
If you're learning Apache Spark, this article is for you
A baseline for your Spark learning and research.

My ultimate goal is to help you break into the data engineering field and become a more impactful data engineer. To take this a step further and dedicate even more time to creating in-depth, practical content, I’m excited to introduce a paid membership option.
This will allow me to produce even higher-quality articles, diving deeper into the topics that matter most for your growth and making this whole endeavor more sustainable.
And to celebrate this new milestone, I’m offering a 50% discount on the annual plan for a limited time.

Intro
At the time of this writing, Apache Spark has been released in its fourth major version, which includes many improvements and innovations.
However, I believe its core and fundamentals won’t change soon.
I have written this article to help you establish a good baseline for learning and researching Spark. It distills everything I know about this infamous engine.
Note: This article contains illustrations with many details. I recommend reading it on a laptop or PC to get the full experience.
Overview
In 2004, Google released a paper introducing a programming paradigm called MapReduce to distribute the data processing to hundreds or thousands of machines.
In MapReduce, users have to explicitly define the Map and the Reduce functions:

Map: It takes key/value pair inputs, processes them, and outputs intermediate key/value pairs. Then, all values of the same key will be grouped and passed to the Reduce tasks.
Reduce: It receives intermediate values from Map tasks. It then merges the intermediate values from the same key using the defined logic (e.g., Count, Sum, ...)
To ensure fault tolerance (e.g., a worker dies during the process), MapReduce relies on disk to exchange intermediate data between data tasks.

Based on Google's paper, Yahoo released the open-sourced implementation of MapReduce, which soon became the go-to solution for distributed data processing. It rose and dominated, but it wouldn’t last long.
The strict Map and Reduce paradigm limits the flexibility, and the disk-based data exchange might not be suitable for use cases like machine learning or interactive queries.
UC Berkeley’s AMPLab saw a problem that needed to be solved. Although cluster computing had a lot of potential, they observed that the MapReduce implementation might not be efficient.
They created Apache Spark, a functional programming-based API to simplify multistep applications, and developed a new engine for efficient in-memory data sharing across computation steps.
Spark RDD
Unlike MapReduce, Spark relies heavily on in-memory processing. The creator introduced the Resilient Distributed Dataset (RDD) abstraction to manage Spark’s data in memory. No matter the abstraction you use, from dataset to dataframe, they are compiled into RDDs behind the scenes.
RDD represents an immutable, partitioned collection of records that can be operated on in parallel. Data inside RDD is stored in memory for as long as possible.
Why RDD immutable
You might wonder why Spark RDDs are immutable. Here are some of my notes:
Concurrent Processing: Immutability keeps data consistent across multiple nodes and threads, avoiding complex synchronization and race conditions.
Lineage and Fault Tolerance: Each transformation creates a new RDD, preserving the lineage and allowing Spark to recompute lost data reliably. Mutable RDDs would make this much harder.
Functional Programming: RDDs follow principles that emphasize immutability, making handling failures easier and maintaining data integrity.
Properties
Each RDD in Spark has five key properties:

List of Partitions: An RDD is divided into partitions, Spark's parallelism units. Each partition is a logical data subset and can be processed independently with different executors (more on executors later).
Computation Function: A function determines how to compute the data for each partition.
Dependencies: The RDD tracks its dependencies on other RDDs, which describe how it was created.
Partitioner (Optional): For key-value RDDs, a partitioner specifies how the data is partitioned, such as using a hash partitioner.
Preferred Locations (Optional): This property lists the preferred locations for computing each partition, such as the data block locations in the HDFS.
Lazy
When you define the RDD, its data is unavailable or transformed immediately until an action triggers the execution. This approach allows Spark to determine the most efficient way to execute the transformations. Speaking of transformation and action:

Transformations, such as
maporfilter, define how the data should be transformed, but they don't execute until an action forces the computation. Because RDD is immutable, Spark creates a new RDD after applying the transformation.Actions are the commands that Spark runs to produce output or store data, thereby driving the actual execution of the transformations.
Fault Tolerance
Spark RDDs achieve fault tolerance through lineage.
As mentioned, Spark keeps track of each RDD’s dependencies on other RDDs, the series of transformations that created it.
Suppose any partition of an RDD is lost due to a node failure or other issues. Spark can reconstruct the lost data by reapplying the transformations to the original dataset described by the lineage.
This approach eliminates the need to replicate data across nodes or write data to disk (like MapReduce).
Architecture
A Spark application consists of:

Driver: This JVM process manages the entire Spark application, from handling user input to distributing tasks to the executors.
Cluster Manager: This component manages the cluster of machines running the Spark application. Spark can work with various cluster managers, including YARN, Apache Mesos, or its standalone manager.
Executors: These processes execute tasks the driver assigns and report their status and results. Each Spark application has its own set of executors.
The Spark Driver-Executors cluster differs from the cluster hosting your Spark application. To run a Spark application, there must be a cluster of machines or processes (if you’re running Spark locally) that provides resources to Spark applications.
The cluster manager manages this cluster and the machines that can host driver and executor processes, called workers.
Mode
Spark has different modes of execution, which are distinguished mainly by where the driver process is located.
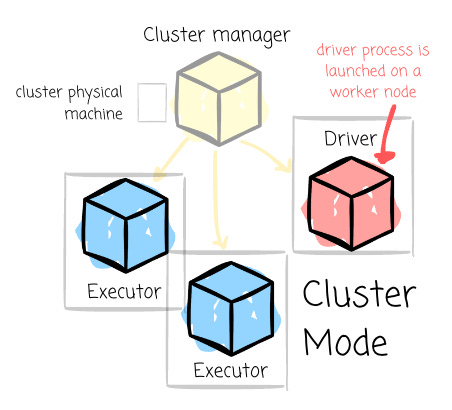
Cluster Mode: The driver process is launched on a worker node alongside the executor processes in this mode. The cluster manager handles all the processes related to the Spark application.
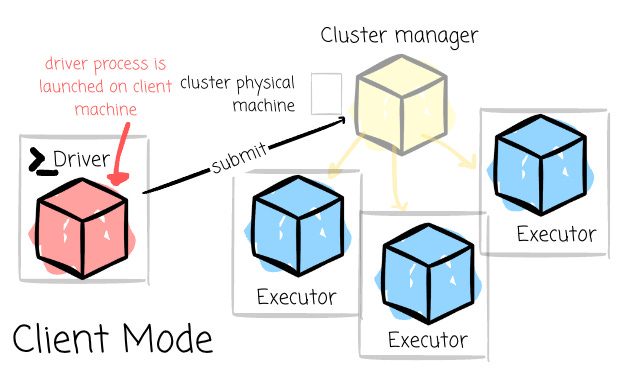
Client Mode: The driver remains on the client machine that submitted the application. This setup requires the client machine to maintain the driver process throughout the application’s execution.
Local mode: This mode runs the entire Spark application on a single machine, achieving parallelism through multiple threads. It’s commonly used for learning Spark or testing applications in a simpler, local environment.




Anatomy
It’s crucial to understand how Spark manages the workload:

Job: A job represents a series of transformations applied to data. It encompasses the entire workflow from start to finish.
Stage: A stage is a job segment executed without data shuffling. A job is split into different stages when a transformation requires shuffling data across partitions.
DAG: In Spark, RDD dependencies are used to build a Directed Acyclic Graph (DAG) of stages for a Spark job. The DAG ensures that stages are scheduled in topological order.
Task: A task is the smallest unit of execution within Spark. Each stage is divided into multiple tasks, which execute processing in parallel across different partitions.
You might wonder about the “data shuffling” from the Stage’s part. To dive into shuffle, it’s helpful if we could understand the narrow and wide dependencies:

Transformations with narrow dependencies are those where each partition in the child RDD has a limited number of dependencies on partitions in the parent RDD. These partitions may depend on a single parent (e.g., the map operator) or a specific subset of parent partitions known beforehand (such as with coalesce).
Transformations with wide dependencies require data to be partitioned in a specific way, where a single partition of a parent RDD contributes to multiple partitions of the child RDD. This typically occurs with operations like groupByKey, reduceByKey, or join, which involve shuffling data. Consequently, wide dependencies result in stage boundaries in Spark's execution plan.
A typical journey of the Spark application

Keep reading with a 7-day free trial
Subscribe to VuTrinh. to keep reading this post and get 7 days of free access to the full post archives.