
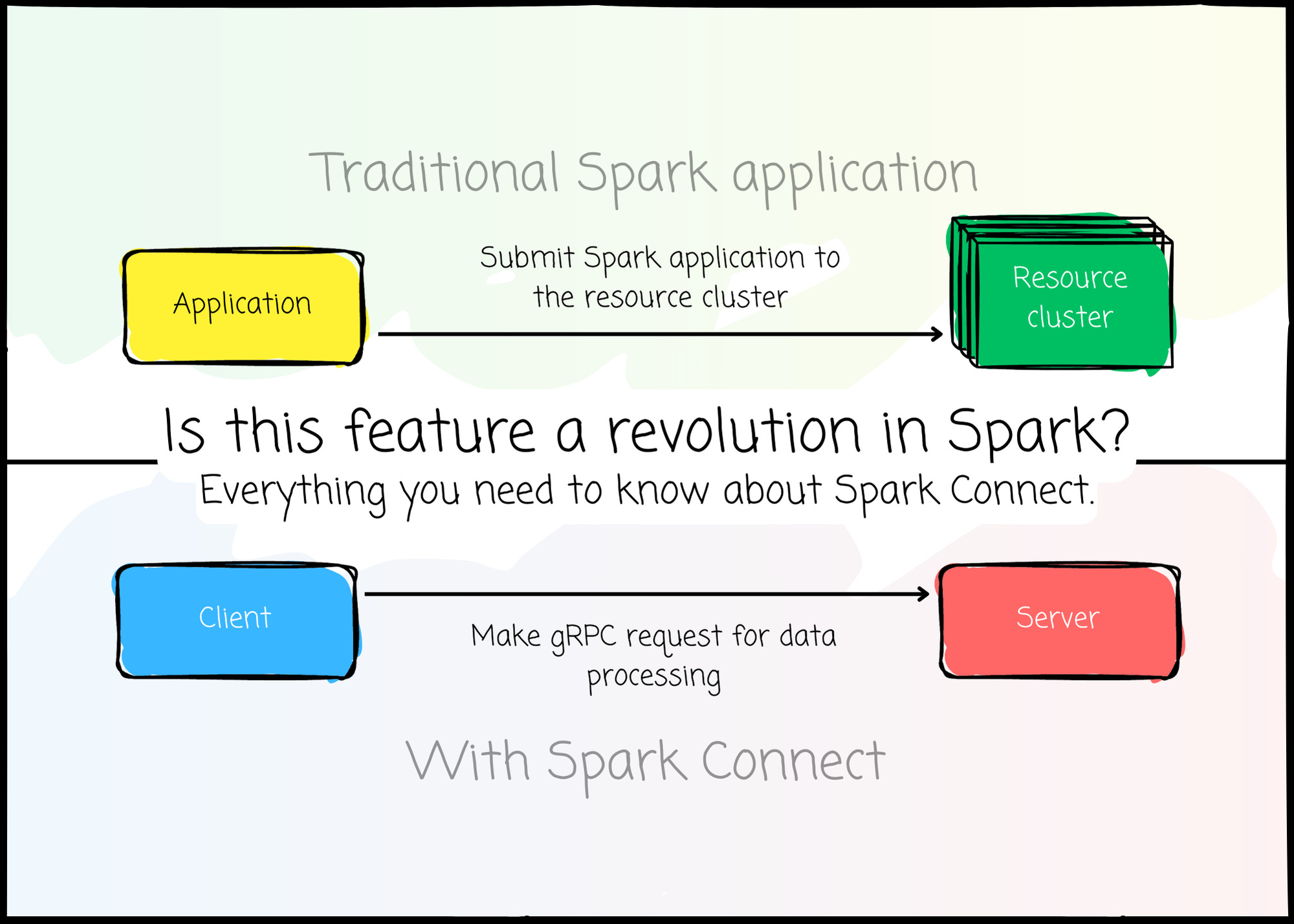
Is this feature a revolution in Spark?
Process data in Spark by making an API request instead of submitting an application. Everything you need to know about Spark Connect.

I will publish a paid article every Tuesday. I wrote these with one goal in mind: to offer my readers, whether they are feeling overwhelmed when beginning the journey or seeking a deeper understanding of the field, 15 minutes of practical lessons and insights on nearly everything related to data engineering.
Keep reading with a 7-day free trial
Subscribe to VuTrinh. to keep reading this post and get 7 days of free access to the full post archives.