
Why single-node engines like DuckDB and Polars are getting a lot of attention?
From cluster-based engines like MapReduce or Spark to the claim "Big Data is dead"

I invite you to join my paid membership list to read this writing and 150+ high-quality data engineering articles:
If that price isn’t affordable for you, check this DISCOUNT
If you’re a student with an education email, use this DISCOUNT
You can also claim this post for free (one post only).
Or take the 7-day trial to get a feel for what you’ll be reading.
Intro
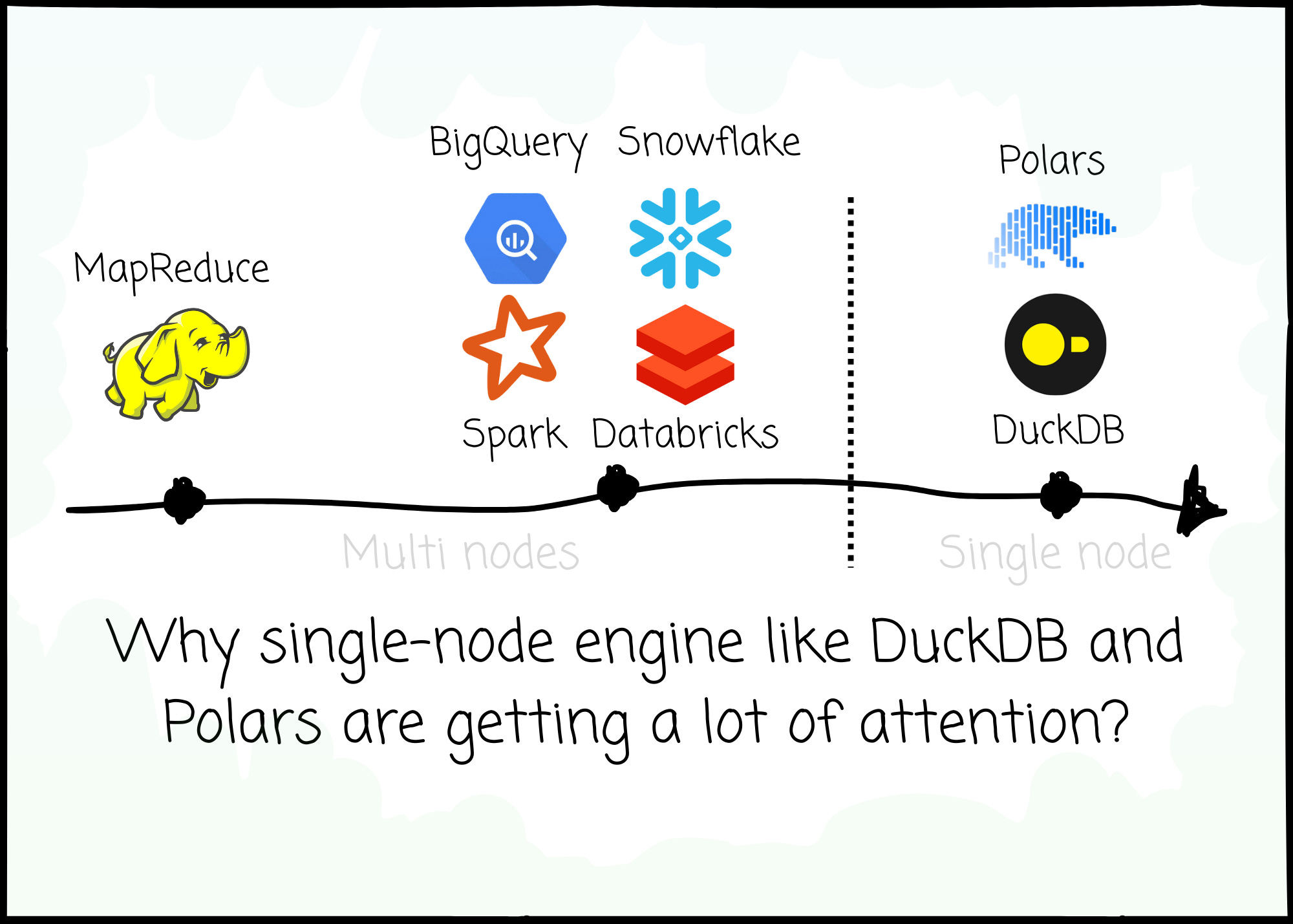
If you asked the internet for the go-to data processing engine in the 2000s, you would get MapReduce.
If you asked the internet for the go-to data processing engine in the 2010s-2020s, you would get Apache Spark and cloud data warehouses such as BigQuery, Snowflake, Redshift …
If you asked the internet for the go-to data processing engine at the moment, you would still get Spark, BigQuery, Snowflake, or Redshift.
But you will see recommendations for single-node solutions like Polars or DuckDB.
For the last 20 years, cluster-based engines have been the dominant player.
But now, something has changed.
In this article, I try to understand the rise of single-node solutions such as Polars or DuckDB. We will examine the evolution from the pre-Internet era, the MapReduce hype, Spark, and the dominance of cloud data warehouses to see what works. From that, we explore the motivation behind those single-node solutions.
Note 1: This article is based entirely on my research online, so it might not reflect the context at that time. Feel free to correct me.
Note 2: This article won’t dive deep into DuckDB or Polars, as I solely deliver my research on the motivation behind these systems. I might spend time researching and writing articles about DuckDB or Polars in the future.
One machine was enough
In the past, the volume of generated data was small.
If the company needed to use data to drive business operations, the process of consolidating, cleaning, and processing data could be performed on a single machine. In addition, most of the data still resided in the OLTP systems, as data analytics was not as popular as it is today.
A single machine is enough.
MapReduce
Then, the internet was invented. More and more digital data is generated. The nature of data changed from human-entered records in databases to machine-generated streams.
The data evolved in both volume and structured aspects.
Google is one of the companies that understands this challenge the most.
Founded in 1998 and surviving the DotCom bubble, Google established itself as a leader in the web-based application market.
Their engine at the time became the go-to choice for anyone who wanted to search for something on the internet.
For the search to work, Google had to process a lot of data, from crawled documents, web request logs, or the inverted index.
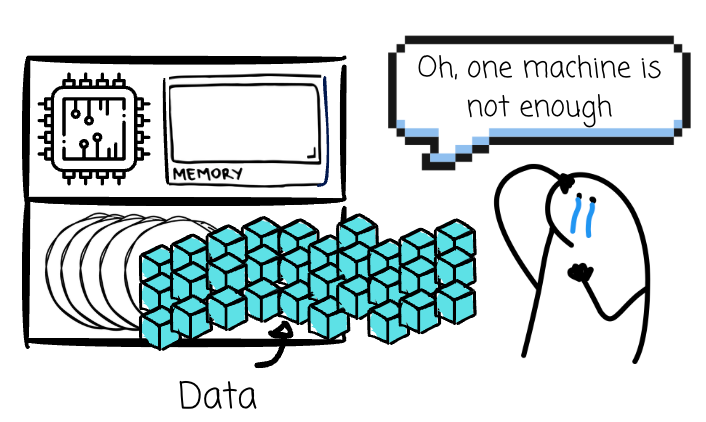
Of course, with this global scale of data, Google engineers could not process it on a single machine. They needed to bring multiple computers.
There were challenges:
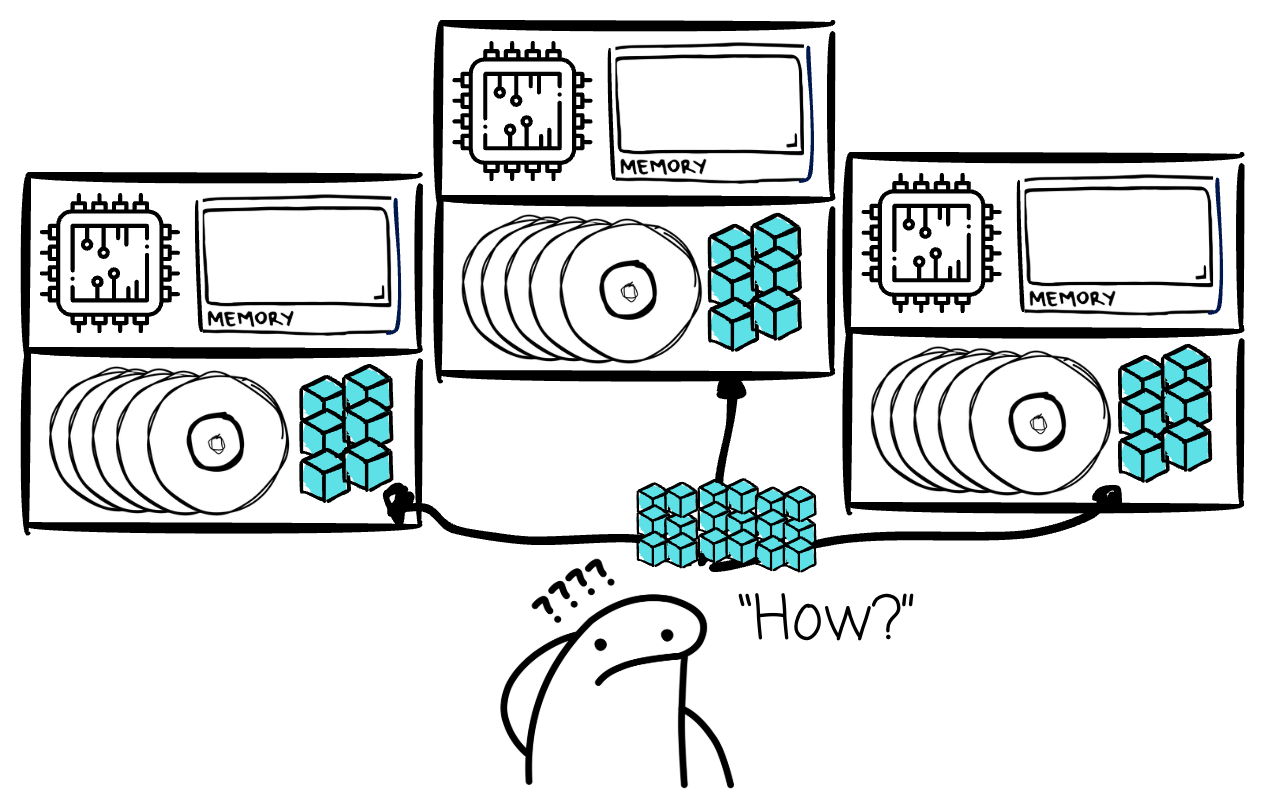
How to parallelize the computation?
How to distribute the data efficiently?
How to handle failures?
To solve this, Google designed a new abstraction that allows them to express simple computations but abstracts away the details of parallelization. This model is inspired by the map and reduce primitives in Lisp and other functional languages.
They called it MapReduce. At the high level, it has two functions, both of which are defined by the users:

Map: It takes key/value pair inputs, processes them, and outputs intermediate key/value pairs. All values of the same key are grouped and passed to the Reduce tasks.
Reduce: It receives intermediate values from Map tasks. The values for the same key are merged using the logic defined in the Reduce function (e.g., Count, Sum, ...).
Map workers and Reduce workers exchange the data via disks; every output data must be persisted in hard disks. The Master coordinates the entire process.

One of the ultimate goals of MapReduce is to process large amounts of data across multiple machines reliably, and persisting data on disk can help Google achieve that. Later, Yahoo developed and open-sourced Apache Hadoop, which included the MapReduce paradigm inspired by the Google idea.
It did not take long for Hadoop MapReduce to become famous, as it was almost the only framework at the time to promise dealing with “big data” problems.
However, that hype did not last forever.
I invite you to join my paid membership list to read this writing and 150+ high-quality data engineering articles:
If that price isn’t affordable for you, check this DISCOUNT
If you’re a student with an education email, use this DISCOUNT
You can also claim this post for free (one post only).
Or take the 7-day trial to get a feel for what you’ll be reading.
