
Partitioning and Clustering
8 minutes to understand the two most popular OLAP performance-optimized techniques.

I will publish a paid article every Tuesday. I wrote these with one goal in mind: to offer my readers, whether they are feeling overwhelmed when beginning the journey or seeking a deeper understanding of the field, 15 minutes of practical lessons and insights on nearly everything related to data engineering.
I invite you to join the club with a 50% discount on the yearly package. Let’s not be suck as data engineering together.

Intro
In OLTP databases, indexes boost point look-up queries. When you use WHERE username = “bruce_banner,” the index will tell you where to find records with the username “bruce_banner.”
However, the typical workload in OLAP databases is different. Business users typically need to analyze and extract insights from historical data, whether from a week, a month, a year, or even longer periods.
Look-up index won’t help much in such a workload.
Scanning less data is a more viable option. Columnar storage allows the engine to read the required columns without touching others. Although this new layout helps, researchers want to skip irrelevant data at a finer-grained level.
To achieve that, I observed that there are two popular techniques: partitioning and clustering. This article will delve into them.
Partitioning
Essentially, partitioning divides a dataset into smaller portions. Its ultimate goal is to reduce data scanning by skipping irrelevant portions. There are two approaches: horizontal and vertical partitioning.

Column storage (e.g., ClickHouse) is a form of vertical partitioning where each column is stored independently, allowing for the efficient skipping of unnecessary columns. For the hybrid format (e.g., Snowflake, BigQuery, Parquet), although the data is still vertically partitioned, it is not entirely separate from one another.

This format first horizontally partitions the data into row groups (e.g., referred to as row groups in Parquet), and within each row group, the data is vertically partitioned. This ensures that the column’s values from the same row will be stored close together in the same row groups while storing data in a columnar fashion. The system doesn’t have to scan over the disk to consolidate data from a row.

From now on, I will use the term "partitioning” to refer to the horizontal partitioning
That is partitioning at the file level.
BigQuery, Clickhouse Iceberg, Hudi, Hive, Delta Lake, or other OLAP systems allow users to partition data at a higher level. We can specify a column so the system can break the data using the value from this column to partition the table into smaller ones. A date column will break the table into partitions for 2025-05-01, 2025-05-02, 2025-05-03, and so on.

Partitioning helps the system operate only on the relevant portion. If it identifies the required row groups in the Parquet files, it can ignore all other groups. If a query includes a filter predicate on the partition key (e.g., WHERE date=2025-05-01), the query optimizer can identify that only partition date=2025-05-01(given the table is partitioned by the day column) is relevant and can completely ignore, or "prune," all others.
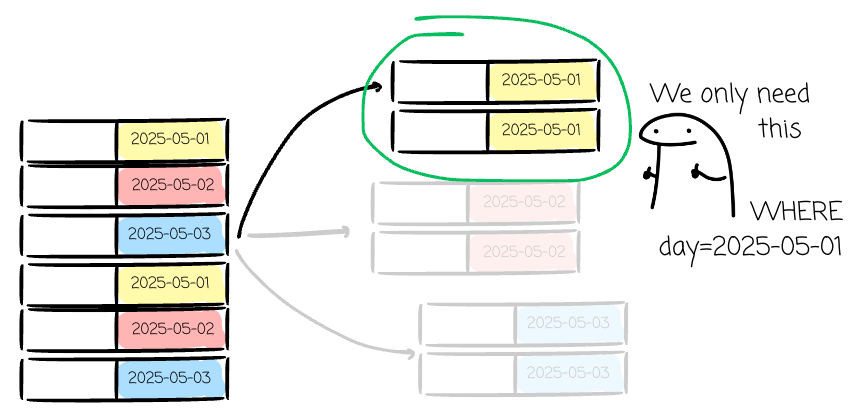
Although the simplicity, the act of eliminating entire partitions from consideration drastically reduces the volume of data that the query engine needs to read, write, and manage.
How does it usually work
Most of the systems will let you specify the column to partition the table (except for Redshift, which does not support partitioning).

BigQuery treats a partition as a virtual table. Data from a partition will be stored separately from the data of other partitions. This allows features like data expiration, data insertion, and data deletion to be executed effectively at the partition granularity (because it’s similar to a table). Each partition will have its associated metadata, allowing the engine to leverage it.
Clickhouse also treats each partition as an independent portion, allowing Clickhouse to write, manage, and query data independently.
For Snowflake, things got different, instead of letting the user specify the partition as the unit of data management. Snowflake automatically splits the tables into micro-partitions, each of which stores between 50 MB and 500 MB of uncompressed data.

The micro partitions are organized similarly to the hybrid format, in which a partition contains a group of rows, and each column of data is stored together in each partition. Snowflake manages metadata for columns in the micro-partition to facilitate data management.
When explicitly managing the storage layer by yourself, we will observe a common approach to organizing data in a Hive-style manner, where data is organized into folders:
Table: Each table has a directory.
Partitions: Each table can have partitions. Each partition corresponds to a subdirectory.
This scheme is straightforward and has been widely adopted since its introduction. The later generation of table formats, such as Delta Lake, Iceberg, or Hudi, although users still see this partition scheme, they add more robust metadata behind the scenes to improve performance and efficiency.
Iceberg also has a feature called the hidden partition.
Users typically transform a column and use it as the partition key (e.g., partition by day requires transforming the timestamp column to a day and adding an extra column). Users must use this transformed column to benefit from partition pruning.
For example, a table is partitioned by day, and every record must have an extra partition_day column derived from the created_timestamp column. When users query the table, they must filter on the exact partition_day column so the query engine can prune unwanted partitions. If the user is unaware of this and uses the created_timestamp column instead, the query engine will scan the entire table.

Iceberg hidden partitions took another approach:
Instead of creating additional columns to partition based on transform values, Iceberg only records the transformation used on the column.
Thus, Iceberg can save storage cost because it doesn’t need to store extra columns

Additionally, Iceberg can address the challenge that traditional partitioning relies on the physical structure of the files; changing how the table is partitioned requires rewriting the entire table.
Apache Iceberg stores all the partition schemes. Given a table initially partitioned by the created_timestamp field at a monthly granularity, the transformation month(created_timestamp) is recorded as the first partitioning scheme.

Later, the user updates the table to be partitioned by created_timestamp at a daily granularity, with the transformation day(created_timestamp) recorded as the second partitioning scheme. Users don’t have to rewrite the whole table; tables from the past will still be kept in month partitions, while new data will be organized in date partitions.
Consideration
Choosing the right partition scheme for your workload is crucial.
A too coarse-grained scheme might cause the data pruning to be inefficient. Given that you mostly query at the date level, and the table is partitioned at the month level. A filter date of ”2025-05-01” might cause the engine to read the entire “2025-05” partition.
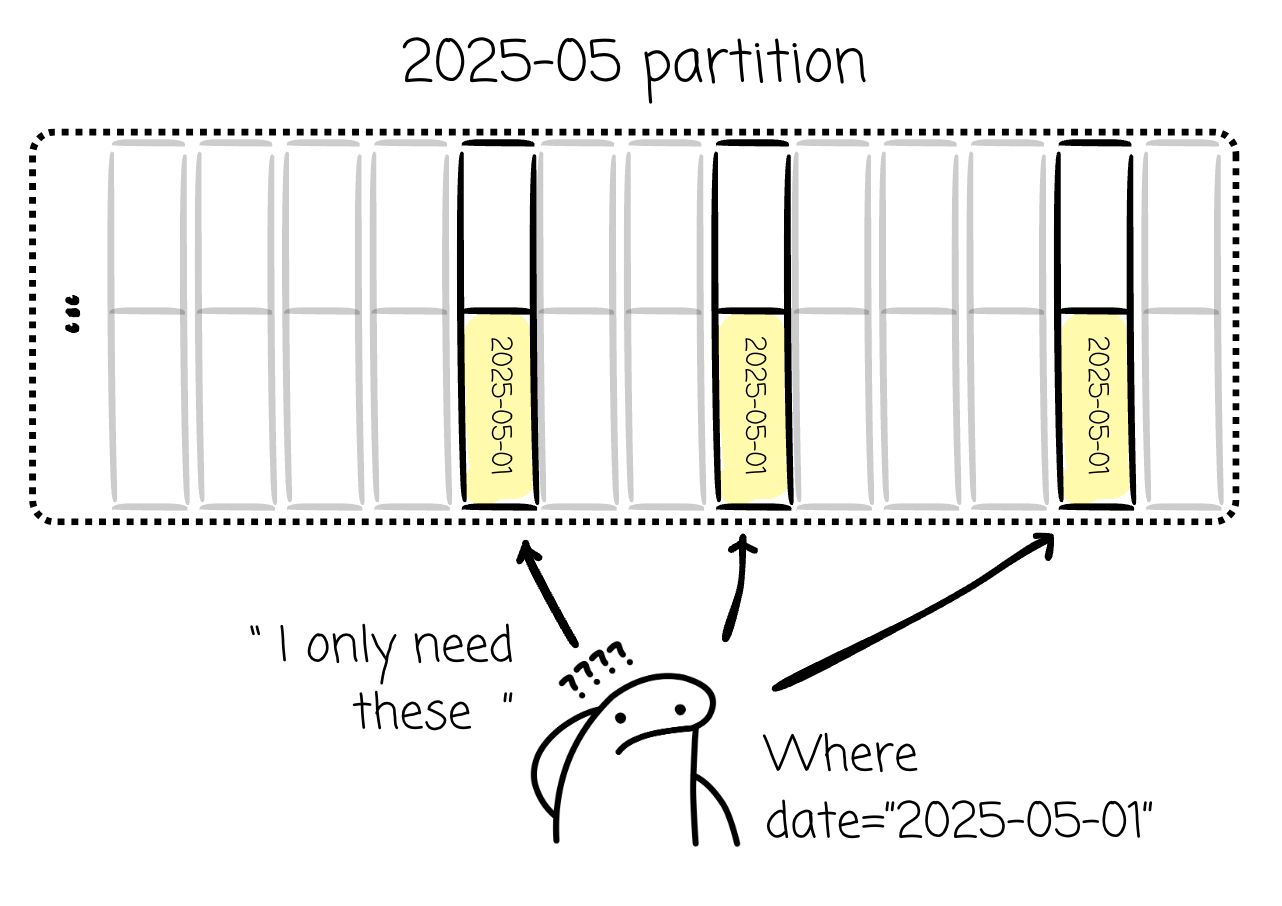
In contrast, a too fine-grained scheme might result in many partitions. This increases the overhead for the system, as each partition needs to be managed by an associated metadata. Too many partitions also degrade performance; a filter date of “2025-05-05” will touch 24 hourly partitions, and a filter of “2025-05“ will touch 720 ones.

Additionally, partitioning may cause data skew, as a single partition contains significantly more data than the others. For example, a sales day will have more activity than other days.
Thus, it is crucial to understand the pattern of how our data is used before defining the partition scheme. You need to collect and understand the requirements from your organization to make this decision.
Also, being aware of how your current system offers data partitioning. For example, Iceberg allows users to change the partition scheme without rewriting the entire table, providing sufficient flexibility to experiment with what works in your case or when your business requirements change frequently.
Or, if you’re using Snowflake, you don’t need to care about the partitioning as this cloud data warehouse will automatically handle it for you.
Clustering
Keep reading with a 7-day free trial
Subscribe to VuTrinh. to keep reading this post and get 7 days of free access to the full post archives.