
Why did Databricks build the Photon engine?
The Lakehouse, the motivation, and the difference between Photon and the existing engine.

To celebrate Lunar New Year (the true New Year holiday in Vietnam), I’m offering 50% off the annual subscription. The offer ends soon; grab it now to get full access to nearly 200 high-quality data engineering articles.
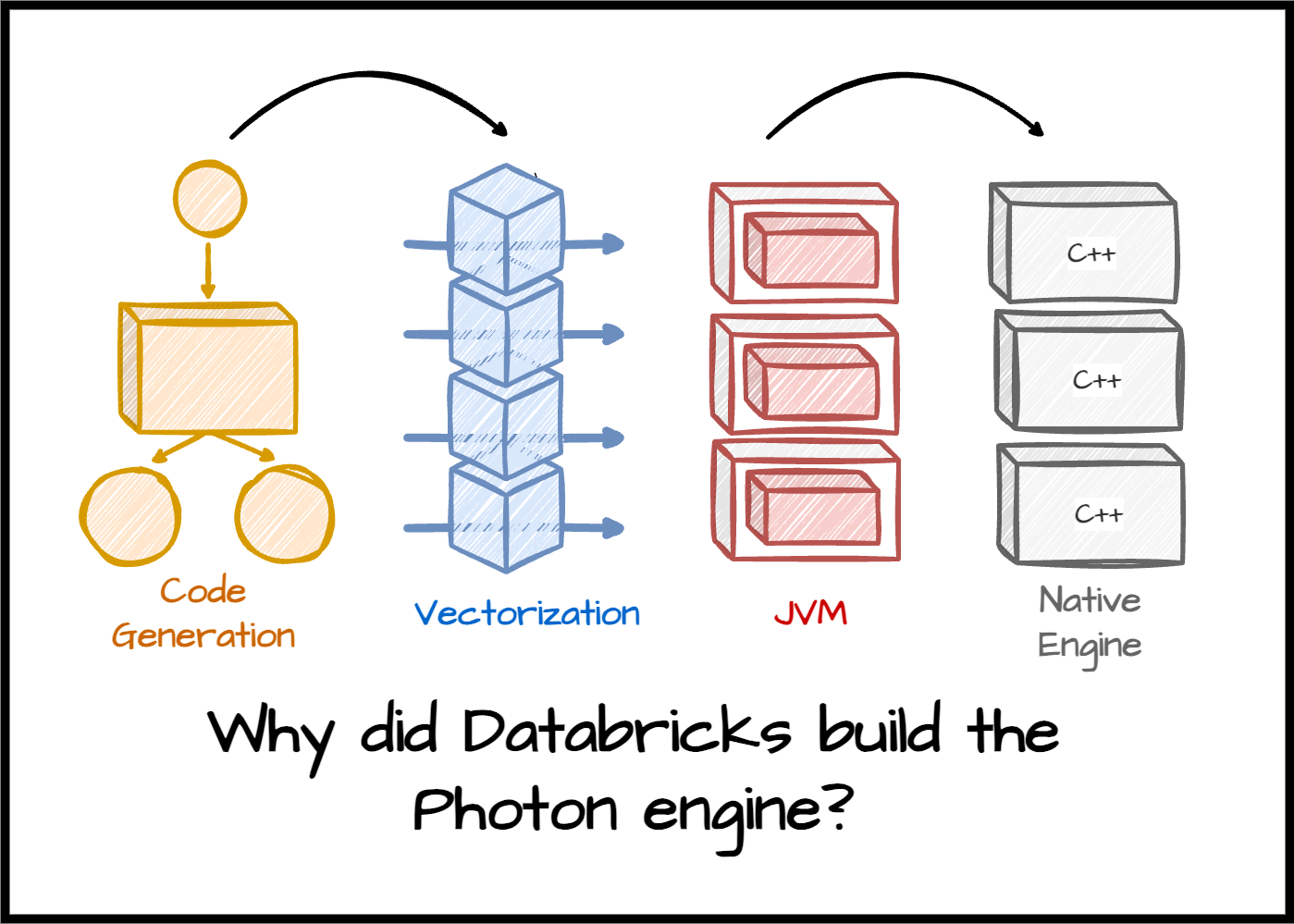
Table of contents:
Motivation
Challenges
Databricks Lakehouse architecture
The Databricks Runtime (DBR)
Overall Execution Engine Design
Intro
I have an imagined checklist about the OLAP system I want to research:
Snowflake: ✅
AWS Redshift: ✅
Databricks: ⏳
…
Today, we will deep dive into Databricks’s Photon Engine to temporarily complete my checklist. I will split the Photon’s paper note into two parts: the first part will focus on the motivation behind the decision to develop a new execution engine from Databricks, and the second part will learn more about the internal designs of the Photon engine.
I used “temporarily“ because I am still looking for a system for my self-research; if you want to suggest any OLAP systems, please comment or DM me.
Motivation
Traditionally, enterprises store raw data in the data lake backed by elastic object storage like S3 or GCS. For most analytics demands, enterprises must load their data into data warehouses to achieve high performance and governance. However, this two-tier architecture is complex and expensive, and the warehouse may be out of sync with the raw data due to issues in the ETL pipeline.
Many companies are considering a new data management paradigm called the Lakehouse, which directly brings data warehouse powers to the data lakes. This single-tier architecture promises to simplify data management, as users can govern and query all their data in one place, and there are fewer ETL steps and query engines to manage. In return, this paradigm introduces new challenges for query execution engines. The engine now needs to provide performance on the unseen datasets in the data lakes. Toward these goals, Databricks introduces Photon, a vectorized query engine for Lakehouse.
Challenges
Databricks designed Photon to solve two key challenges: Supporting raw data and supporting existing Spark APIs.
Supporting raw data
The Lakehouse query engines face a greater variety of data than traditional warehouses. From organized datasets to raw data with messy layouts, many small files, many columns, and no valuable statistics, the execution engine must have the flexibility to deliver good performance on a wide range of data.
Databricks addresses the challenge with two design decisions. First, they build the Photon engine using a vectorized model instead of the code generation approach that Apache Spark implements. Vectorized execution enabled support runtime adaptivity; Photon discovers, maintains, and leverages micro-batch data characteristics with specialized code paths to adapt to the properties of Lakehouse data.
Second, Databricks developed Photon in C++ instead of following the Databricks Runtime engine, which used the Java Virtual Machine (JVM). To explain this decision, Databricks said, “They were hitting performance ceilings with the existing JVM-based engine.” Moreover, they found that the performance of native code was easier to explain than the JVM engine, as they can explicitly control aspects like memory management and SIMD in C++.
Supporting existing Spark APIs
Databricks customers leverage Apache Spark’s APIs with DataFrame abstraction and SQL code for most applications. Databricks designs Photon to integrate with the existing Spark engine and native SQL workload. This was a considerable challenge for Databricks as Photon has to work with Spark’s Java-based SQL engine.
To solve this, Photon integrates closely with the Apache Spark-based Databricks Runtime (DBR). DBR is a fork of Apache Spark that provides the same interface but has enhancements for reliability and performance. Photon acts as a new set of physical operators inside DBR. The query plan can use these operators like any other Spark’s. By integrating this way, customers can continue to run their workloads without any changes and still get the benefits of Photon. The system can run the queries partially in Photon; if it needs unsupported operations, they are switched back to SparkSQL. Databricks tests Photon to ensure its semantics are consistent with Spark SQL’s, thus preventing unexpected behavior changes in existing workloads.
Databricks Lakehouse architecture
This section describes Databricks’ Lakehouse product to deliver the context of how Photon integrates with the Lakehouse system.
Databricks Lakehouse consists of four main components:
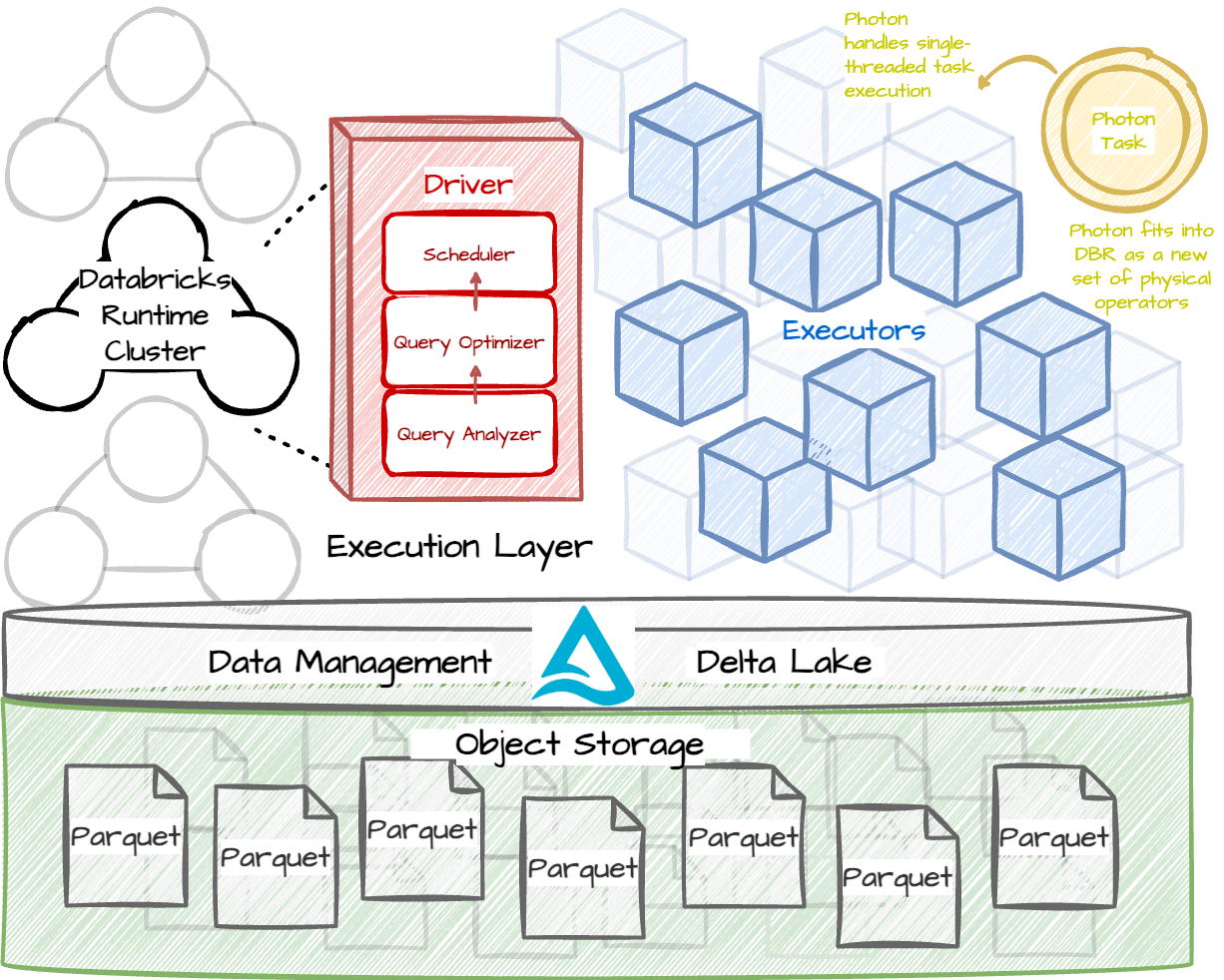
Data Lake Storage: Databricks separates computing and storage, allowing customers to choose their desired object storage (e.g., S3, GCS). Databricks accesses customers' existing datasets by using connectors between the compute service and the object storage. Data is stored in open file formats like Apache Parquet.
Data Management: Unlike traditional data warehouses that require users to load data into proprietary formats, most Databricks customers use Delta Lake, an open-source storage framework, to bring warehouse-style features directly to the storage layer. Delta Lake enables many features, such as ACID constraints, time travel, and efficient metadata operations. The framework stores both the data and metadata in Parquet format. Databricks also implements several optimizations, such as automatic data clustering and caching, on top of the Delta Lake to achieve better performance.
Elastic Execution Layer: This layer executes operational queries, such as auto data clustering and metadata access, and external queries like ETL jobs, machine learning, and SQL workload. Dealing with exabytes of data daily, it must operate in a scalable and reliable manner. Photon integrates with this layer by handling single-threaded query execution on each partition of the data processed. The layer uses Virtual Machines (VMs) from cloud providers like Amazon EC2 or Google Compute Engine. Databricks manages these VMs using the cluster abstraction. The cluster has a driver node that coordinates the execution and executor nodes that handle data processing. These VMs run Databricks Runtime and operational software like log collector or access controller. We will go into detail about the Databricks Runtime in the next section.
To celebrate Lunar New Year (the true New Year holiday in Vietnam), I’m offering 50% off the annual subscription. The offer ends soon; grab it now to get full access to nearly 200 high-quality data engineering articles.
The Databricks Runtime (DBR)
The DBR handles all query execution, provides all Apache Spark interfaces, and contains several enhancements. Photon is considered the lowest level of DBR and handles single-threaded execution in the context of DBR’s multi-threaded execution model.
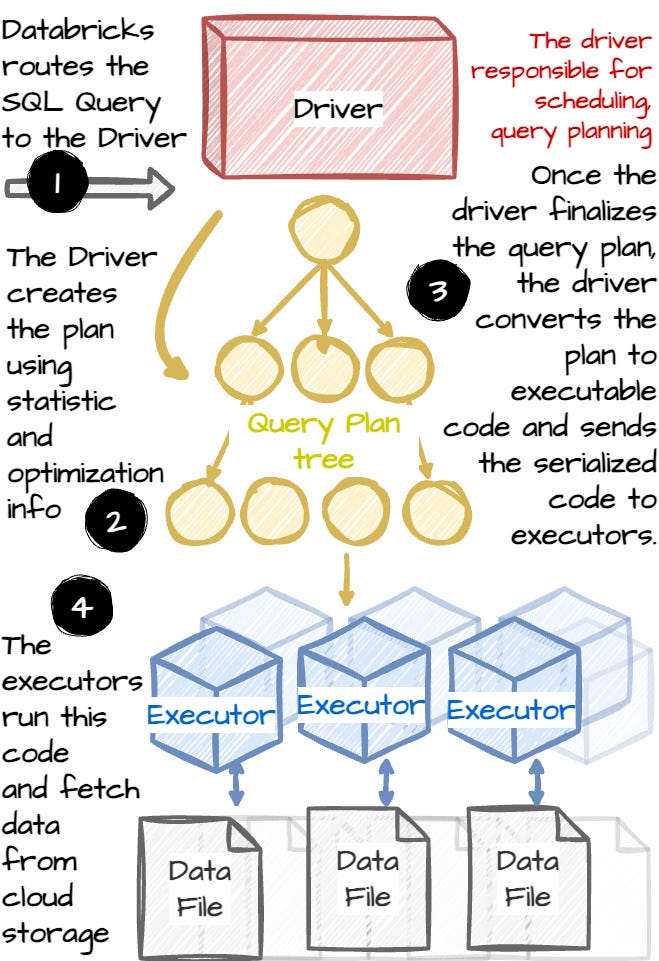
Customers submit jobs to DBR, each divided into stages. A stage represents a part of a job that reads or exchanges data. Stages are broken up into tasks that execute the same code on different data partitions. The next stage begins right after the previous stage ends. This allows fault tolerance or runtime adaptive execution by replaying stages or changing the query’s plan at the stage boundaries.
DBR uses a centralized driver node for scheduling and query planning. The driver node manages executor nodes, each responsible for task execution. Each node scans data, processes it, and outputs results. The execution process is multi-threaded and has a task scheduler with a thread pool to execute tasks from the driver in parallel.
The driver converts SQL input or a DataFrame object into a query plan using Spark’s DataFrame APIs. A query plan is a tree of SQL operators that binds to the job’s stages. After having the plan, the driver launches tasks to execute the query’s stages. Each task uses the in-memory engine to process data. Photon is one of the execution engines. Let's take a look at Databricks query’s journey:
Execution Engine Design
In the following sections, we will see an overview of Photo’s architecture.
Overview
Photon is a C++ execution engine compiled into a shared library and invoked from DBR. It runs as part of a single-threaded task in an executor’s JVM process. Photon constructs an SQL query as a tree of operators, where each operator uses a HasNext()/GetNext() interface to pull a batch of data from its child operator. Photon operates over columnar data and uses interpreted vectorization instead of the code generation approach of Java operators. This means the in-memory data layout of Photon and the Java operators are different. One more point to note is that the engine’s operators communicate with Java operators using the Java Native Interface. The following section will discuss the differences between the existing engine and Photon.
JVM vs. Native Execution
Databricks decided to move away from the JVM and implement a native code execution engine. Integrating the new engine with the existing JVM-based runtime is challenging for Databricks. Here are several reasons that led Databricks to the decision to develop a new native execution engine:
The Lakehouse paradigm demands processing a wide range of workloads that stresses the JVM engine's in-memory performance.
Improving the JVM engine performance requires deep knowledge of JVM internals to ensure the JIT compiler output the optimal code.
Databricks found they lack control over lower-level optimizations such as custom SIMD kernels.
They also observed that garbage collection performance degraded on heaps greater than 64GB in size. Databricks had to manually manage off-heap memory in the JVM-based engine, leading to more complexity in the codebase.
The existing engine performs Java code generation and is constrained by the Java method size or code cache size.
Interpreted Vectorization vs. Code Generation
Modern OLAP systems build high-performance engines predominantly using two approaches: either interpreted vectorized design, which is inspired by the MonetDB/X100 system, or code-generated design, used in systems like Spark SQL or Apache Impala. Vectorized engines use a dynamic dispatch mechanism like virtual function calls to choose the code block for the execution; then, the system will process data in batches and enable SIMD to amortize virtual function call overhead. On the other hand, code generation uses a compiler at runtime to generate specific code for each query; this way, the approach doesn’t have to deal with virtual function call overhead. Databricks tries to implement both of the above approaches; here are their observations:
Code generation is more complicated to build and debug because the approach generates executing code at runtime; Databricks engineers need to add extra code manually to find issues. In contrast, the interpreted approach only deals with native C++ code; print debugging was much more manageable. As a result, their engineers only needed a couple of weeks to prototype the vectorized approach, while it took them two months with the code-generated approach.
Code generation removes interpretation and function call overheads by collapsing and inlining operators into a few functions. Despite the performance boost, this makes observability difficult. Operator collapsing prevents the engineers from observing metrics on how much time is spent in each operator, “given that the operator code may be fused into a row-at-a-time processing loop.” In contrast, the vectorized approach maintains clear boundaries between operators.
Photon can adapt to data properties by choosing a code path at runtime based on the input’s type. This is critical in the Lakehouse context because constraints and statistics may not be available for all queries.
Databricks found they can achieve code-generated specialization with vectorized engines by creating specialized fused operators for the most common cases.
For these reasons, Databricks chose the vectorized approach for the Photon engine.
If you want to learn more about vectorization and code generation, here are the two resources you should check out:
Row vs. Column-Oriented Execution
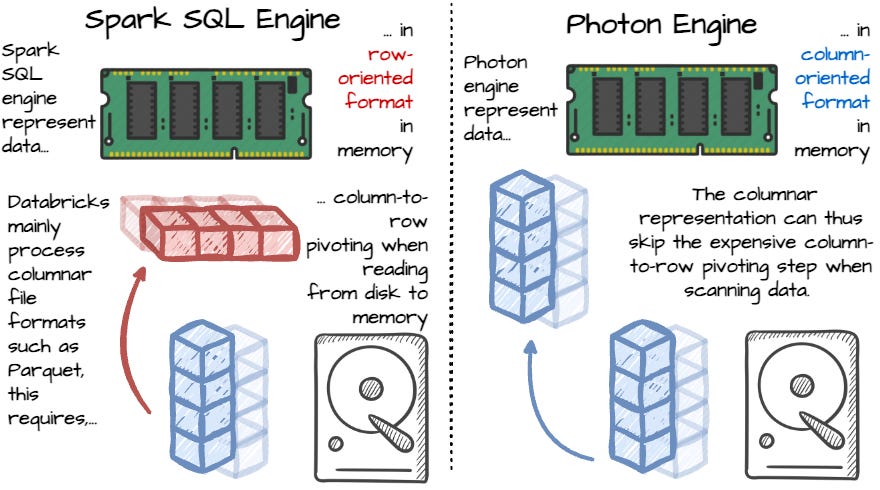
Traditionally, Spark SQL represents records in memory with a row-oriented format. Since the Lakehouse execution engine mainly deals with columnar files like Parquet, scanning data from disk to memory requires expensive column-to-row pivoting when using the Spark SQL engine. In contrast, Photon adopts columnar in-memory data representation; the system stores values of a particular column contiguously in memory. The columnar layout is more convenient for SIMD and enables more efficient data pipelining and pre-fetching. Moreover, this memory layout allows for the efficient working of columnar data on disks; it eliminates the column-to-row pivoting process and makes it easier to write data to disks with the columnar engine.
Partial Rollout
The existing SQL engine is based on open-source Apache Spark. The community behind Spark actively contributes improvements, features, and bug fixes. Building the Photon engine that covers all the features of the existing engine is impossible for Databricks. As a result, they develop Photon in a way that allows the system to partially execute a query in Photon and then gracefully fall back to the legacy engine for features that are unsupported.
Outro
That’s all for the first part of the Photon engine; we went through the motivation behind Photon, the challenges in the Lakehouse paradigm, Databricks’s Lakehouse architecture, and the overall designs of Photon. In the second part, we will go deeper inside inside the Photon internal.
So, see you next week.
References:
[1] Databricks, Photon: A Fast Query Engine for Lakehouse Systems (2022).
[2] Andy Pavlo, Vectorized Query Execution Using SIMD (CMU Advanced Database Systems) (2024).
[3] Andy Pavlo, JIT Query Compilation & Code Generation (CMU Advanced Database Systems) (2024).
Before you leave
Leave a comment or contact me via LinkedIn or Email if you:
Are interested in this article and want to discuss it further.
Would you like to correct any mistakes in this article or provide feedback?
This includes writing mistakes like grammar and vocabulary. I happily admit that I'm not so proficient in English :D
It might take you five minutes to read, but it took me more than five days to prepare, so it would greatly motivate me if you considered subscribing to receive my writing.
Hi Vu,
in Row VS Column oriented execution,
https://vutr.substack.com/i/142788667/row-vs-column-oriented-execution
You mentioned photon uses columnar in-memory representation, but Spark uses row-wise, This part is not very clear to me; I am a bit confused, as Parquet is made of row groups, where each block is a set of rows stored as columns with statistics. Can you explain this part.
Overall It is very good content, thanks for sharing