isn’t optimized for the cloud era. Compute and storage can’t scale independently, cross-availability-zone transfer fees due to data replication, and other challenges persist whether you run Kafka locally or in the cloud.
Data quality concerns: Kafka brokers treat messages as raw byte sequences, leaving schema validation up to producers and consumers. If someone skips this step, downstream systems suffer.
Pipeline complexity: Once data lands in a Kafka topic, you need an entire pipeline to move it to a data lake before analytics engines can query it.
What if there were a solution that helped you manage Kafka more efficiently in the cloud, ensured data quality, and transformed Kafka messages into an Iceberg table in just a few minutes?
Today, we explore Bufstream—the solution that promises all of this.
A bit of Kafka
Kafka achieves high throughput by leveraging a page cache and a sequential disk access pattern. It simplifies the system by relying on the OS for storage management; all read and write operations must pass through the page cache.

This tightly coupled design means that scaling storage requires adding more machines, often leading to inefficient resource usage. To address this limitation, Uber proposed Kafka Tiered Storage (KIP-405), introducing a two-tiered storage system:

Local storage (broker disk) stores the most recent data.
Remote storage (HDFS/S3/GCS) stores historical data.
However, brokers are not entirely stateless.
Kafka's design also relies on replication for message durability. Each Kafka partition has a single leader and zero or more followers (those storing replicas). All writes must go to the partition’s leader, and reads can be served by a leader or the partition's followers.
When the producer writes messages to the leader, the leader replicates them to followers. This helps Kafka to fail over other replicas when a broker fails. Because Kafka storage and compute are tightly coupled, any change in cluster membership forces data to move around the network.

However, Kafka's design becomes less efficient when operating in the cloud:
It can’t fully leverage the cloud's pay-as-you-go pricing model, as computing and storage cannot be scaled independently.
It can incur significant cross-availability-zone (AZ) data transfer fees because messages are replicated across different AZs.
That’s why many solutions are emerging to offer a cloud-native alternative to Kafka, and Bufstream stands out as a compelling contender.
Bufstream
The motivation
Bufstream was developed by Buf, a software company founded in 2020 to bring schema-driven development to the world via Protobuf and gRPC for many companies.
Protocol Buffers (Protobuf) is an efficient binary serialization format developed by Google. Unlike JSON, Protobuf enforces strict schemas using .proto files, where fields are assigned unique numbers for efficient encoding. It supports schema evolution by allowing new fields to be added without breaking existing consumers, ensuring backward and forward compatibility.
Buf has been building the Buf Schema Registry (BSR), the complete Protobuf schema registry, and a robust Protobuf package manager. As BSR grew, Buf saw more customers wanting these capabilities for data streaming use cases, specifically customers sending Protobuf payloads over Kafka.
These customers wanted to tie Kafka topics to specific Protobuf message formats, enable broker-side validation, automatically envelop raw data, and leverage BSR’s support for custom Protobuf options to enforce field-level RBAC at the gateway.
At first, Buf only built the Buf Kafka Gateway, a Kafka proxy that leveraged BSR to provide validation, automatic enveloping, and field-level RBAC. As Buf developed the gateway, object-store-based Kafka emerged (e.g., WarpStream, AutoMQ).
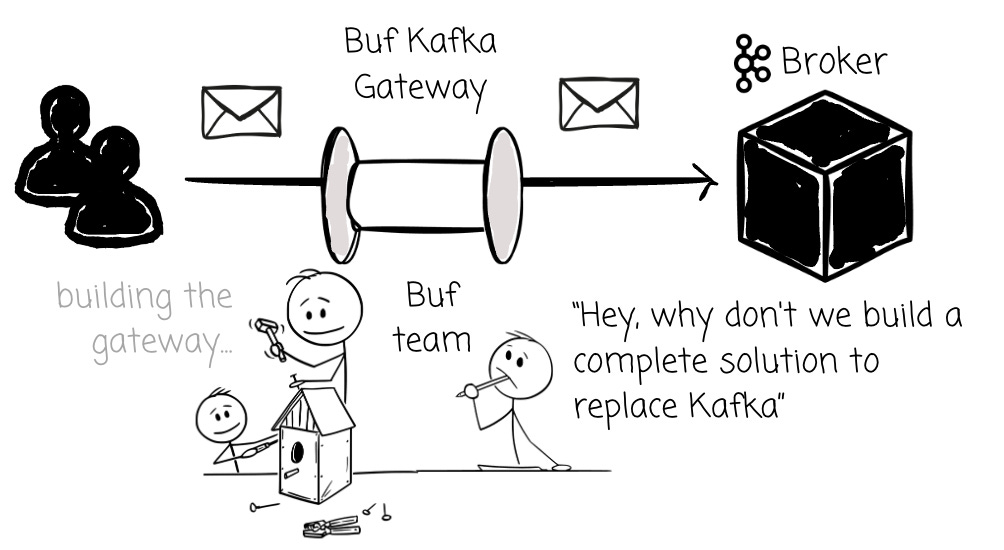
Realizing they could offer an end-to-end solution, they built a Kafka-compatible message queue with native support for features like directly writing Iceberg tables to S3 while bringing the same reliability and developer experience to data streaming as they did with Protobuf and gRPC.
The result was Bufstream, an enterprise-grade, object storage-based Kafka-compatible message queue verified by Jepsen.
Jepsen is the gold standard for distributed systems testing, and Bufstream is the only cloud-native Kafka implementation that has been independently tested by Jepsen.
But how is Bufstream different as a Kafka replacement?
Replacing local disks with object storage
Buf designed Bufstream from scratch to ensure 100% Kafka compatibility while storing all data in object storage. For the Kafka protocol, Bufstream supports the latest version of each Kafka API (as of Kafka 3.7.1) while striving to maintain compatibility with all previous endpoint versions.
For the storage, instead of writing to a local disk, Bufstream now writes directly to object storage like AWS S3, Google Cloud Storage, or Azure Blog Storage, allowing these services to be in charge of data durability and availability.

Unlike the tiered storage approach, which maintains local and remote storage, Bufstream stores messages entirely in the object storage. This allows users to scale computing and storage independently. Need more computing power? Add RAM and CPUs. Need more storage? Object storage enables you to expand capacity without limits (except for your budget.)
With the same setup of a single topic with 288 partitions, 1 GiB/s of symmetric reads and writes, and a 7-day data retention period on both Kafka on AWS and Bufstream, the Kafka cluster's EBS volumes cost $42,025 per month. For the Bufstream storage, it only costs $4,625 per month. The cost savings are mainly due to:
Object storage is cheaper than disk media like AWS EBS.
The actual data stored in Bufstream is smaller than Kafka because it doesn’t need to replicate the data between brokers.
With object storage, here is a typical message-writing process of Bufstream:
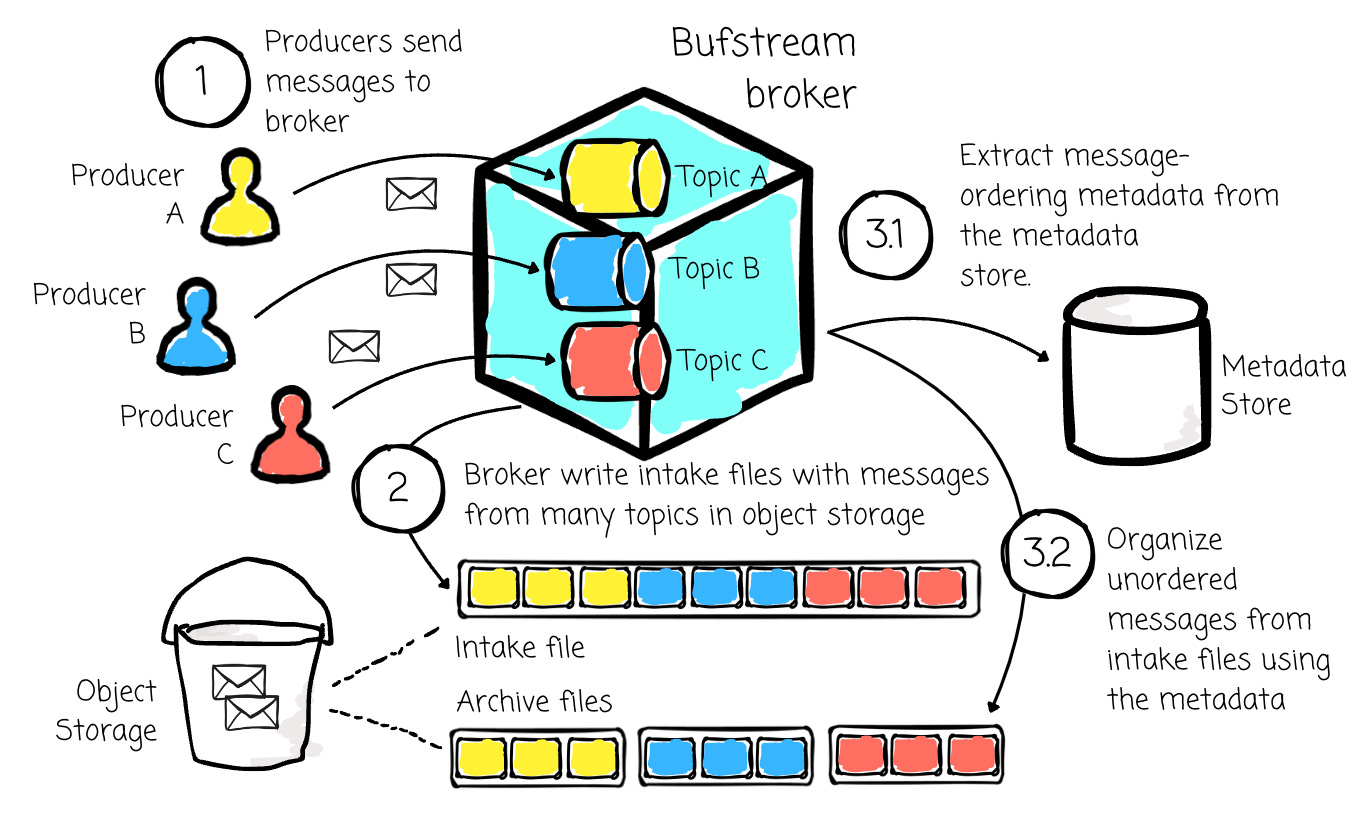
Brokers write messages into the object storage as intake files and acknowledge the write to the producers.
Intake files include messages from many topics and partitions and are grouped according to a time boundary.
This message batching can help reduce the cost of writing for a single partition.
Bufstream has a background process to organize unordered messages from intake files into archives files with the help of message-ordering metadata from the metadata store, which can be etcd, Postgres, Google Spanner,…
Reducing the cross-availability zone transfer fee
The benefit of leveraging object storage does not stop there.
According to Confluent, cross-AZ replication can account for more than 50% of total infrastructure costs when self-managing Apache Kafka, making it a significant financial consideration for cloud deployments.
In the same benchmark above, the Kafka setup requires users to pay $34,732 monthly for the cross-availability zone transfer fee, three times the cost of the Bufstream clusters.

This high cost is primarily driven by:
Kafka producers must always write to the partition leader. If a Kafka cluster spans the leader partition into three availability zones, producers will write to a leader in a different zone approximately two-thirds of the time.
The leader replicates the data to brokers in the other two availability zones.
With Bufstream, the cross-availability zone transfer fee is only $226 due to the metadata communication; this huge saving is mainly because:
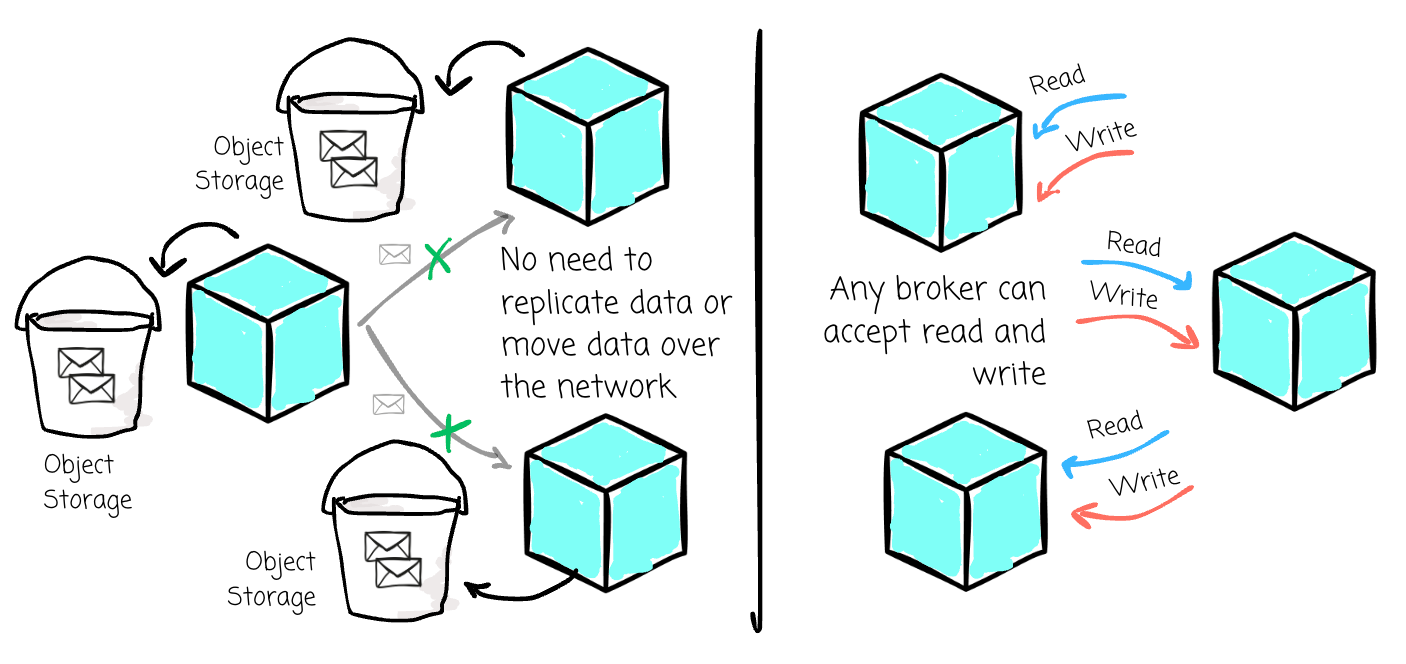
Bufstream stores data in object storage and lets it ensure data durability; It doesn’t need to replicate data like Kafka.
Bufstream brokers are stateless. When adding and removing brokers, data doesn’t need to be moved over the network like Kafka. Instead, it only needs to update the metadata that maps the brokers and partitions in the object storage.
Bufstream brokers are leaderless; any broker can serve read and write. To limit cross-availability zone traffic, Bufstream uses flags to identify the client’s availability zone (AZ) and returns only brokers within that AZ during service discovery, avoiding cross-zone data transfer.
Deployment
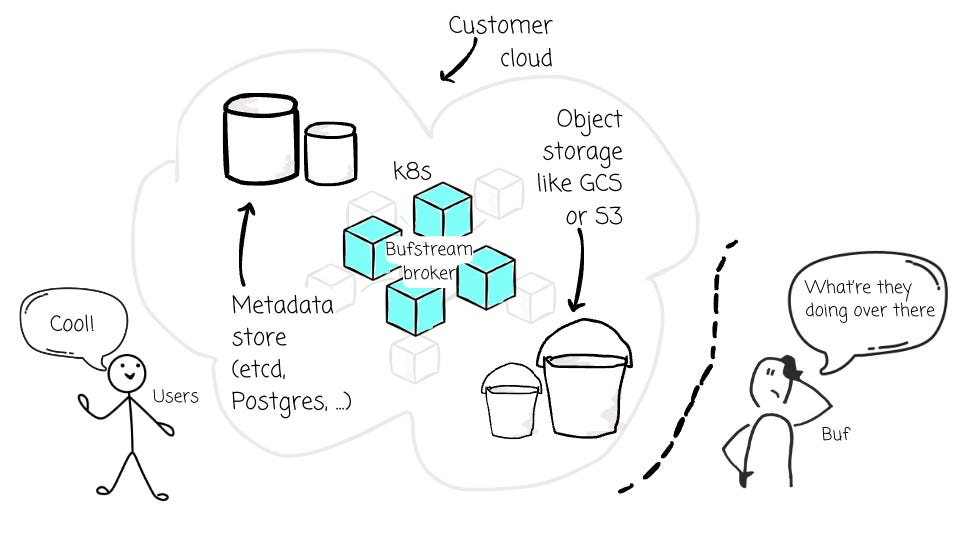
Deploying Bufstream is straightforward. All you need is a Helm chart, and you’re good to go; Bufstream grants the customer complete control over the deployment. While WarpStream claims data sovereignty via BYOC, they lets users secure data within their private VPC but still requires routing metadata back to the WarpStream Cloud. With Bufstream, no data is sent back to Buf. A Bufstream deployment is entirely within a customers’ VPC.
For a typical Bufstream deployment, you only need the following tech stack:
A Kubernetes cluster
Object storage (S3, GCS, or Azure Blob Storage)
A metadata store (Etcd, PostgreSQL, Google Cloud Spanner, or AWS Aurora)
Pricing
So, we've explored Bufstream as a much cheaper alternative to Kafka, but how does its pricing model work?
It’s straightforward: $0.002 per uncompressed GiB written (about $2 per TiB).
Stanislav Kozlovski, a Kafka expert and writer, gives some juicy numbers for the setups to achieve 256 MiB/s throughput, 7-day retention, 4x compression, and 1GiB uncompressed:
A Kafka setup costs $1,077,922
A Kafka-optimized setup costs $554,958. It has tiered storage and allows the consumer to fetch data from followers to save a cross-AZ transfer fee.
A Bufstream setup costs only $128,136, less than 8.4 times compared to the Kafka setup and less than 4.3 times compared to the optimized setup.
As Stanislav confidently said, Bufstream is the lowest-cost Kafka-replaced solution on the market.
Ensuring data quality
In addition to cutting costs, Bufstream provides first-class schema support at the broker level to help users with data quality issues. Before discovering how Bufstream can help, let’s understand how users perform data quality checks in Kafka.
Kafka sees your message as just an array of bytes. It has no clue if you tell the broker to check if a message has all expected fields or if a field has a string value instead of an integer.
The schema validation process must occur outside the brokers with the help of the Schema Registry, a centralized service that manages and enforces data schemas for Kafka topics, ensuring consistency and compatibility between producers and consumers.
The Schema Registry operates independently of the Kafka brokers and interacts with producers and consumers through a RESTful API. The topic schemas are stored and referenced by unique schema IDs. A typical process is:

The producer has two client instances, one for the Kafka cluster and another for the Schema Registry.
The producer checks whether the schema is already in the Schema Registry. If it doesn't, the producer sends a POST request to register it.
The producer retrieves the schema ID from the Schema Registry.
The producer serializes the message with the schema ID and sends the serialized message to the Kafka broker.
The consumer also has two client instances, one for the Kafka cluster and another for the Schema Registry.
The consumer polls the Kafka broker for new messages.
It extracts the schema ID from the first few bytes of the serialized message.
It then sends a GET request to the Schema Registry, using the schema ID, to retrieve the schema.
The consumer deserializes the message according to the schema, converting the binary data to its original format.
There are some problems:
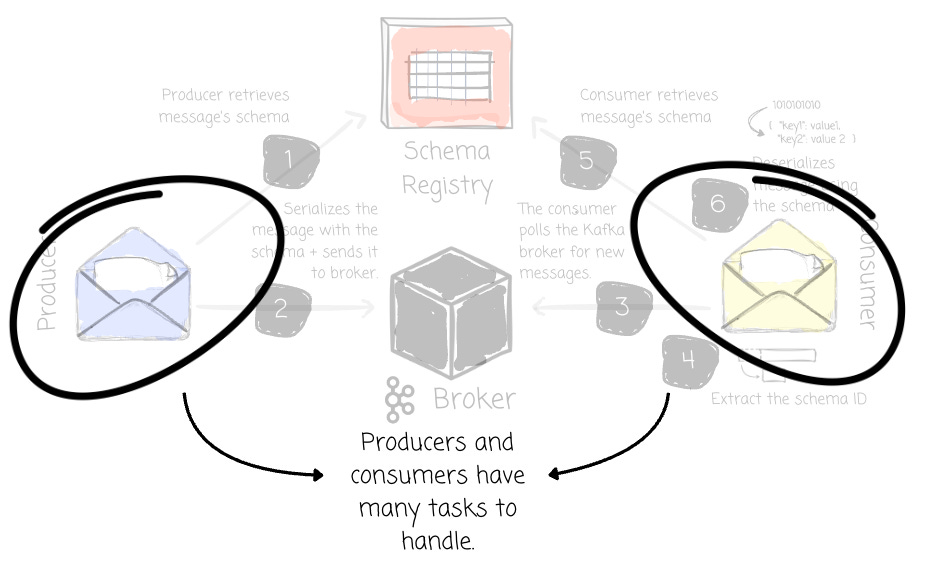
A misconfigured producer can send malformed or unregistered messages.
Bad data can still enter the system if a producer forgets to validate the schema.
The producer and consumer clients become thick. They must handle the schema validation logic, which increases code complexity, dependency management issues, and inconsistency across teams.
Bufstream takes a different approach when treating schema as the first-class citizen with Protobuf messages in both the binary format and the ProtoJSON format. Buf is working to support Avro and JSON messages in the future.
The broker can check and reject messages that don't match the topic's schema. It achieves this by integrating with any schema registry that implements the Confluent Schema Registry API, including the Confluent Schema Registry itself and the Buf Schema Registry (BSR). This Schema Registry serves as a single source of truth for all the Protobuf assets, including the .proto files that define the data schema.
Whenever the Bufstream broker receives a Protobuf message from the producer, it checks whether the message’s schema matches the topic schema defined in the BSR. If yes, the broker accepts the message and prepares for the upcoming write to the object storage. If not, it rejects the message and informs the producer.

In Kafka, client-side validation isn’t really validation; clients opt-in to do that. A trusted, centralized validation point is needed, which, in this case, is the broker. Since all clients connect to the broker, validation can be enforced there. Relying on client-side validation is risky because clients can simply skip it.
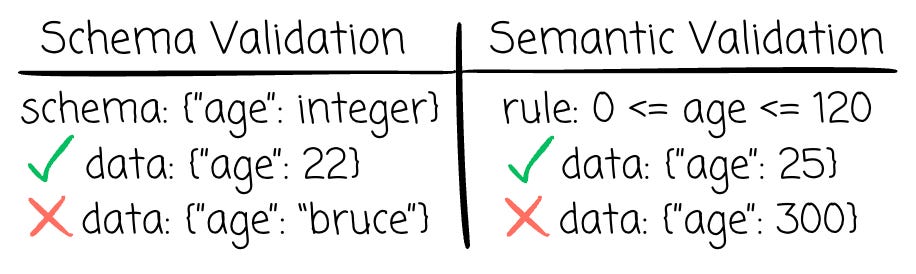
Additionally, Bufstream can offer a more robust way to ensure data quality; although the schema validation process can help prevent bad data, it is sometimes insufficient.
You expect the “age” field to be an integer, but what if the field with 350 arrives?
You expect the “email“ field to be a string, but what if the field “abc“ arrives?
Schema validation can not find the unusual here. Bufstream lets you implement semantic validation of Protobuf messages at runtime based on user-defined validation rules. For example, an age field must have a value from 0 to 120, or an email must have an “@.”
Beyond data quality, Bufstream provides granular access control, allowing on-the-fly Protobuf redaction and exposing some fields to consumers. Currently, this logic is static, but Buf plans to introduce field-level RBAC, enabling producers to tag sensitive fields in Protobuf schemas; consumers will only receive authorized data.
Kafka topic → Iceberg table
Suppose we want to execute analytics on Kafka messages, such as ad-hoc exploration or reporting. We must build a pipeline with Kafka Connect, Spark, or Flink to consume messages from the Kafka topic, write them into files, and push these files to the data lake.
We have to take care of everything from managing the pipeline to ensuring the physical layout of the files is optimized for downstream consumption (e.g., too many small files can hurt the read operations)

Since Bufstream already stores the topic’s messages in object storage, it transforms data in transit to rest in S3 as Parquet files with Iceberg metadata on top. Users don’t have to deploy, monitor, or manage a dedicated data pipeline. Bufstream will handle all that. With schema awareness, Bufstream can synchronously update the user's iceberg catalog to notify them of field changes or new files.
Here’s an interesting point: the way Bufstream stores the Iceberg table is very unique. Other systems, such as Tableflow from Confluent, promise to write Kafka messages to an Iceberg table by reading Kafka data and copying it over, thereby duplicating data for two different purposes—serving consumers and handling analytics workloads. In contrast, Bufstream only stores the Iceberg tables.

Remember the Bufstream message-writing process mentioned above? Initially, it writes messages into intake files and later rewrites them into archive files. With Iceberg integrations, Bufstream will rewrite the intake files directly into Iceberg tables. It uses the Iceberg table for both Kafka and the lakehouse storage layer. The query engine can tap into this layer to process data, while the broker will read data from these Iceberg tables and return it row by row to consumers when they poll for messages.
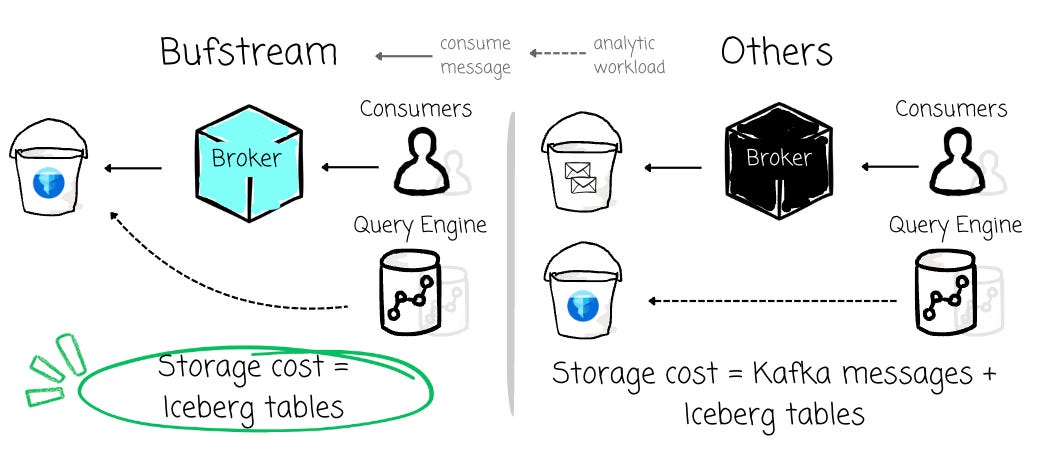
Using the Iceberg table as a 2-for-1 solution like this can lead to massive storage savings. With this Bufstream feature, users can reuse the storage already allocated for Iceberg tables in the lakehouse, effectively eliminating the cost of Kafka storage altogether.
With support for popular Iceberg catalogs like REST Catalog, BigQuery Metastore, and upcoming support for Databricks Unity Catalog, Snowflake Polaris, and AWS Glue, you can seamlessly use any Iceberg-compatible query engine to access Iceberg tables from Bufstream.
Here is a process of transforming Kafka messages into an Iceberg table from Bufstream:

With Iceberg integration, the user needs to specify the archive format is
iceberg.First, the writer contacts the BSR to fetch the latest schema and caches it in memory for later use with the same topic messages.
The writer uses this schema to form the Iceberg table schema. To handle schema evolution, Bufstream keeps the Iceberg schema state in the metadata store.
After the writer forms the schema, it talks to the Iceberg catalog to check if it has changed. If yes, the writer updates the schema in the metadata store. If the destination table does not exist, the writer creates the table and sets the schema ID to 0.
The writer derives the Parquet schema from the Iceberg schema to prepare to write the data files.
After writing the Parquet data files, the writer writes the manifest files, the manifest lists, and the metadata files.
Finally, the writer tells the catalog to update the table’s current metadata pointer to the new metadata file.
My Thoughts
Although choosing to store data in object storage can make Bufstream way cheaper than Kafka, it must sacrifice the low-latency performance of the disks. In their benchmark, the median end-to-end latency was 260 milliseconds, and the p99 latency was 500 milliseconds. Still, these numbers are considerably better than those of other solutions, such as WarpStream.
Bufstream offers a way to optimize latency. It batches messages before writing to object storage to limit the PUT request. Thus, users can adjust the batch size to reduce latency, but more frequent PUT requests to object storage will increase the cost.
Given the vast cost savings compared to Kafka, Bufstream’s latency is acceptable. Unless you’re dealing with use cases that require super low latency, Bufstream's latency sacrifice does not impact much.
But if we set latency aside, Bufstream presents a strong alternative to Kafka in the cloud. Beyond cost efficiency, it offers a straightforward deployment model, built-in schema awareness for data quality enforcement, and the seamless transformation of Kafka’s storage layer into a lakehouse.
The native Iceberg support is a very valuable feature for me. In data engineering, transforming message queue data into analytics tables is inevitable. By transforming Kafka topics into Iceberg tables, Bufstream significantly reduces the burden on data engineers. The Iceberg format ensures broad compatibility, letting us use our favorite query engine over it, from Databricks, Snowflake, and BigQuery to Spark or Trino. Avoiding vendor lock-in is a big win for any company.
Outro
Thank you for reading this far!
Throughout this article, we’ve explored why Kafka may be inefficient in the cloud, how Bufstream offers a more cost-effective alternative by storing data in object storage, how it enhances data quality by making the broker schema-aware, and how Bufstream seamlessly transforms topic messages into Iceberg tables. We wrap up the article with some of my naive thoughts.
Now it’s time to say goodbye. See you in my next articles :)
Reference
[1] Gwen Shapira, Todd Palino, Rajini Sivaram, Krit Petty, Kafka The Definitive Guide Real-Time Data and Stream Processing at Scale (2021)
[2] Confluent, Schema Registry Clients in Action (2024)
Very thoughtful article. Thank you!
Hello Vu, about the red and blue colors in the 1st diagram under "A bit of Kafka", blue should be "disk read" red is "disk write"..
or am i wrong ??