
OLTP vs OLAP: Data Format and Indexing
In just 15 minutes, you will understand the difference in how they organize and find the data.

I will publish a paid article every Tuesday. I wrote these with one goal in mind: to offer my readers, whether they are feeling overwhelmed when beginning the journey or seeking a deeper understanding of the field, 15 minutes of practical lessons and insights on nearly everything related to data engineering.
Intro
A database management system (DBMS) is one of the most robust software systems that has ever been created. A simple interface that lets you input a SQL query and returns a result in 17 seconds usually gives us the perception that the database (DBMS) is a simple system.
That’s not true. I read somewhere that the database engineers are among the most talented software engineers. To build a system like PostgreSQL, MySQL, SQLite, DuckDB, Clickhouse, BigQuery, or Snowflake, the engineers have to take care of a lot of things behind the scenes.
From storing the data to parsing the query, planning and executing it, serving multiple clients as one, ensuring ACID, and many other aspects. As I know, most DBMS don’t rely on the OS for controlling physical resources like disk, RAM, or CPU, so the amount of work is even more for the engineers.
We, as data engineers, like any other end users, don’t usually have to deal with the super low-level details of a DBMS. Still, understanding the characteristics of the systems we’re working with will always be a good thing. Our primary goal is to ensure that data is stored, analyzed, and utilized efficiently within the organization.
In this article, I will delve into one of the most important aspects of a DBMS: how it stores the data. We will examine two types of DBMS, which are the two primary ones that a data engineer usually works with: the OLTP and OLAP. We will find out how they organize and find the data
Database vs database management system (DBMS)
A database is an organized and managed collection of data that models aspects of the real world. It can be as simple as a spreadsheet or a phone contact list.
A database management system (DBMS) is software that stores and analyzes information in a database. It supports the definition, creation, querying, updating, and administration of databases based on a data model.
Relational model
The model can take various forms—graph, key-value, document, or the most popular one, the relational model, first described by E.F. Codd in 1969. This model organizes data into structured tables, also known as relations, consisting of rows and columns.
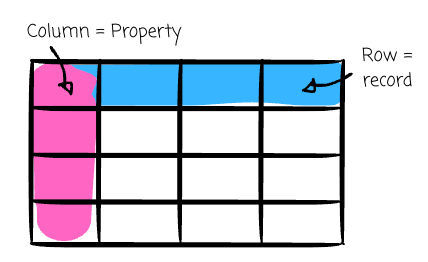
Each table represents a specific type of entity, such as 'users' or 'orders,' with rows (tuples) representing individual records and columns (attributes) defining properties of those records, like name, age, or order date.
The data model only enforces the logical representation of the data; it does not dictate how the DBMS stores the data physically. Relational DBMSs are free to determine the data layout on disk.
The workload of OLTP and OLAP systems
Data on disk is essentially just a series of 0s and 1s, and it is the DBMS's responsibility to organize and manage how this data is written to disk to ensure efficient write and read operations.
However, the efficiency of a data layout must be evaluated depending on the workload. Database workloads can generally be categorized into two main types:
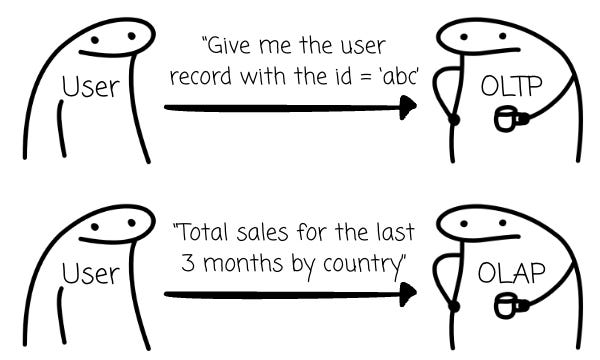
The OLTP workload ingests new information; its data operations mostly read/write/update a small amount of data each time. Typically, the OLTP system is first built in a company to capture information from the real world. Examples include the database behind web applications and the database that records banking transactions. The workload might be more familiar to those working closely with the company’s product/service, such as the backend developers.
The OLAP workload has different characteristics from the OLTP workload. Its queries require reading data from many tables (via joins). After obtaining the data, numerous aggregations may be necessary to extract insights or identify new patterns. In most cases, OLAP workloads are executed on data collected from OLTP systems. This workload might be more familiar to those in the company’s data analytics functions, such as data engineers or analysts.
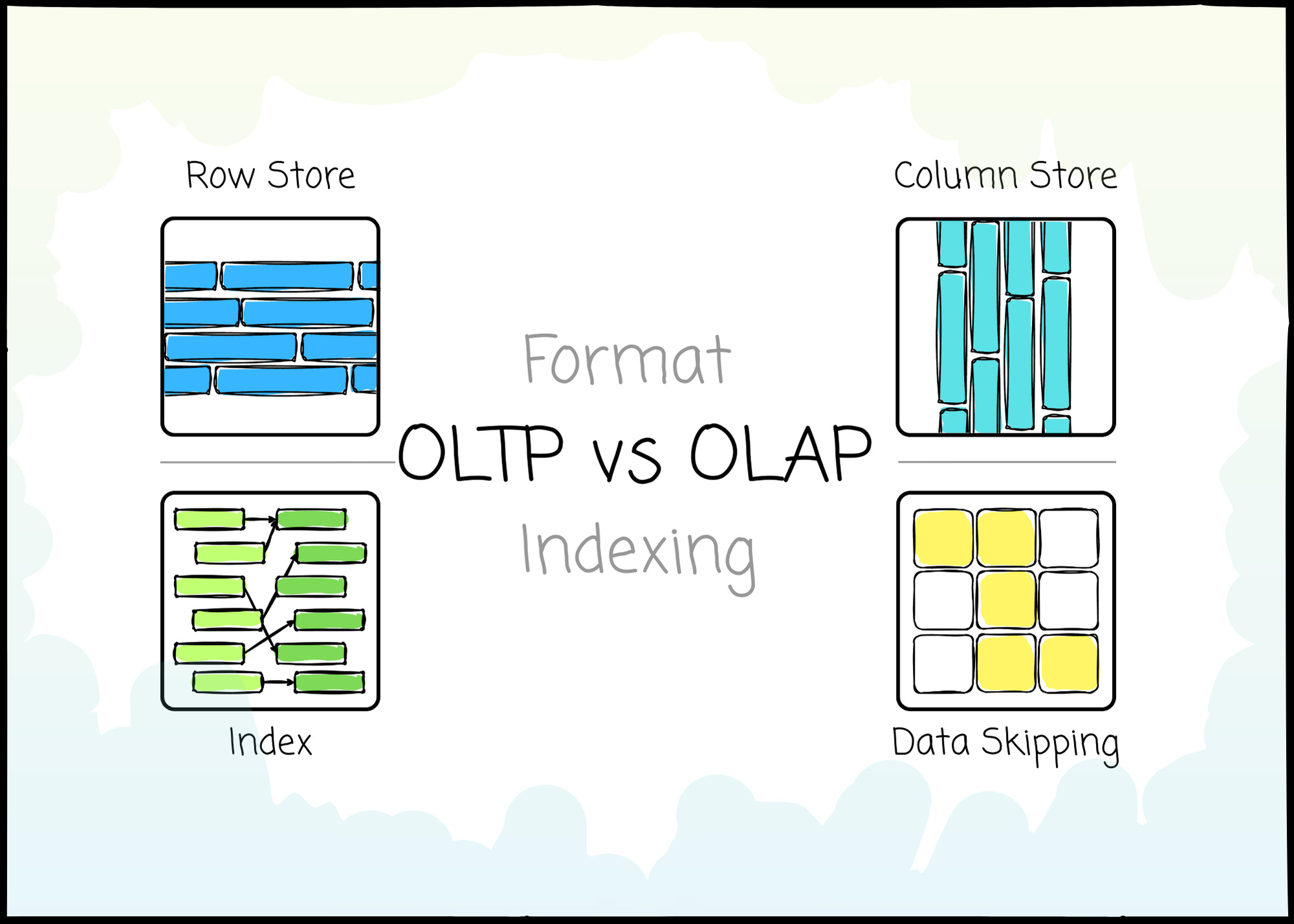
How do they organize the data?
The DBMS organizes data in a way that optimally benefits each workload. To achieve this, there are three storage models used for data organization:
The row store.
The column store.
The hybrid
OLTP
To serve its workload, most OLTP systems usually organize the data in a row-based fashion. The DBMS stores all the values of all columns for a single row together in a page.
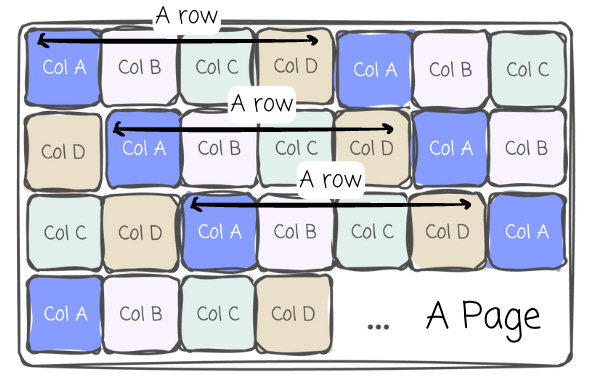
Note: The term 'page' refers to an atomic data unit; all data within a page is either read or written successfully, or none of the page's data is read or written. In a DBMS, a page can refer to hardware pages, OS pages, or database pages.
To align with the underlying hardware, the database page is typically a constant multiple of the 4KB hardware page. (e.g., 32KB). From the rest of the article, I use “page“ to refer to the database page.
From a data writing perspective, this is optimal when data needs to be written to the system as quickly as possible. For a single row, the writer needs to write the bytes from different columns sequentially (sequential operation is always fast).
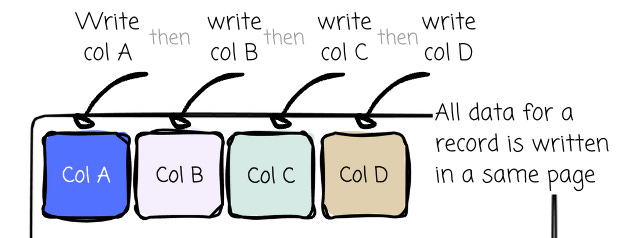
From the reading perspective, the data organization also serves well for the OLTP workload. A whole row usually needs to be read; again, the sequential operation can take place here as all of the bytes for a single row are stored together.
OLAP
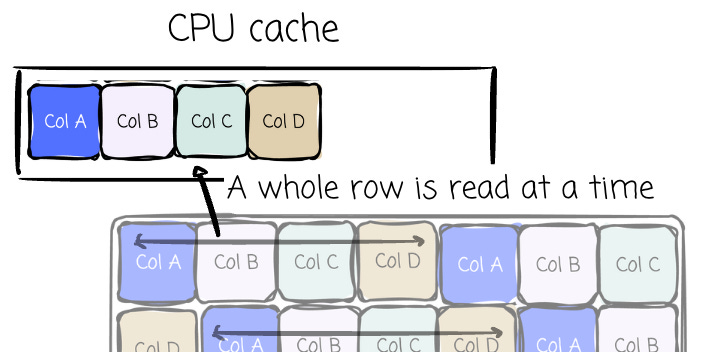
With OLAP, the workloads are different. Typically, the OLAP systems are more focused on the reading side, where a large amount of historical data needs to be brought up for aggregation and joins. In most cases, a subset of columns only needs to be scanned. This characteristic causes us issues when handling the OLAP workload on the OTLP system (which uses row-format storage).
Imagine we have a table with 10 columns. All column values from a single row are stored continuously. An OLAP query that reads two columns: date and sales, then calculates the SUM of sales by date.
With the row-store, we have to load the whole row into memory; only then can the system extract data from the two columns. Let’s say the table has 1 million rows; the system overhead should be huge.
The solution is to store data from a single column continuously. There are two main approaches: the column store and the hybrid.
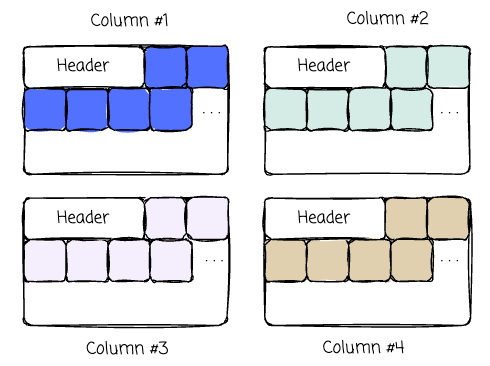
Column store
The first approach stores data from a single column separately. The problem from the example above is now solved; the system only needs to care about the pages that store data and sales data, thereby avoiding the loading of redundant data from other columns.
Keep reading with a 7-day free trial
Subscribe to VuTrinh. to keep reading this post and get 7 days of free access to the full post archives.