
I spent 8 hours understanding Apache Spark's memory management
Here's everything you need to know

My ultimate goal is to help you break into the data engineering field and become a more impactful data engineer. I'm excited to introduce a paid membership option to take this a step further and dedicate even more time to creating in-depth, practical content.
This will allow me to produce even higher-quality articles, diving deeper into the topics that matter most for your growth and making this whole endeavor more sustainable.
To celebrate this new milestone, I’m offering a limited-time 50% discount on the annual plan.
Intro
In 2009, UC Berkeley’s AMPLab developed Spark.
At that time, MapReduce was the go-to choice for processing massive datasets across multiple machines. AMPLab observed that cluster computing had significant potential.
However, MapReduce made building large applications inefficient, especially for machine learning (ML) tasks requiring multiple data passes.
For example, the ML algorithm might need to make many passes over the data. With MapReduce, each pass must be written as a separate job and launched individually on the cluster.
They created Spark. Unlike MapReduce, which writes data to disks after every task, Spark relies on memory processing.
With a more friendly API, supporting wide use cases, and especially efficient in-memory processing, Spark has gained increasing attention and become the dominant solution in data processing.
But, do you know how Spark manages the memory?
This week, I will try to answer this question in the following text. We will revisit some Spark basics before diving into Spark’s memory management.
A Spark Application
A typical Spark application consists of:

Driver: This JVM process manages the Spark application, handling user input and distributing work to the executors.
Executors: These JVM processes execute tasks the driver assigns and report their status and results. Each Spark application has a set of isolated executors. A single physical worker node can have multiple executors.
Cluster Manager: This component manages the cluster of machines running the Spark application. Spark can work with different managers, including YARN or Spark’s standalone manager.
Note: You might find some confusion here. The cluster manager will have its own “master” and “worker” abstractions. The main difference is that these are tied to physical machines rather than Spark processes.
When the cluster manager receives the Spark application, the manager places the driver process in one of the worker nodes. Next, the SparkSession from the application code asks the cluster manager for resources. If things go well, the manager launches the executor processes and sends the relevant information about their locations to the driver. The driver then forms the plan and starts scheduling tasks for executors.
Jobs, Stages, Tasks
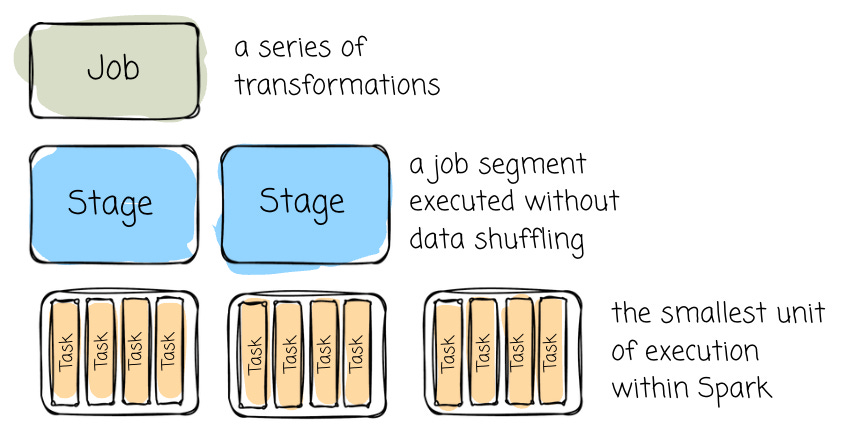
From the previous section, we know that an executor will handle tasks from the driver. To understand the task concept, we must learn more about other things:
Job: A job represents a series of transformations applied to data. It encompasses the entire workflow from start to finish.
Stage: A stage is a job segment executed without data shuffling. A job is split into different stages when a transformation requires shuffling data across partitions.
DAG: In Spark, RDD dependencies are used to build a Directed Acyclic Graph (DAG) of stages for a Spark job. The DAG ensures that stages are scheduled in topological order.
Task: A task is the smallest unit of execution within Spark. Each stage is divided into multiple tasks, which execute processing in parallel across different data partitions.
So, the driver will do something to break down the Spark job into executable tasks for the executor. Spark was designed to run tasks in parallel; an executor can handle multiple tasks at the same time. Here’s where the “in-memory processing“ happens.
The memory management
This article only discusses the executor’s memory management.
As mentioned above, when submitting the Spark application, the cluster manager initiates the driver and executors, which are JVM processes. The user can specify the resource for these processes.
The driver resource:
spark.driver.cores,spark.driver.memory,…The executor resource:
spark.executor.cores,spark.executor.memory, …
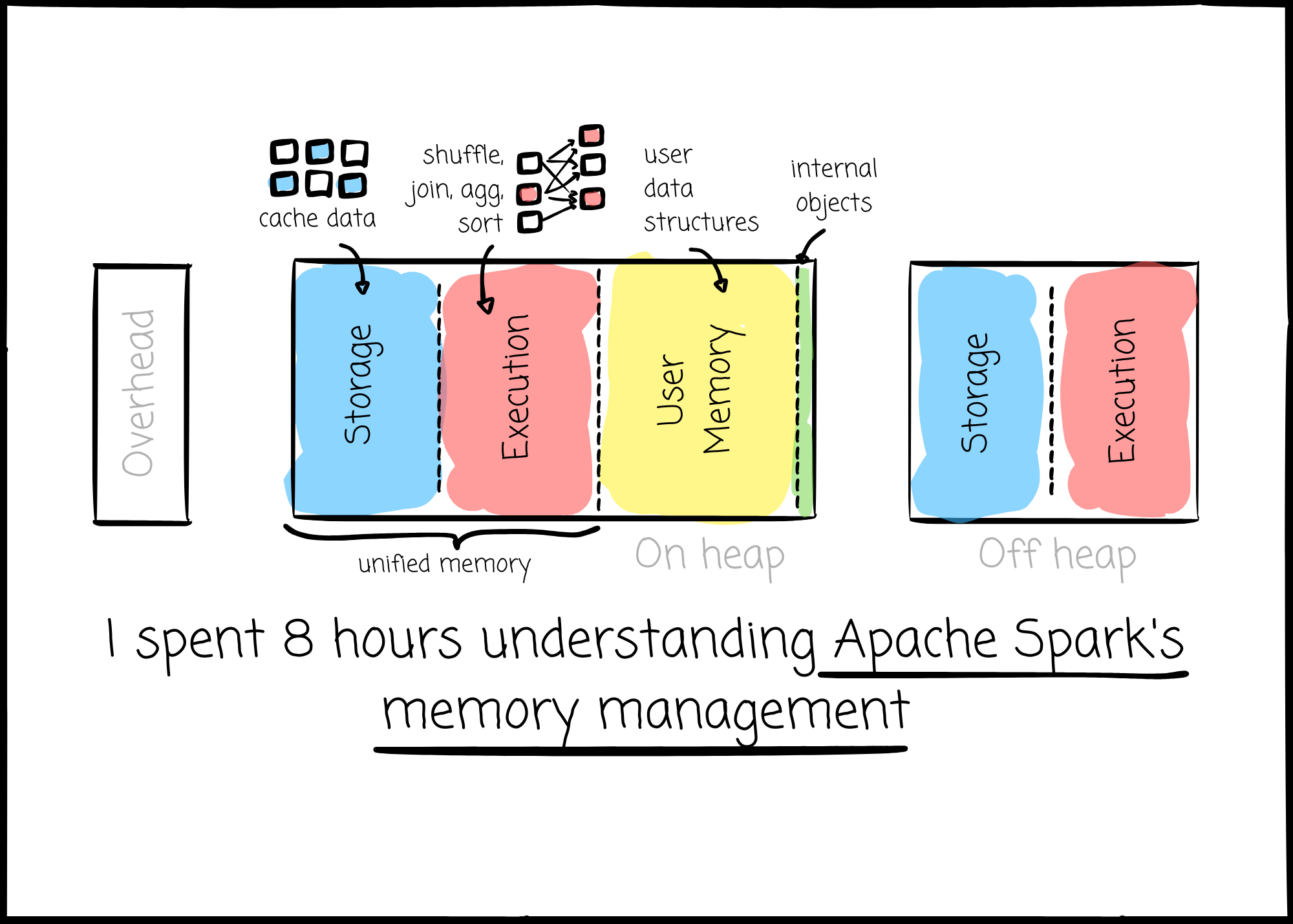
The executor has three main regions for memory: on-heap, off-heap, and overhead.

Let’s start with the on-heap region.
On Heap
Keep reading with a 7-day free trial
Subscribe to VuTrinh. to keep reading this post and get 7 days of free access to the full post archives.