

To celebrate Lunar New Year (the true New Year holiday in Vietnam), I’m offering 50% off the annual subscription. The offer ends soon; grab it now to get full access to nearly 200 high-quality data engineering articles.

Intro
I’m a data engineer who wants to be involved in infrastructure. I enjoy diving into the systems side—setting up tools and controlling how everything operates. (I still need the help of the DevOps team sometimes :d)
That motivated me to self-learn Kubernetes (k8s) from the beginning of my career. (which is one of the wisest decisions I made).
Knowing k8s helps me greatly, from maintaining the current cloud deployment backed by k8s (e.g., Cloud Composer) to self-deploying data applications.
In this article, I will share my little knowledge of Kubernetes. We will start by revisiting the container concept and answering the question, “Why k8s? “Next, we will see a high-level overview of it. We will wrap up this article with my sharing to help you get started with k8s.
Containers
Containers are lightweight, portable ways to package and run applications. They bundle everything your application needs to operate, from the code to its dependencies, such as libraries and environment variables, ensuring it runs smoothly across different environments.
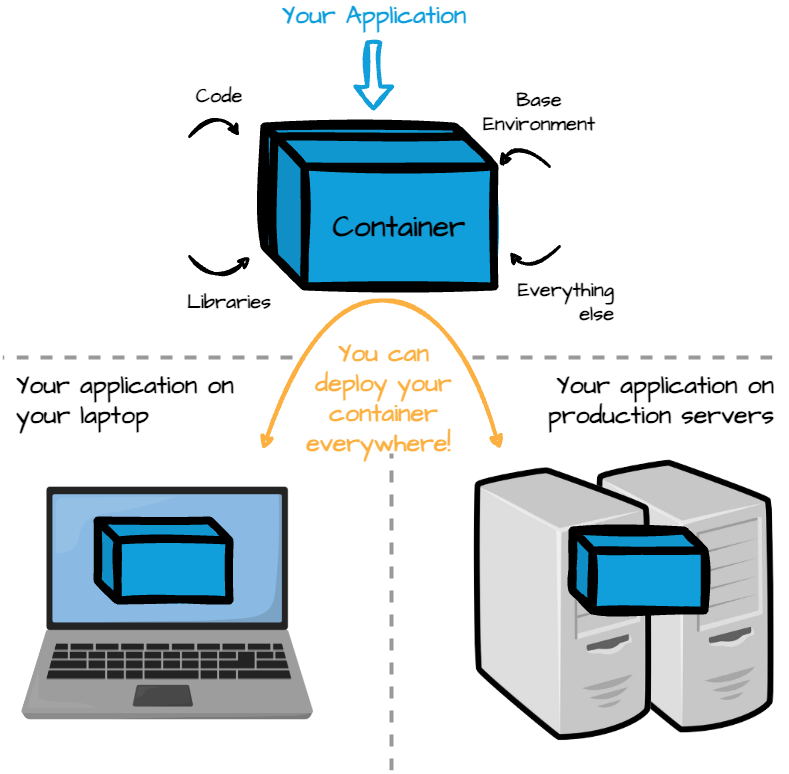
Docker is the most popular containerization platform, making creating and running containers easy. Running a few containers manually with docker-compose on a single server is acceptable, but what if you need to run hundreds or thousands of containers across multiple servers? How do you manage the container’s scaling and communication across servers?
This is where Kubernetes steps in, providing the tools and abstractions needed to manage containers at scale.
How Kubernetes Work
Kubernetes, often abbreviated as K8s, is an open-source platform designed to automate containerized applications' deployment, scaling, and operation. Initially developed by Google, it is now maintained by the Cloud Native Computing Foundation (CNCF).
At the heart of Kubernetes are controllers, which are control loops that monitor the state of your cluster and make adjustments to achieve the desired state. Here’s how they work:
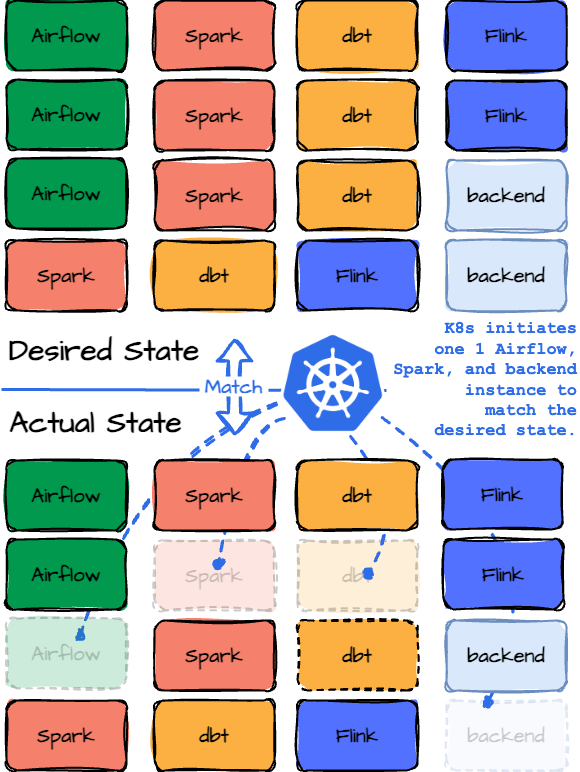
Desired State: In Kubernetes, you declaratively define your application's desired state. For example, you might specify that you want three web server instances running.
Actual State: Kubernetes continuously monitors the system's actual state. It checks the number of instances your application runs and compares this with the desired state.
Reconciliation Loop: If there’s a difference between the desired and actual states, the Kubernetes controller reconciles this difference. It might start a new instance, replace a failed one, or perform other necessary adjustments. This feedback loop ensures that your applications always run as intended.
To celebrate Lunar New Year (the true New Year holiday in Vietnam), I’m offering 50% off the annual subscription. The offer ends soon; grab it now to get full access to nearly 200 high-quality data engineering articles.
The overview architecture
A Kubernetes cluster consists of two main components: Control Plane and Worker Nodes.

Control Plane
The Control Plane manages the cluster's overall state and includes:
API Server: The central hub for all Kubernetes API interactions, validating and processing requests.
etcd: A key-value store holding the cluster’s configuration and state, ensuring consistency across the system.
Controller Manager: Runs controllers that monitor and reconcile the state of resources like Pods and Nodes to match the desired configuration.
Scheduler: Assigns Pods to Nodes based on resource availability and policies, optimizing workload distribution.
Cloud control manager: This component integrates cloud-specific control logic into Kubernetes. It connects your cluster to your cloud provider's API, separating cloud-specific interactions from cluster-internal ones. This component runs controllers tailored to the cloud provider, managing tasks like provisioning resources and handling cloud-specific operations. If your Kubernetes cluster runs on local machines, the Cloud Controller Manager is unnecessary.
Worker Nodes
Worker Nodes run your containerized applications and include:
Kubelet: An agent ensuring containers run as the Control Plane specifies.
Container Runtime: The software (e.g., containerd, CRI-O) responsible for running the containers on the node.
Kube Proxy: Manages networking for Pods, handling communication within the cluster and with external resources.
In the following sections, we will visit some basic concepts/abstractions to help you get started with k8s
Pods
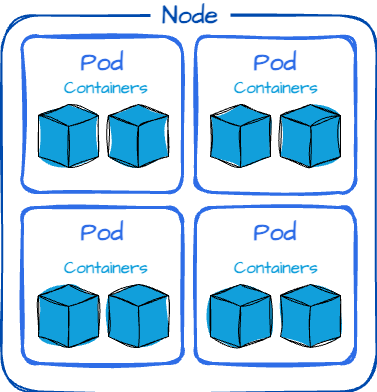
The Pod is the smallest and most basic deployable object in Kubernetes. It represents a single instance of a running process in your cluster and can contain one or more containers that share the same network namespace and storage.
Why not just manage containers directly? Kubernetes uses Pods to group containers that need to work together, simplifying networking and storage management. For instance, a Pod might include a web server container alongside a helper container that handles logging.
Pods are ephemeral by nature, meaning they can be created, destroyed, or replaced anytime. This is where higher-level abstractions like Deployments come into play. They manage the lifecycle of Pods.
Deployments
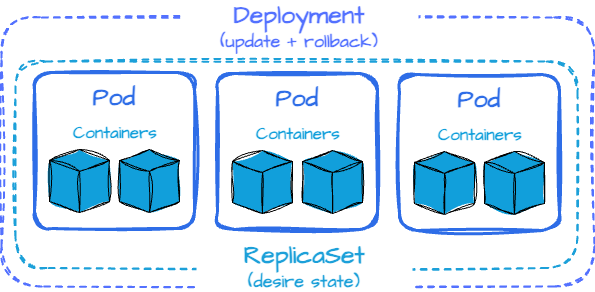
Deployments are one of the most commonly used Kubernetes abstractions. They provide a declarative way to manage the lifecycle of Pods, handling tasks like scaling, updates, and rollbacks. In k8s, a ReplicaSet is an abstraction that maintains a stable set of replica pods running at any given time. In most cases, we will use a Deployment to manage ReplicaSets automatically.
For example, if you're running a data processing application that needs to scale up during peak hours, a Deployment ensures that the correct number of Pods are running at all times. It also facilitates rolling updates, allowing you to update your application without downtime. If something goes wrong, you can easily roll back to a previous version.
Note: Deployment is not the only abstraction for managing the pods; there are others, such as StatefulSet, DeamonSet, or Job.
Services
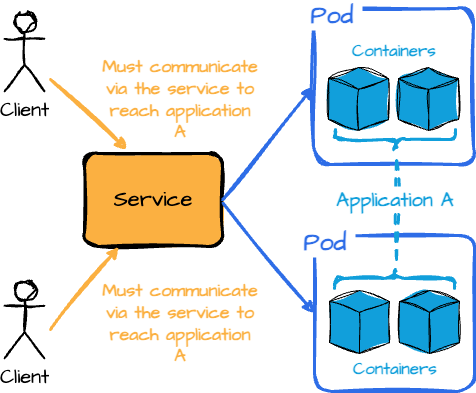
Services providing a stable network endpoint for a set of Pods. This is important because Pods are ephemeral; their IP addresses can change as they are created or replaced.
Services ensure that other applications or clients can reliably communicate with your Pods, even as the underlying Pods come and go. They also handle load balancing and distribute incoming traffic across multiple pods to ensure even load distribution and high availability.
ConfigMaps and Secret
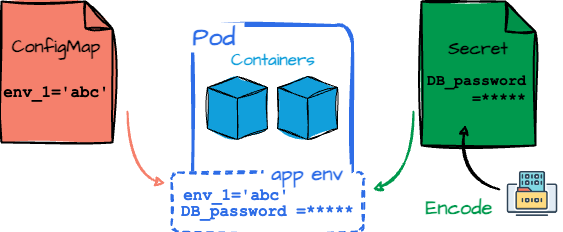
As a data engineer, you often need to configure your applications differently depending on the environment—development, staging, or production. ConfigMaps in Kubernetes lets you decouple configuration data from your application code, making it easier to manage and update configurations dynamically.
For example, you can store database connection strings or feature flags in a ConfigMap and inject them into your Pods as environment variables or configuration files. This approach makes your applications more portable and reduces the need to rebuild container images when configuration changes.
It is crucial to securely manage sensitive data like passwords, API keys, and certificates. Kubernetes provides Secrets, allowing us to store sensitive information separately from application code and ConfigMaps.
Secrets are stored in a base64-encoded format and can be mounted into Pods as files or exposed as environment variables.
Persistent Volumes and Persistent Volume Claims
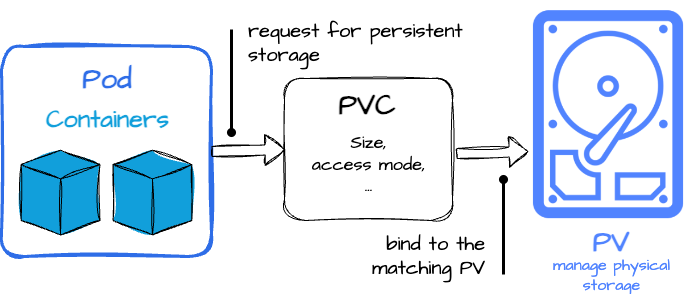
While Pods are ephemeral, some applications require persistent storage that outlives a Pod's lifecycle. Kubernetes provides Persistent Volumes (PV) and Persistent Volume Claims (PVC) to manage this aspect.
Persistent Volumes (PV): A Persistent Volume is a piece of storage in the cluster that has been provisioned manually by the user or dynamically via storage classes. It is independent of the Pod that uses it, allowing storage to persist even if the Pod is destroyed. PVs abstract the underlying storage infrastructure, which could be anything from local disk storage to cloud-based solutions like AWS EBS, Google Persistent Disks, or NFS.
Persistent Volume Claims (PVC): A Persistent Volume Claim is a request from a Pod for persistent storage. It specifies the size, access modes, and sometimes the storage class needed. When a PVC is created, Kubernetes binds it to an available PV that meets the requested criteria. This decouples storage management from application deployment, allowing developers to request storage resources without understanding the underlying infrastructure.
But, Why So Many Abstractions?
You might wonder why Kubernetes introduces so many different abstractions. The answer lies in its design philosophy, which emphasizes separation of concerns.
Each abstraction in Kubernetes addresses a specific aspect of application management. This modular approach makes it easier to manage complex applications. By isolating concerns, Kubernetes enables you to independently scale, secure, and update different parts of your application. For example, you can scale your web servers separately from your data processing tasks, update configurations without redeploying applications, and rotate secrets without exposing them.
If I started with Kubernetes again
I struggled a lot when beginning with k8s. I think there were three main reasons:
I try to compare Docker and K8s: If you decide to start learning k8s, don’t try to compare; try to answer the question: “Why do we need k8s?“
The state: Things might not work as intuitively as you'd expect. My initial assumption was that if I wanted my application up and running, I could instruct the machine, and it would follow. However, in K8s, actions aren’t executed immediately; it first compares the current state with the desired state to decide if action is needed. The lesson here is to understand how K8s work before diving in.
Too many abstractions: It really frustrated me when I first tried to get my first application running on k8s. There were too many than needed to care about care: Pod, Deployment, Service, PV. My experience is that we need to relax and not worry about mastering all the abstractions; learn enough to get our application up and running. If you need other abstractions, pick them up and learn later. While too many abstractions might sound like a nightmare at first, you will gradually see that this approach gives you more flexibility to manage your application aspects.
Finally, I leave some tips based on my experience:
Start small: Don’t try to set up the entire k8s environment with many servers when you first begin. Tools like Minikube help you start local k8s deployment on your laptop.
Start simple: To move yourself forward, start with the simplest application on K8s. Don’t try to deploy a tool that requires too many components, such as Airflow. You will move toward the complex application later.
Persistence Wins: Your application might not run perfectly on the first try. Debugging can be frustrating, but keep going. Everything you learn during the process is worth every dime.
Finally, try to learn from your friend or colleague. It will save you tons of time.
Outro
Thank you for reading this far.
I hesitated to write about Kubernetes for a long time, but I finally decided to do so because I believe it can bring value to everyone.
If you're interested in more Kubernetes content, let me know, and I'll prepare additional articles on this topic.
Now, see you in the next article.
Reference
[1] Kubernetes Official Document
Before you leave
If you want to discuss this further, please comment or contact me via LinkedIn, Email, or Twitter.
It might take you five minutes to read, but it took me more than five days to prepare, so it would greatly motivate me if you considered subscribing to receive my writing.
Awesome article not just for Data Engineers but anyone who wants to learn Kubernetes!
Excellent article, as always! Kubernetes is one of the most complicated concepts of operations in my opinion, and you explained it very well! 👏👏👏