
I spent 6 hours learning PySpark
How it works behind the scenes.

I invite you to join the club with a 50% discount on the yearly package. The offer will end soon.
I will publish a paid article every Tuesday. I wrote these with one goal in mind: to offer my readers, whether they are feeling overwhelmed when beginning the journey or seeking a deeper understanding of the field, 15 minutes of practical lessons and insights on nearly everything related to data engineering.
Intro
For a long time, Apache Spark has become the leading choice for data processing in the data engineering world. The field we’re seeing would be very different if Spark hadn’t existed; the event when the creators decided to start the Spark project at UC Berkeley AMPLab in 2009 will always be an important milestone for the data analytics and processing field.
I believe there is one more event that has a huge impact on how we process data, which is when Spark officially supported Python in version 0.7.0 in 2013. This enables users to harness the power of Spark with the intuitive syntax of Python.
This week, we delve into PySpark, exploring how it works behind the scenes, its significant impact, and its evolution over time.
Spark Overview
In 2009, UC Berkeley’s AMPLab developed Apache Spark, a functional programming-based API designed to simplify multistep applications, and created a new engine for efficient in-memory data sharing across computation steps.
Unlike MapReduce, Spark relies heavily on in-memory processing. The creator introduced the Resilient Distributed Dataset (RDD) abstraction to manage Spark’s data in memory. RDD represents an immutable, partitioned collection of records that can be operated on in parallel. Data inside RDD is stored in memory for as long as possible.
A Spark application consists of:

Driver: This JVM process manages the entire Spark application, from handling user input to distributing tasks to the executors.
Cluster Manager: This component manages the cluster of machines running the Spark application. Spark can work with various cluster managers, including YARN, Apache Mesos, or its standalone manager.
Executors: These processes execute tasks the driver assigns and report their status and results. Each Spark application has its own set of executors.
The Spark Driver-Executors cluster differs from the cluster hosting your Spark application. To run a Spark application, there must be a cluster of machines or processes (if you’re running Spark locally) that provides resources to Spark applications. The cluster manager manages this cluster and the machines that can host driver and executor processes, referred to as workers.
To learn Apache Spark, I wrote an article that contains everything you need to know about this processing framework. Check out the article here:

Why the support for Python is crucial
Besides SQL, Python is the preferred language for working in the field of data analytics. The language’s straightforward syntax makes it easy to learn and use, even for those with a non-technical background; data analysts and scientists, in particular, appreciate this.
Additionally, Python offers a vast collection of libraries for data analytics. Users can use pre-built tools to save time and effort. Some essential libraries include NumPy, Pandas, Matplotlib, and Scikit-learn, among others. The language can also be used to cover the whole data engineering pipeline, from orchestration (with Airflow) to building a robust data application for the stakeholders (with Streamlit)
If you build a tool for data engineers, data analysts, or data scientists that requires them to code, it must support Python as a first-class citizen. This is not the case with Apache Spark when it was first released. The framework was built with Scala, so the creators recommend using this functional programming language to work with Spark.
Until 2013, Spark finally supported Python in version 0.7.0 due to the emergence of this programming language in the data analytics field. Of course, the support for Python couldn’t compare to Scala at that time; it took Spark many versions from then to make Python one of the primary interfaces for users to work with Spark. Databricks provided some numbers to prove the PySpark position:
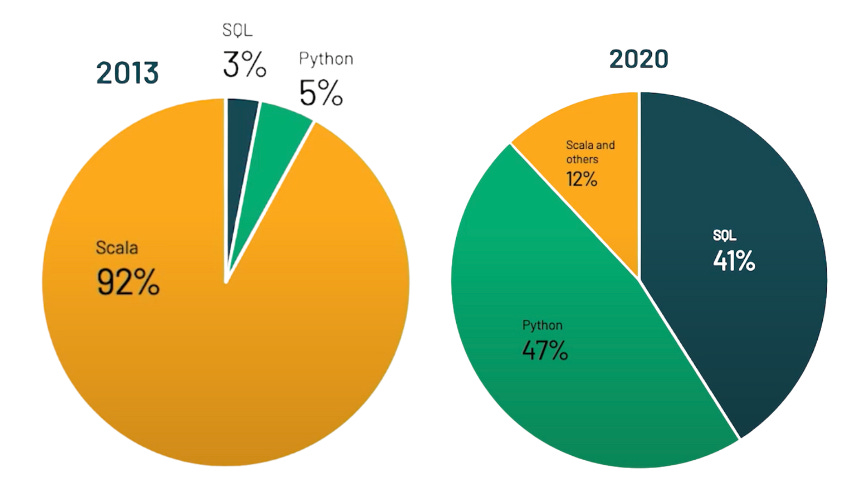
In 2013, 92% of their users used Scala, 5% used Python, and 3% used SQL for their Spark workload.
In 2020, 47% used Python, 41% used SQL, and 12% used Scala and other
In the next section, we delve into how PySpark works internally and discover how it has improved over time to overtake Scala - Spark’s native language.
How PySpark works behind the scenes
Revisiting the Spark application journey
Essentially, a Spark application will be in the same way, regardless of whether the logic is specified in Python or Scala:

Keep reading with a 7-day free trial
Subscribe to VuTrinh. to keep reading this post and get 7 days of free access to the full post archives.