
I spent 8 hours learning Parquet. Here’s what I discovered
I finally sat down and learned about it.

My ultimate goal is to help you break into the data engineering field and become a more impactful data engineer. To take this a step further and dedicate even more time to creating in-depth, practical content, I’m excited to introduce a paid membership option.
This will allow me to produce even higher-quality articles, diving deeper into the topics that matter most for your growth and making this whole endeavor more sustainable.
Intro
I have an imaginary backlog that contains topics I want to write about, and Apache Parquet has been sitting there for a while.
This week, I pulled Parquet out of the backlog, brushed off the thick layer of dust, and committed to diving into this file format.
The article you’re reading is everything I distilled after learning about this file format structure and its read/write protocol.
Overview
When dealing with large datasets, the structure of your data can determine how efficiently it can be stored and accessed.
Traditional row-wise formats store data as records, one after another, much like a database table.
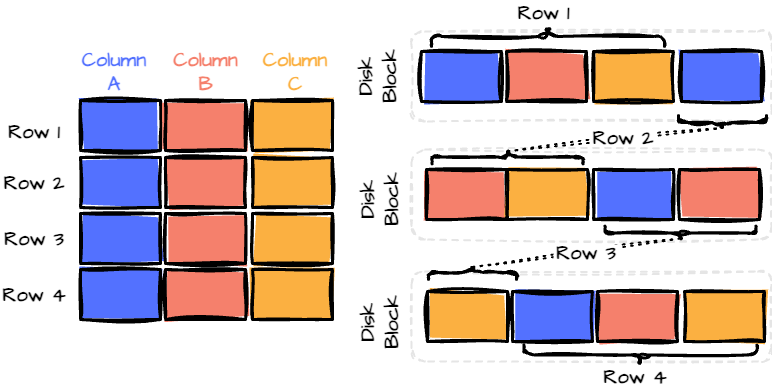
This format is intuitive and works well when accessing entire records frequently. However, it can be inefficient when dealing with analytics, where you often only need specific columns from a large dataset.
For example, imagine a table with 50 columns and millions of rows. If you’re only interested in analyzing 3 of those columns, a row-wise format would still require you to read all 50 columns for each row.
Columnar formats address this issue by storing data in columns instead of rows. This means that when you need specific columns, you can read only the data you need, significantly reducing the amount of data scanned.
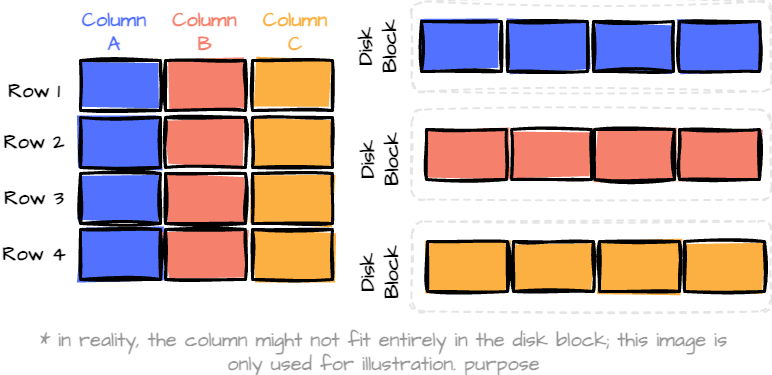
However, simply storing data in a columnar format has some downsides. The record write or update operation requires touching multiple column segments, resulting in numerous I/O operations. This can significantly slow the write performance, especially when dealing with large datasets.
In addition, when queries involve multiple columns, the database system must reconstruct the records from separate columns. The cost of this reconstruction increases with the number of columns involved in the query.
The hybrid format combines the best of both worlds.
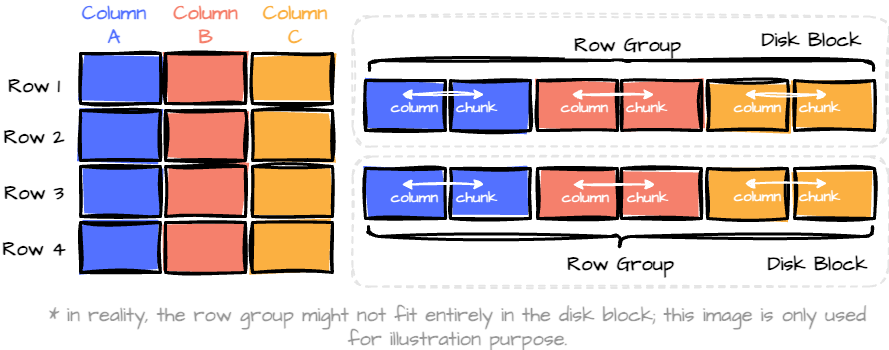
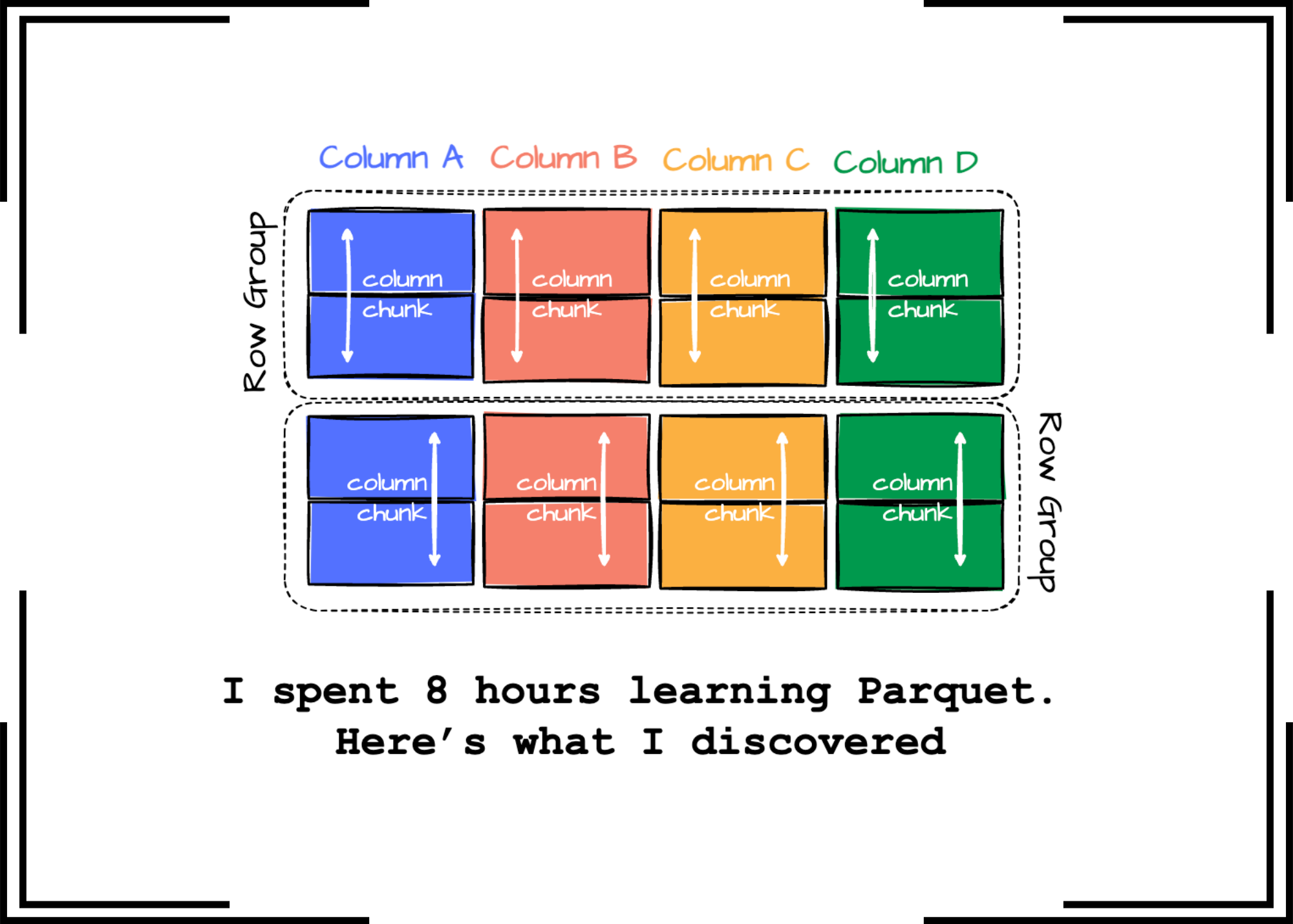
The format groups data into "row groups," each containing a subset of rows. (horizontal partition.) Within each row group, data for each column is called a “column chunk." (vertical partition)
In the row group, these chunks are guaranteed to be stored contiguously on disk.
In the past, I thought Parquet was purely a columnar format, and I’m sure many of you might think the same. To describe it more precisely, Parquet organizes data in a hybrid format behind the scenes.
We will delve into the Parquet file structure in the following section.
The internal
Terminologies and metadata
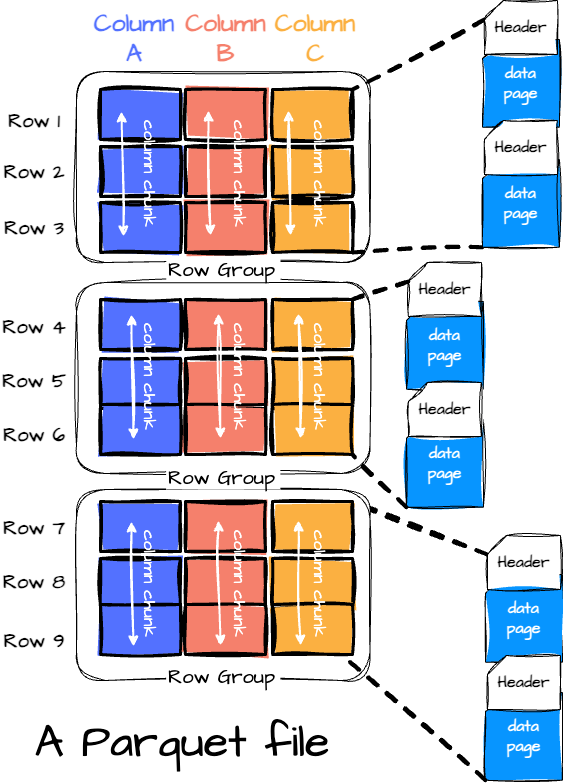
A Parquet file is composed of:
Row Groups: Each row group contains a subset of the rows in the dataset. Data is organized into columns within each row group, each stored in a column chunk.
Column Chunk: A chunk is the data for a particular column in the row group.
Pages: Column chunk is further divided into pages. A page is the smallest data unit in Parquet. There are several types of pages, including data pages (which contain the actual data), dictionary pages (which contain dictionary-encoded values), and index pages (used for faster data lookup).
Parquet is a self-described file format that contains all the information needed for the application that consumes the file. This allows the software to efficiently understand and process the file without requiring external information. Thus, the metadata is the crucial part of Parquet:

Magic number: The magic number is a specific sequence of bytes (
PAR1) located at the beginning and end of the file. The number is used to verify if it is a valid Parquet file.FileMetadata: Parquet stores FileMetadata in the footer of the file. This metadata provides information like the number of rows, data schema, and row group metadata. Essentially, each row group metadata contains information about its column chunks (ColumnMetadata), such as the encoding and compression scheme, the uncompress/compress size, the page offset, the number of values, and the min/max value of the column chunk. When navigating the Parquet file, the application can use information in this metadata to limit the data scan; it can prune unnecessary row groups based on the filter or choose to read only required columns.
PageHeader: The page header metadata is stored with the page data and includes information such as value encoding, definition encoding, and repetition encoding. In addition to the data values, Parquet also stores definition and repetition levels to handle nested data. The application uses the page header to read and decode the data.
Google Dremel (the query engine behind BigQuery) inspired Parquet’s approach to implementing nested and repeated field storage. In a 2010 paper introducing Dremel, Google detailed its method for efficiently handling nested and repeated fields in analytics workloads using definition level (for nested fields) and repetition level (for array-like fields). I wrote an article about this approach seven months ago; you can read it here:

To better understand how Parquet stores data behind the scenes, I wrote a Python program to write a Pandas dataframe to a Parquet file and read this file back using fastparquet. I tried to keep the process simple to grasp the idea quickly. So, there weren’t any configurations like parallelism in the file writing process that wrote a 10-row dataframe into a single Parquet file. The reading process is also simple. I read this file without any parameters except for the file path.
In the following section, I will deliver my understanding of the process of Parquet writing and reading data.
How is data written in the Parquet format?
I will use the term "Parquet Writer" to refer to the process responsible for writing data in the Parquet format.
Here’s the overview process when writing a dataset into a parquet file:
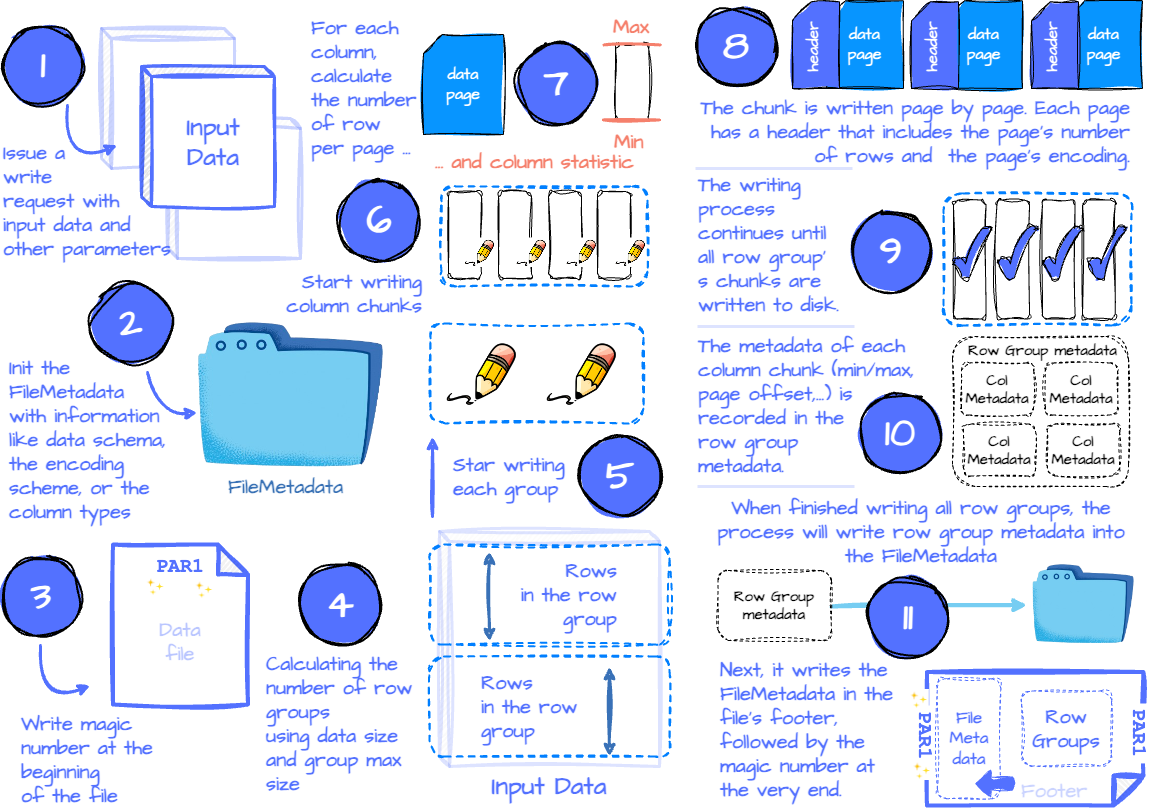
The application issues a written request with parameters like the data, the compression scheme for each column (optional), the encoding scheme for each column (optional), the file scheme (write to one file or multiple files), custom metadata, etc.
The Parquet Writer first collects information, such as the data schema, the null appearance, the encoding scheme, and all the column types, which are recorded in FileMetadata.
Next, the Writer writes the magic number at the beginning of the file.
Then, it calculates the number of row groups based on the row group’s max size (configurable) and the data’s size. This step also determines which subset of data belongs to which row group. After that, it starts the physical writing process for each row group.
For each row group, it iterates through the column list to write each column chunk for the row group. This step will use the compression scheme specified by the user (the default is none) to compress the data when writing the chunks.
The chunk writing process begins by calculating the number of rows per page using the max page size and the chunk size. Next, it will try to calculate the column's min/max statistic. (This calculation is only applied to columns with a measurable type, such as integer or float.)
Then, the column chunk is written page by page sequentially. Each page has a header that includes the page’s number of rows, the page’s encoding for data, repetition, and definition. If dictionary encoding is used for that column, the dictionary page is stored before the data page. A dictionary page also has the associated page header.
After writing all the pages for the column chunk, the Parquet Writer constructs the column chunk metadata for that chunk, which includes information like min/max of the column (if has), total_uncompressed_size, total_compressed_size, the first data page offset, the first dictionary page offset.
The column chunk writing process continues until all columns in the row group are written to disk, ensuring that the column chunks are stored contiguously. The metadata for each column chunk is recorded in the row group metadata.
After writing all the row groups, all row groups’ metadata is recorded in the FileMetadata.
The FileMetadata is written to the footer.
The entire process finishes by writing the magic number at the end of the file.
How about the reading process?
I will use the term "Parquet Reader" to refer to the process responsible for reading Parquet data file.
Here’s the overview process when reading a parquet file:
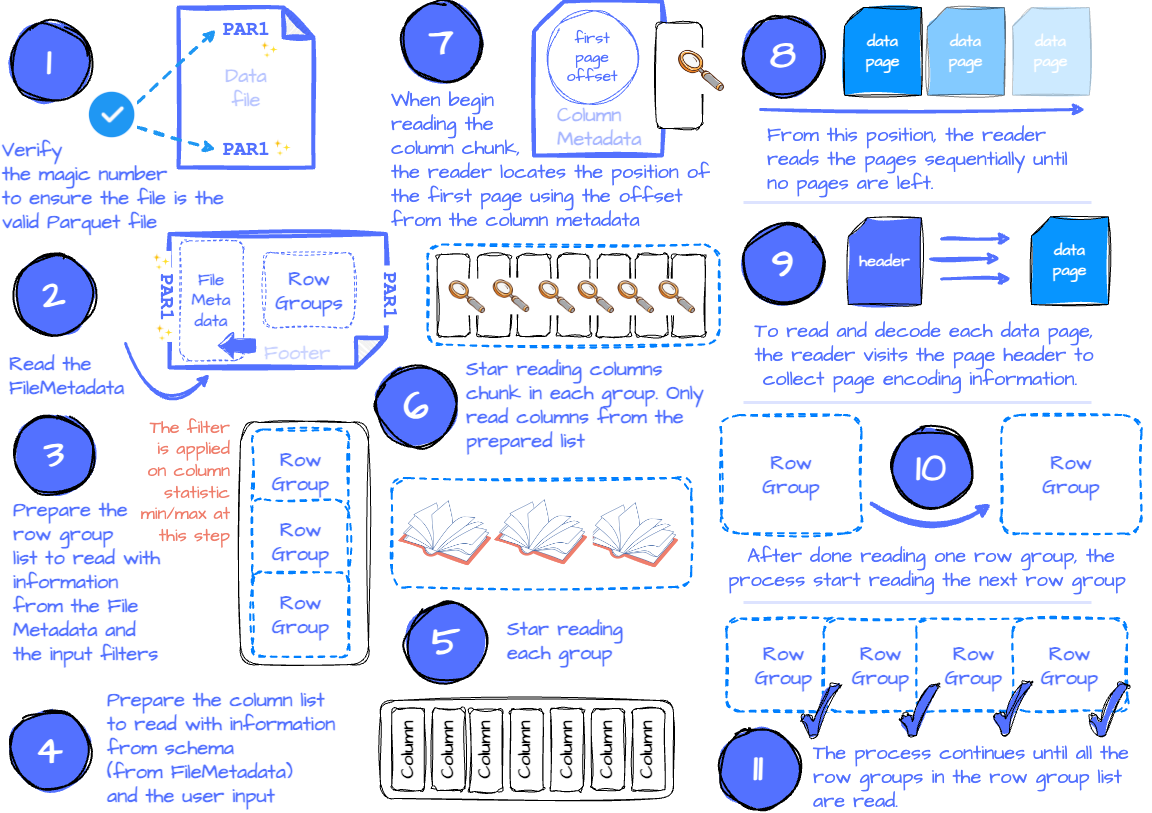
The application issues a read request with parameters such as the input file, filters to limit the number of read row groups, the set of desired columns, etc.
If the application requires verification that it’s reading a valid parquet file, the reader will check if there is a magic number at the beginning and end of the file by seeking the first and last four bytes.
It then tries to read the FileMetadata from the footer. It extracts information for later use, such as the file schema and the row group metadata.
If filters are specified, they will limit the scanned row groups. This is because the row groups contain all the column chunks’ metadata, which includes each measurable column chunk’s min/max statistics; the reader only needs to iterate to every row group and check the filters against each chunk’s statistic. If it satisfies the filters, this row group is appended to the list of row groups, which is later used to read. If there are no filters, the list contains all the row groups.
Next, the reader defines the column list. If the application specifies a subset of columns it wants to read, the list only contains these columns. Otherwise, the list contains all the columns.
The next step is reading the row groups. The reader will iterate through the row group list and read each row group.
The reader will read the column chunks for each row group based on the column list. It used ColumnMetadata to read the chunk.
When reading the column chunk for the first time, the reader locates the position of the first data page (or dictionary page if dictionary encoding is used) using the first page offset in the column metadata. From this position, the reader reads the pages sequentially until no pages are left. To know if there is any remaining data, the reader keeps track of the current number of read rows and compares it to the chunk’s total number of rows. The reader has read all the chunk data if the two numbers are equal.
To read and decode each data page, the reader visits the page header to collect information like the value encoding, the definition, and the repetition level encoding.
After reading all the row group’s column chunks, the reader moves to read the following row groups.
The process continues until all the row groups in the row group list are read.
Observation
My observation along the way
Multi-files
The application can specify the writing process to output the dataset into multiple files or even specify the partition criteria so that the process can organize the parquet output files into Hive partition folders. For example, all data on 2024-08-01 is stored in the folder date=2024-08-01, and all data on 2024-08-02 is stored in the folder date=2024-08-02.
Parallelism
Because the Parquet file can be stored in multiple files, the application can read them simultaneously with multi-threading.
In addition, a single Parquet file is partitioned horizontally (row groups) and vertically (column chunks), which allows the application to use multi-thread to read data in parallel to the read on the row group or column level.
Encoding
Data from a column chunk in Parquet is stored closed together in a row group. This helps Parquet encode the data more efficiently because data in the same column tend to be more homogeneous and repetitive.
Parquet leverages techniques like dictionary encoding and run-length encoding (RLE) to significantly reduce storage space. After dictionary encoding, the data is further run-length encoded in Parquet.

Dictionary encoding replaces repeated values with shorter, unique keys, reducing redundancy and improving compression. As far as I know, dictionary encoding is implemented by default in Parquet. It will be applied if the data satisfies a predefined condition (such as the number of distinct values).
RLE, on the other hand, compresses consecutive identical values by storing the value once along with its repetition count. These methods minimize the amount of data stored and optimize read performance by reducing the amount of data that needs to be scanned.
OLAP workload
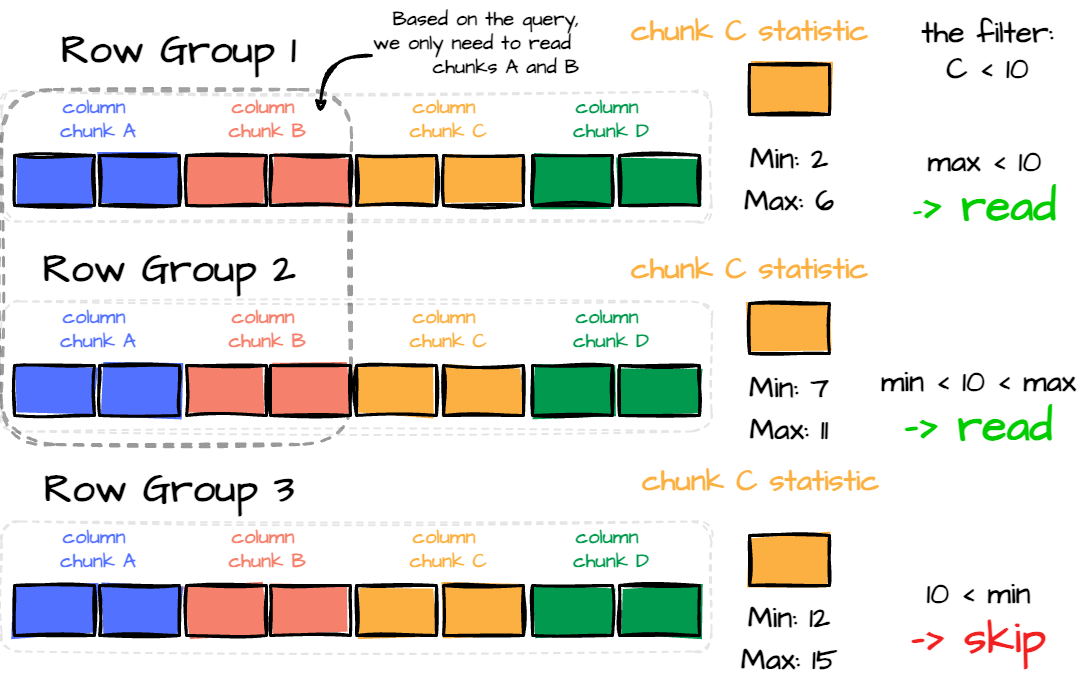
The ability to filter row groups using statistics and choose only the columns needed to read can significantly benefit the analytic workload. Giving the following query:

With the following Parquet layout, we only need to read row groups 1 and 2, focusing on columns A and B in each row group rather than reading all columns.
Outro
Above is everything I learned about the Parquet. I plan to write more deep-dive articles related to this file format in the future. So stay tuned for my upcoming works ;)
By the way, I’ve limited experience with Parquet, so I might not have a broader perspective on this format. If you find I missed something or want to discuss it further, please comment or contact me directly through LinkedIn, Email, or Twitter.
References
[1] Anastassia Ailamaki, David J. DeWitt, Mark D. Hill, Marios Skounakis, Weaving Relations for Cache Performance
[3] Wes McKinney, Extreme IO performance with parallel Apache Parquet in Python (2017)
[4] Michael Berk, Demystifying the Parquet File Format (2022)
[5] fastparquet source code GitHub repo
Before you leave
If you want to discuss this further, please leave a comment or contact me via LinkedIn, Email, or Twitter.
It might take you five minutes to read, but it took me more than five days to prepare, so it would greatly motivate me if you considered subscribing to receive my writing.
I've been blogging for years at articles.Analytics.Today, and it's terrific to find a fellow tech enthusiast with a real passion and skill for writing. Superb post. I'll include a link to this in my next article - on how Snowflake works with Apache Iceberg over Parquet. Well done!
Truly awesome post, explaining in detail about parquet. Thanks a million for sharing.