
Quick insights on materialized views
Things I observed that could help you work with materialized views more efficiently.

I invite you to join my paid membership list for only 7$/month (pay annually) to get access to:
200+deep-dive data engineering articles
learn-spark: a CLI tool to master Apache Spark internals
learn-dbt: a CLI tool to master dbt from the ground up
All future learning tools → Tools Demo
If you’re a student with an education email, use this 50% ANNUAL DISCOUNT
If you’re a Vietnamese user, please DM me for an upgrade due to payment issues. As compensation for the inconvenience, you’ll get 50% OFF the annual plan.
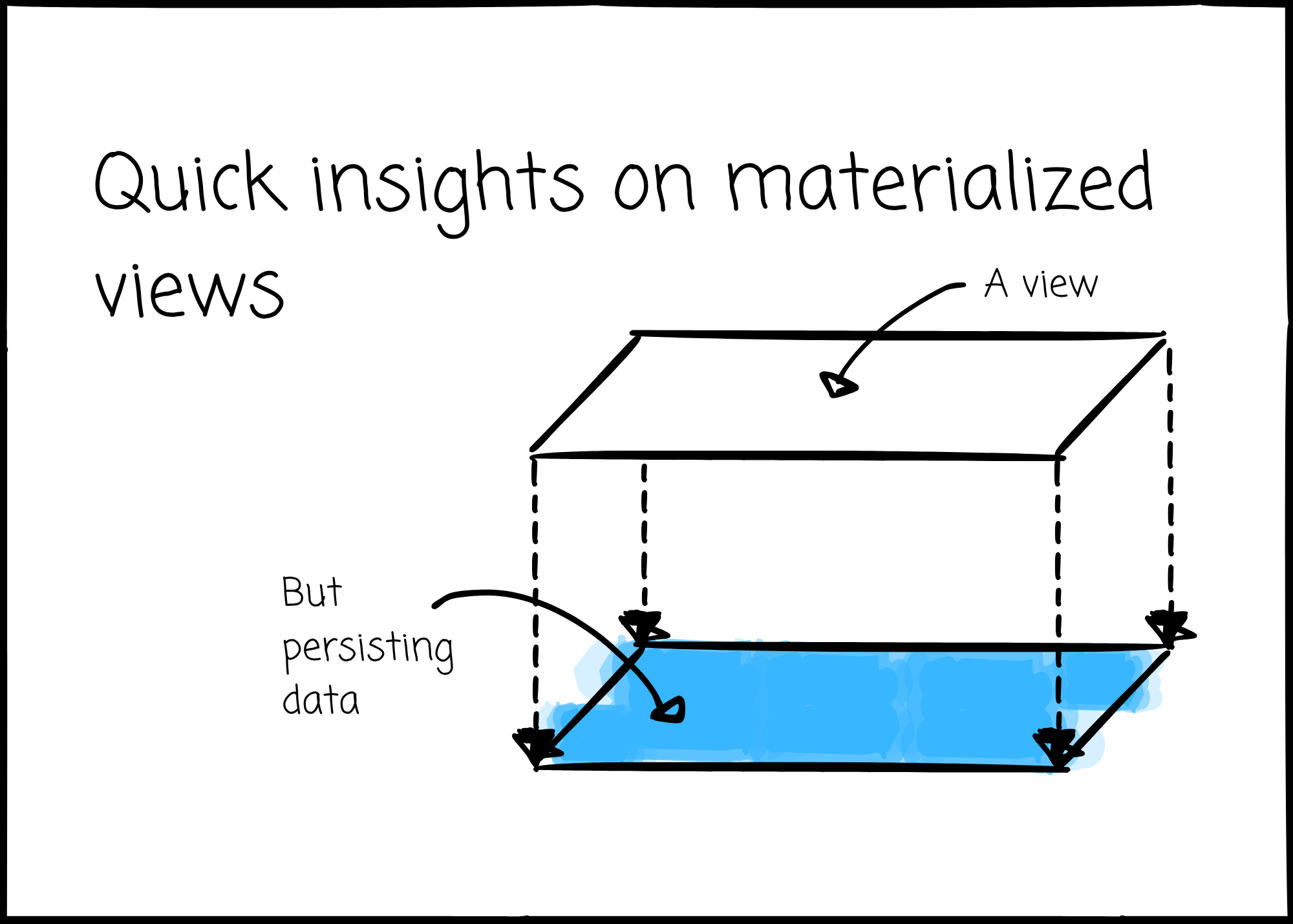
Intro
As data engineers, we have to work with … data.
Essentially, it is a set of digital bits 0s and 1s. However, we rarely see them in that form. We see them as files (e.g., Parquet, CSV) or as a higher abstraction: rows and columns in the two-dimensional tabular representation.
For 80%, you see that representation as a table or view. The difference is that the first is written to disk, while the latter is just a query that produces the tabular representation when executed.
For 20%, you have to deal with “the son” of the table and the view: the materialized view (MV). However, that doesn’t mean a materialized view is less useful than a table or a view; MV can shine only when you use it for the right use cases.
I make up the statistics :d
In this article, I discuss something I observed on materialized views.
What is it?
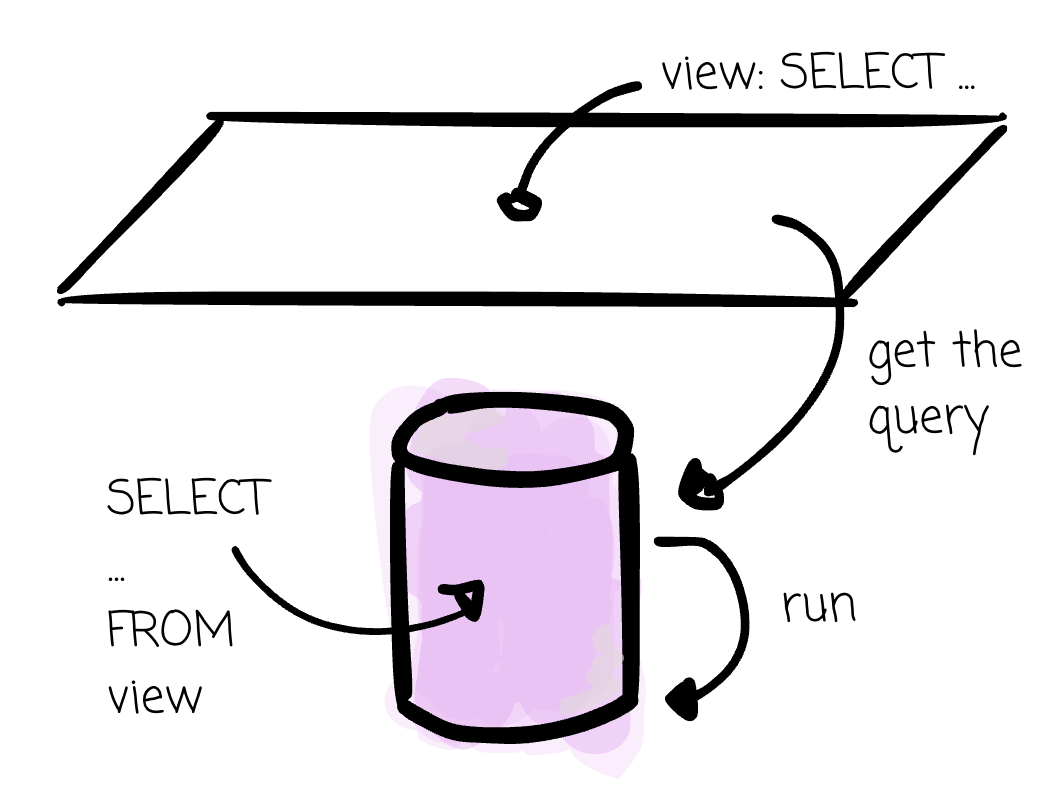
A view is simply a saved SQL query. Every time you query it (FROM), the database runs the query, gets the result, and continues the next instruction in your submitted logic.
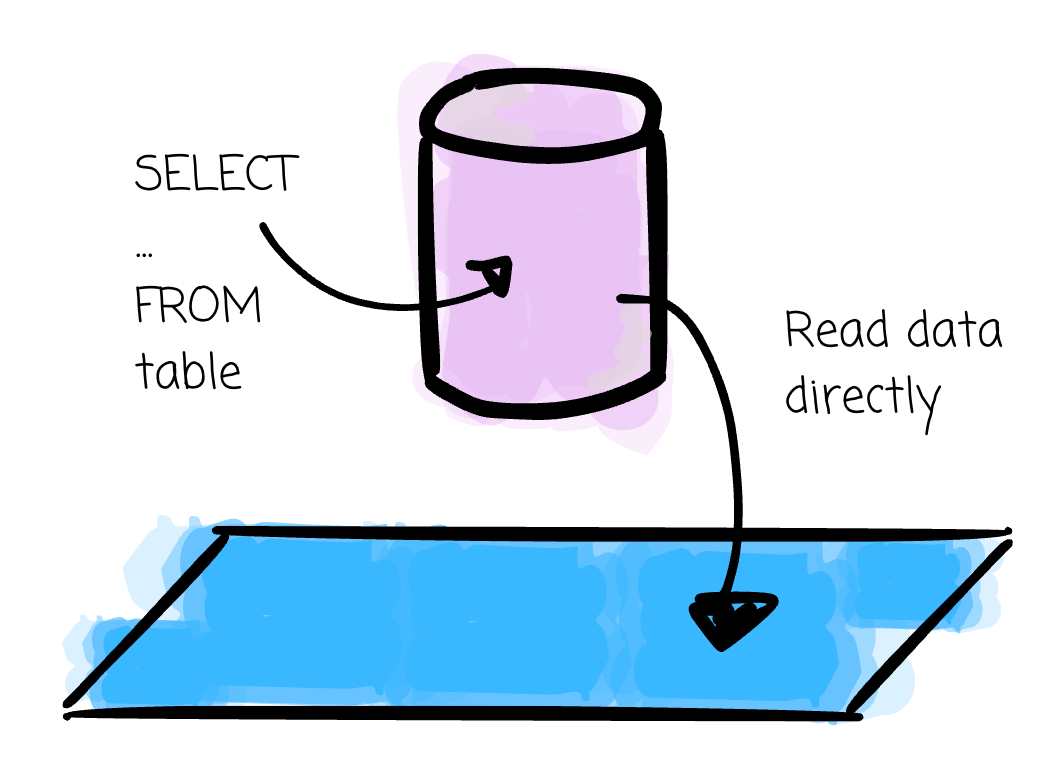
A table actually stores data on disk. You can create an empty table from a query result or from an input data file. You keep it up to date by executing INSERT, UPDATE, or DELETE.
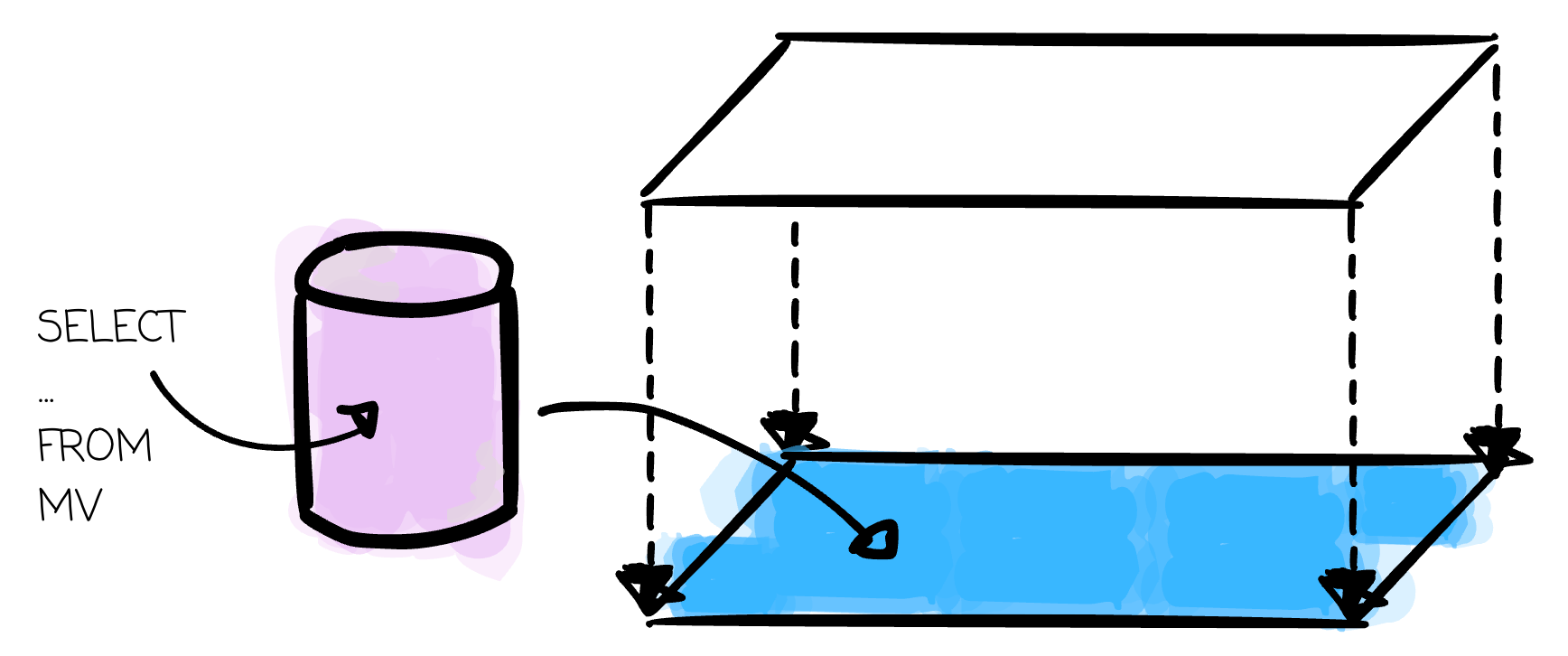
An MV is like their son. It is a pre-computed query result stored as a physical table. It is aware of the query, like the view, but also stores the data like a table. User can refresh the MV when the source data changes (i.e., the reference data in the view logic)
—
In software engineering, a cache is a fast data store layer (e.g., RAM) that holds a subset of data, so that subsequent requests for that data are served faster than accessing its original location (e.g., disk, object storage, or a complex database query).
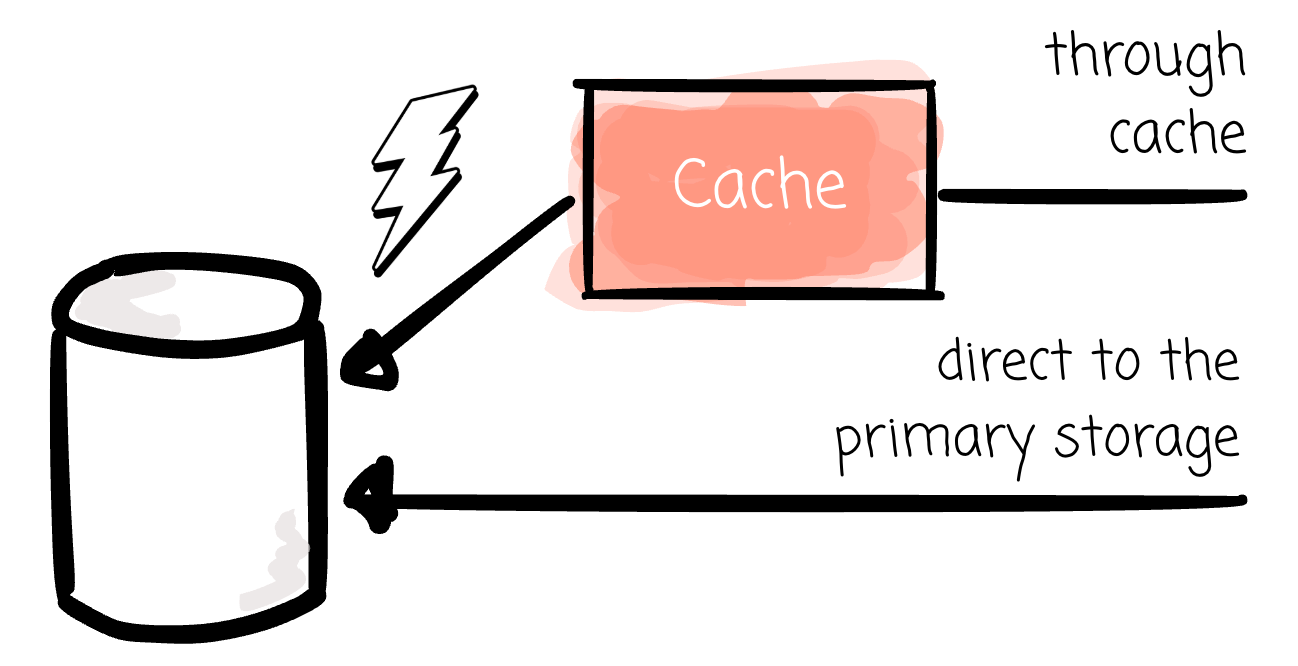
In some ways, the materialized view can be considered a cache, as it helps queries run faster by accessing computed data (the view result) and avoiding access to the data’s “original location” (source tables).
As with any cache, the challenge is to prevent it from becoming outdated. For the MV, the specific problem is how to keep it up to date with the source table(s).
I invite you to join my paid membership list for only 7$/month (pay annually) to get access to:
This article and 200+deep-dive data engineering articles
learn-spark: a CLI tool to master Apache Spark internals
learn-dbt: a CLI tool to master dbt from the ground up
All future learning tools → Tools Demo
If you’re a student with an education email, use this 50% ANNUAL DISCOUNT
If you’re a Vietnamese user, please DM me for an upgrade due to payment issues. As compensation for the inconvenience, you’ll get 50% OFF the annual plan.
Incremental View Maintenance (IVM)
When you create a materialized view, the database runs your query once and stores the output on disk. From that point on, queries hit the stored result instead of recomputing from the base tables. The interesting question is what happens when the bases change.
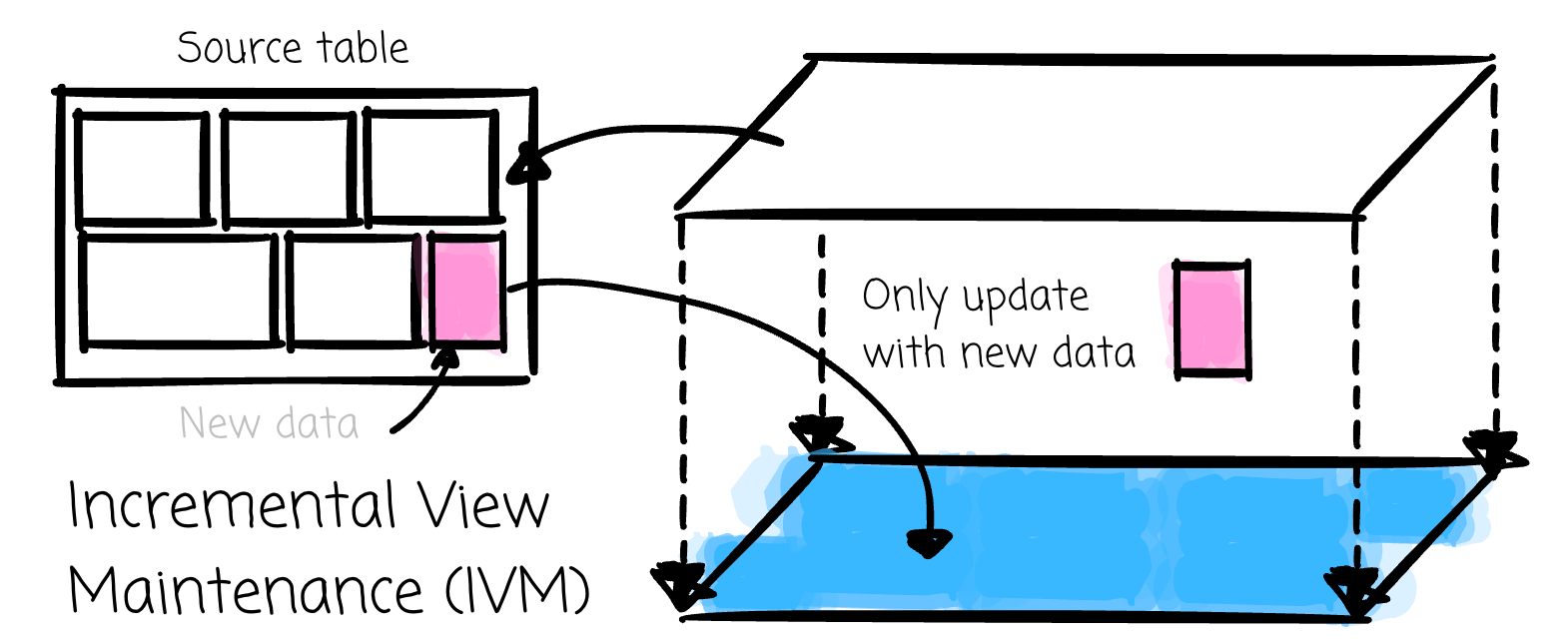
The simplest way is to recompute everything if the sources change; however, the cost will be high, plus the latency will increase.
So, a more reasonable way is to “we just refresh a piece that is affected by the change. “ But how do databases do that efficiently. This approach has a name: Incremental View Maintenance (IVM), and it has been studied for some time.
—
There are three main modern IVM approaches:
Note 1: Not all databases implement one of these approaches. A database can maintain the MV in its own way.
Note 2: I can’t find any materials on how cloud data warehouses, such as BigQuery, Snowflake, or Redshift, actually maintain incremental MVs.
Let’s briefly discuss these three approaches.
One reason I am delaying writing an article on materialized views is that these approaches are so math-heavy and complex to understand. So, forgive me if you see anything missed in this section, as I only tried to deliver the general ideas of these approaches.
Timely Dataflow (TD)
The Naiad paper introduces Timely Dataflow as a general computational model, a low-level substrate on which many higher-level systems can be built. Its goal is to deliver the high throughput of batch processors, the low latency of stream processors, and the ability to perform iterative computation in a single framework.
Before Naiad, applications needed 3 systems for that.
Every message in the system carries a logical timestamp. TD API has four methods:
Send a message
Receive a message
Request a notification at a given timestamp
Receive that notification.
The notification pair is the key mechanism. A node can tell the system: “notify me when timestamp t is complete.” The system then tracks across the entire distributed cluster to determine whether any messages belonging to that timestamp could still arrive.
Only when the system ensures that no messages will arrive does it fire the notification. The tracking happens separately from the data stream itself. This means multiple tasks can process different points in time concurrently.
TD was designed to support deeply nested iterative algorithms, such as graph processing. That’s a powerful, but most SQL MVs don’t have a loop. What matters here is the notification guarantee. It’s the mechanism that tells the system when a given version of a view is complete and safe to emit.
Differential Dataflow (DD)
DD is a programming model built directly on top of Timely Dataflow (TD). It tries to answer: given that we know when a computation is complete, how do we compute as little as possible as the input changes?
The general idea is that DD tracks data states as multiple versions and uses the TD’s timestamp to order them. Thanks to this ordering, the system can save cost by reusing computations when updates arrive.
DBSP
DBSP takes a different approach from the two previous ones.
Rather than building upward from the dataflow substrate, it borrows from Digital Signal Processing, the mathematics of circuits and signals.
A database is a stream of snapshots. Changes to the database are a stream of deltas. A view is a query applied to each snapshot. Maintaining the view incrementally means computing the stream of view deltas from the stream of database deltas.
DBSP formalizes this with four operators: lift, delay, and two operators for recursive programs. They are functionally complete for all relational operations in SQL: it can take any standard SQL query and automatically convert it into an incremental version.
Putting the IVM theories aside, let's ask a more practical question:
What are the MV’s trade-offs?
The MV can speed up your queries, but it’s not free.
In this section, let’s discuss the MV’s trade-offs so we can use them wisely.
I believe every MV decision comes down to two questions:

How fresh does your data need to be?
What are you willing to pay for it?
Let’s think of it this way: leverage an MV move the hard words from read time to write (update) time. You’re not making queries faster without any cost; you’re paying for the computation in advance, at refresh time, so that the read operations can be boosted.
The higher the freshness, the more frequently the MV is refreshed. Which means you pay a higher cost (for more frequent refreshes) to update the data:

Full refresh keeps things simple. Recompute everything on a schedule, hourly, daily, whatever fits. Predictable, easy to reason about. But stale between runs, and expensive if the dataset is large. You’re paying the full compute cost every refresh.
Incremental refresh (IVM, as we discussed in the previous section) improves the compute efficiency here. Instead of recomputing everything, process only what has changed. This makes more frequent refreshes affordable; the cost per refresh drops significantly when changes are small relative to the full dataset. However, IVM doesn’t make freshness free. The compute cost still correlates to the update frequency.
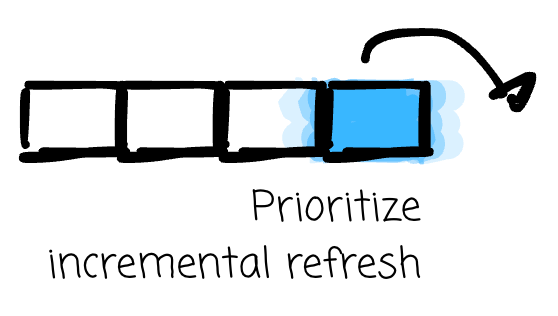
If you choose to use a materialized view, just check whether your database supports incremental refresh. ClickHouse, Databricks, BigQuery, and Snowflake(?) support it. If your use case can leverage incremental refresh, prioritize it, as it helps make the refresh process more efficient.
However, as I understand it, incremental refresh MV doesn’t support certain SQL operations. For example, BigQuery MV can be incrementally updated if the MV’s query is a JOIN and the right side has new data.
For the cost-freshness trade-offs. There is no absolute recommendation here as it depends entirely on your use cases. A financial fraud detection system has a very different freshness requirement from that of an hourly report dashboard.
MVs in stream processing
In real-time processing use cases, where data keeps coming in, and you need to extract insight from that stream as fast as possible, you need to consume the data, process it, and output the result as fast as possible.
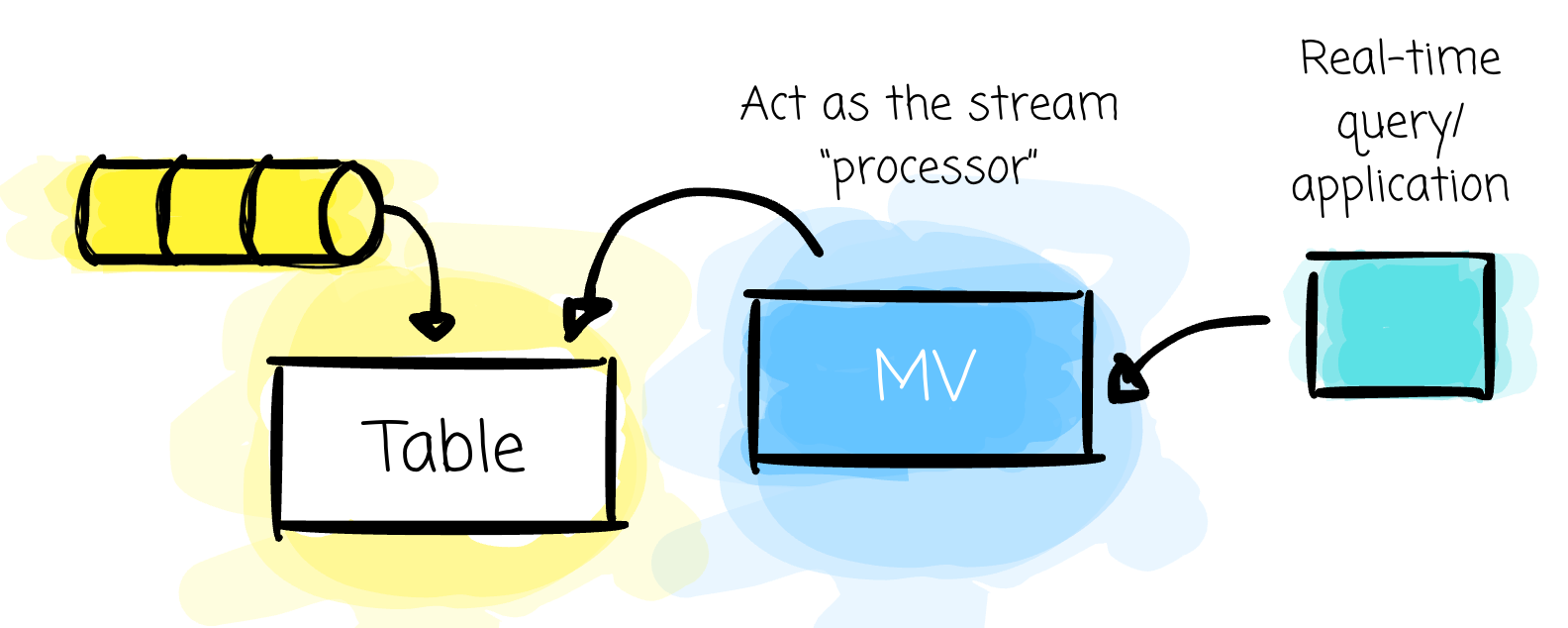
Imagine we land the stream into a table, define an MV on top of it, and make the MV refresh as quickly as the latency requirement allows to apply the process logic to new data.
Doesn’t that just achieve the purpose of a real-time processing use case?
—
The Flink Dynamic table is implemented based on the idea of an MV

A dynamic table is a table that changes over time as its underlying stream evolves. When you run a SQL query over a dynamic table, you get a continuous query, a query that never terminates, continuously updating its result as the input changes. That result is itself a dynamic table. A continuous query on a dynamic table is semantically equivalent to a materialized view with eager view updating.
—
RisingWave, a streaming OLAP database, is built around the same principle. Its materialized views are maintained incrementally: when source data changes, RisingWave uses the stream of changes flowing through its dataflow graph to update only the affected rows, keeping the view fresh without full re-computation
—
A ClickHouse incremental materialized view is a trigger that runs a query on a subset of data as it's inserted into a table. The result is inserted into the different table. When more data arrives, new results will be sent to this table and merged with the existing data. This merged result is semantically equivalent to running the query over all the source data.
ClickHouse treats its MV as a stream processor in real-time analytics use cases.
—
MV is an important concept in the real-time/stream processing world: they are now updated not only periodically or on demand, but also in the background to keep pace with incoming data.
So the next time you see a real-time processing use case, put your database MV on the consideration list, alongside stream processing like Apache Flink or a specialized database like Pinot, as the MV offers simplicity with SQL syntax and lets you stay with your current database.
The only consideration now is whether you can achieve the desired data freshness at a meaningful (refresh) cost trade-off. When the MV can’t serve your use case (e.g., some MV implementations don’t fully support capturing changes from all tables in the join logic), moving to more complex solutions like Flink is not too late.
Outro
In this article, I delivered my understanding and observation on MV, including what it is, how it works (the IVM), its trade-offs, and its role in real-time/stream processing.
Thank you for reading this far.
See you in my next article.
Reference
[1] Chris Riccomini, Everything You Need to Know About Incremental View Maintenance, 2025
[2] Tyler Akidau, Slava Chernyak, Reuven Lax, Streaming Systems (2018)