
Why is dbt so popular?
The motivation behind dbt and why it's becoming a transformation standard(?)

To celebrate Lunar New Year (the true New Year holiday in Vietnam), I’m offering 50% off the annual subscription. The offer ends soon; grab it now to get full access to nearly 200 high-quality data engineering articles.

Intro
In 2021, my company reorganized the data team.
The data engineering team got a new leader.
After the initial greetings, he announced, "I’m bringing dbt into our stack. Do you know dbt? It’s popular right now."
I shook my head. Most of my teammates did, too.
Despite our attentive expressions, my first thought was: Here we go again—another leader introducing a trendy tool to prove a point.
Fast forward four years, and dbt has proven it’s far more than just hype. It’s becoming a standard(?)
If you work in data, you’ve probably heard of dbt at least once, or you may even have used it yourself.
This week's article will explore dbt, what it is, why people created it, and why it got adopted so much.
This is not a dbt tutorial article, and all the research is solely driven by my curiosity.
What is dbt
dbt is a CLI tool that lets us efficiently transform data with SQL.

That’s it.
It’s not an engine like Spark; it’s not a database like Postgres or Snowflake; it’s a tool that helps you manage your SQL data transformation.
At the heart of dbt is the concept of model. A model is an SQL query saved in a .sql file. Each model defines a transformation that transforms data into a desired output inside your data warehouse. When dbt runs, it executes these queries and materializes the transformed data as a table or view. Models give us a tangible form of the SQL transformation logic.

dbt has two components: a compiler and a runner. We write dbt models and run some commands in the terminal. It will compile all the model’s code into SQL statements and execute them on the data warehouse: Snowflake, BigQuery, Databricks, or an engine like Spark or Trino. dbt doesn’t load your data or even know your data content (except for the schema and some metadata); everything stays inside your warehouse.
The model’s code is not solely SQL; it combines SQL and Jinja.

dbt’s jinja has special functions called source() and ref(), where the first lets the user reference a physical table in the data warehouse, and the latter enables us to reference other dbt models. Together, dbt can form a complete data transformation lineage in which the very left model points to the physical table (using source) and the following models using ref to refer to the previous models.

dbt also lets us write modular and reusable model structures, which allows teams to break down transformations into smaller, maintainable components.
Before the production run, you can test your dbt models to ensure they produce the expected results. It also auto-generates documentation, providing a clear overview of your data transformations and lineage.
A dbt model is purely code at its core, making it naturally compatible with Git for version control. Teams can track changes, collaborate via pull requests, roll back to previous versions, and implement CI/CD pipelines—just like software engineers do with application code.
Why did people create it?
The creators of dbt encourage data analysts (DA) to take more responsibility for managing data transformations by adopting software engineering best practices.
In 2016, while at RJMetrics, Tristan Handy developed dbt to address the challenges of complex data transformation pipelines. It enabled analysts to write modular SQL code, implement version control, and conduct testing, thereby enhancing the efficiency and reliability of data workflows.

But what motivates data analysts (DAs) to become more involved in data transformation, which was previously the primary responsibility of data engineers (DEs)?
Setting up a pipeline to move data from A to B is no trivial task. Data engineers must understand the data sources and the expected output format and manage the underlying infrastructure. This includes scaling Spark clusters, maintaining Airflow environments, and optimizing transformation logic—all while ensuring data quality across potentially hundreds of pipelines. The complexity and effort required to keep these systems running efficiently can quickly become overwhelming.
To celebrate Lunar New Year (the true New Year holiday in Vietnam), I’m offering 50% off the annual subscription. The offer ends soon; grab it now to get full access to nearly 200 high-quality data engineering articles.
A team of highly skilled data engineers is often required for large-scale systems. However, not every company has the resources to build such a team. It’s common to find organizations—especially medium-sized businesses and startups—operating with one or two data engineers.
A data engineer can manage two or three pipelines well, but what happens when that number grows to fifty? The workflow begins to slow down because pipelines need time to develop, test, and deploy. The ability to maintain data quality, implement necessary changes, and deliver timely insights starts to deteriorate. The data engineer becomes a bottleneck, and the data team struggles to keep up with business demands.
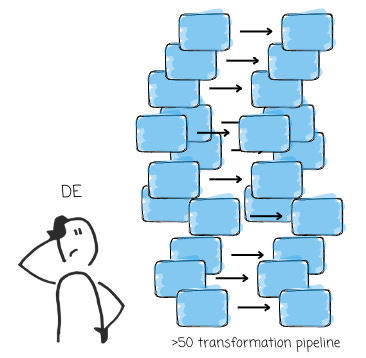
The ultimate goal is to make data more meaningful to the organization. A better way to manage the raw-to-usable-data process is to democratize the data transformation instead of requiring a small group of people (data engineers) to know how to do it.
Imagine an alternative scenario: What if data analysts could take a more active role in data transformation? Instead of waiting for a data engineer to implement every transformation they need, analysts could self-serve, define, and build transformations independently. Since data analysts deeply understand the business domain, they could ensure that the final datasets align with business needs from the start rather than relying on multiple handoffs.

Why is it so popular?
2016: Launched with 3 companies using dbt.
2017: Adoption grew to 100 companies.
2018: Expanded to 280 companies.
2019: Still 280 companies, steady growth.
2021: Surpassed 5,000 companies.
2022: Exceeded 9,000 companies.
McDonald's, Nasdaq, Discord, Shopify, and many other companies use it. If your company uses SQL on data transformation, there is a high chance that dbt is one of your company’s tech stacks.

So why is it so popular?
An obvious observation is that dbt hit the market fit; the creator finds and solves some problems. Turns out many organizations out there want to solve the same problems: a “right“ way to manage, democratize, and collaborate the data transformation using SQL.
However, solving the problem versus solving the problem efficiently are two different things. I believe the way dbt solves problems is crucial to its success. To explain this aspect, I borrow criteria from the Unified Theory of Acceptance and Use of Technology (UTAUT), a model that aims to explain user intentions to use an information system and subsequent usage behavior:
Performance Expectancy: dbt enables data analysts and engineers to transform data within their warehouses effectively. It provides a framework for unifying how they write, test, and document SQL transformation logic.
Effort Expectancy: Using dbt does not require much effort; if you’re familiar with SQL (By accident, DE, DA, and DS communicate via SQL), 30 minutes to learn dbt jinja is enough to make you ready to build the first dbt model. Furthermore, it is easy to install with pip, and due to its simple nature, containerizing the whole dbt project is possible: running it with Airflow on Kubernetes or implementing CI/CD with GitLab runner are all convenient.
Social Influence: The growing adoption of dbt within the data community and endorsements from reputable organizations contribute to its perceived importance and encourage others to adopt it.
Facilitating Conditions: The prerequisites of running dbt? An IDE, a data warehouse that can run SQL, and the willpower to write SQL transformation. That’s it. You don’t prepare dedicated hardware for it, plan storage capacity, or estimate the CPUs and RAMs for it. Their documents and the support from the community are sufficient to upgrade the company’s standard of write, testing, and documenting to the next level (in most cases). Like most of the tools, dbt starts with a limited set of integration points, over time, more and more organizations use dbt, resulting in more integration options. Its interoperability seamlessly integrates with existing systems, lowering the barrier to adoption.
Besides all the points above, I believe an essential factor that leads to the wide adoption of dbt is the emergence of the cloud data warehouse.
In the past, data transformation happened before loading it into the warehouse. The raw data was not present at the destination; it was only clean and structured data.
Data warehouse systems were expensive, and companies had to purchase servers and licenses from vendors. Storage disks were also expensive, and networks weren’t as fast as they are today. Compute and storage were tightly coupled, and system scaling was difficult.
Additionally, storing data in a columnar format wasn’t common then, and row-oriented databases didn’t perform well for analytics workloads.
All of these factors made ETL a perfect solution. Data had to be carefully extracted and transformed so that only a relatively small, curated subset was loaded into the warehouse for analysis.
But things have changed.
The birth and rise of cloud data warehouses have made the solution much more accessible. Pay-as-you-go pricing models, cheaper storage, faster networks, and columnar storage/processing as the standard have commoditized high-performance, cost-efficient data warehouses.
Your shiny warehouse will be up and running with just a few clicks.
People soon realized they didn’t have to transform the data before loading it into the warehouse. They could dump data straight from the source (maybe some lightweight processing is needed) and let the transformation happen directly in the warehouse later.
So why is my data already in the warehouse? Why just not use SQL to transform the data? All cloud data warehouse query engines let you execute queries on enormous amounts of historical data with state-of-the-art techniques applied to both storage and processing, and these systems only get better.

So, again, why invest in a separate, expensive system for data transformation when we've already spent significant resources on a platform that enables us to process massive amounts of data using SQL?
And guess which tool helps you streamline your SQL transformation scripts?
My thoughts
Firstly, dbt encourages DAs to be more involved in data transformation, which does not mean DAs will completely replace the DEs in this process. My opinion on dbt is it allows DEs and DAs to collaborate efficiently. The DAs can contribute business domain knowledge, and the the DEs can contribute the expertise and knowledge of how to optimize the SQL query based on the underlying engine or other engineering practices, such as organization standards of writing modular and reusable DBT macros.
Secondly, providing the ability to do SQL transformation for a wide range of users does not mean SQL transformation can not be done arbitrarily. Typically, the data transformation must serve the organization's data modeling. dbt is a tool that helps us manage the SQL transformation; whether the transformation is meaningful or not depends on us; how data is transformed, organized, and served depends on how we model data. If you dump the data in the warehouse, adopting dbt is pointless. Many people also think that writing dbt models is doing data modeling. A data model defines how data is structured and related, ensuring consistency; it’s tool agnostic. A dbt model is a SQL-based transformation script that shapes raw data into a structured format inside the data warehouse.
—
All of the above are my research and thoughts on the popularity of dbt. We first explore what is the dbt, why it’s so popular, and some of my thoughts on it.
I independently consolidate, analyze, and present this information. Please let me know if you spot any logical gaps.
Also, your feedback on what works well and what can be improved is invaluable in helping me create higher-quality content.
Thank you for reading this far.
Now, it’s your turn: Are you a fan of dbt?
Reference
[1] Tristan Handy, What, exactly, is dbt? (2017)
[2] Connor McArthur, DBT: Powerful, Open Source Data Transformations | Fishtown Analytics / DBT (2017)
[3] Wikipedia, Unified theory of acceptance and use of technology
Excellent article, as always. ✅ Any thoughs on how organizations monitor effectiveness of dbt transformations built by many not-so-tech-friendly DAs?
Great read. For organizations in GCP, is there a big reason for using dbt instead of Dataform? It addresses most of the points you mentioned.