
I spent 4 hours learning Apache Iceberg. Here's what I found.
The table format's overview and architecture

I'm offering an exclusive sponsorship slot in each issue to keep this newsletter free for readers. If you want to feature your product in my newsletter, explore my media kit:
I’m making my life less dull by spending time learning and researching “how it works“ in the data engineering field.
Here is a place where I share everything I’ve learned.
Not subscribe yet? Here you go:

Intro
My writing journey will continue with Apache Iceberg. If you ask me why I chose Iceberg, I can’t answer clearly. I just feel that I would have a lot of fun with this open format and could do a lot of cool stuff with it.
(A not-so-engineering reason from a data engineering)
In this article, I will provide an overview of the Apache Iceberg.
What is Iceberg?
We will answer this by asking another question: What is the table format? If you work with the database or the data warehouse, they give you a lovely abstraction: the table. The system hides away the actual physical data layer under the hood, so you don’t need to worry too much about the data beneath.
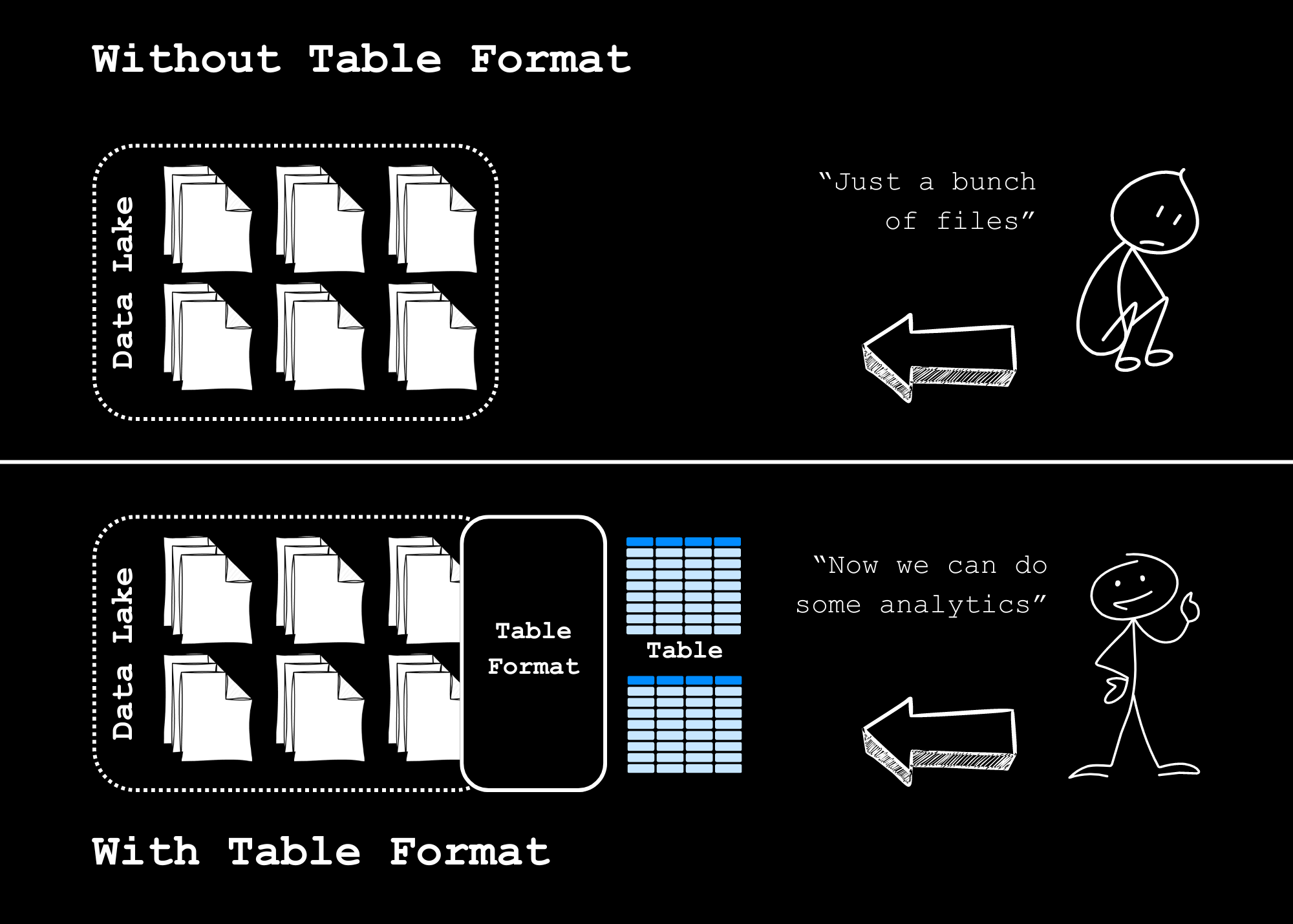
Things will be different when you want to deploy a Data Lakehouse solution. Your data will sit right in the object store, and you can bring your favorite engine, like Spark or Trino, and execute the query on top of it. There is no need for data moving around—one central place for everything you need, from the ad-hoc queries to the machine learning workload.
But here’s the thing: how do we or the engine know which files belong to a dataset?
The table formats come to save the day.
They help us organize and manage the data files beneath so we can put thousands of files in the storage and loudly say:
“Here is your table. Come and use it.“
In more detail, a table format brings the power of a data warehouse into the data lake: table abstraction, ACID transaction, time travel, etc. It achieves this by using the metadata.
Different table formats will establish the metadata layer differently. Apache Hive took the directory-based approach. Its metadata said, “Your table/partition is all the files in this directory.” Despite the simplicity and long-term adoption, it has some limitations: inefficient minor modifications, the inability to safely change data in multiple partitions, or the user needing to be aware of the underlying table layout.
So, the new table format is needed.
The new generation format took a file-based approach, managing the metadata at the file level. Apache Iceberg was first created by Netflix. With the Iceberg specification, Netflix expects to achieve better table correctness and faster query planning (than Hives), and it also allows users not to worry too much about the physical data layout.
We will discuss the Iceberg architecture in the following sections.
The Architecture
An Apache Iceberg table has three layers organized hierarchically: the catalog layer is at the top, followed by the metadata layer, which includes metadata files, the manifest list, and the manifests file. The final layer is the data. Since each higher layer tracks the information of the one below it, we'll start from the bottom and work our way up.
The data layer
This layer stores the table’s actual data, including the data and deleted files. Data files store the data itself, and delete files keep track of which records in the table have been deleted. Delete files in Iceberg using the merge-on-read strategy. It will create a new file that records the deletion; the reader must merge the deleted files with the data files to retrieve the final result.
Manifest Files
Manifest files keep track of the data files in the data layer and provide statistics, like the minimum and maximum values for each column in a data file. They also define the file format of the data files, such as Parquet, ORC, or Avro.
Manifest Lists
A manifest list captures the snapshot of an Iceberg table at a specific moment. It includes a list of manifest files and details such as the manifest file’s location and partition information. Essentially, a manifest list is an array of structs, each representing a single manifest file.
Metadata Files
Metadata files contain information about an Iceberg table at a specific time, such as the table's schema, partition details, snapshots, and the latest snapshot. When the Iceberg table changes, the catalog creates a new metadata file and marks it as the latest version. This process maintains a linear history of table commits. Additionally, Iceberg always presents the table's latest version to the reader.
The catalog
The catalog is where every Iceberg data operation begins. It guides you on where to go first. The catalog will point you to the current metadata pointer's location. Iceberg catalog is required to support atomic operations when updating the pointer, which ensures that all readers and writers see the same table state at any moment.
Many different backends can serve as catalogs for Iceberg, such as Hive Metastore, Nessie, or AWS Glue Catalog.
The following sections will describe some typical data operations of Apache Iceberg
Write-Read Operation
Create an empty table
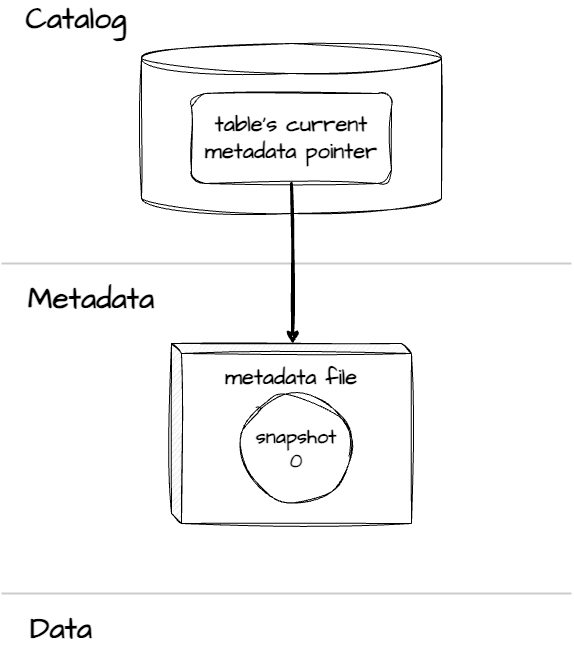
The very first stage of every query is parsing. For the CREATE statement, only a metadata file is created.
The engine will create a metadata file with a snapshot s0 when we create an empty table. The general metadata file path looks something like this: …/metadata/ v1.metadata.json. The metadata will include the table’s schema and a table unique identifier: table-uuid.
At the final stage, the engine will update The catalog record for this table's current metadata pointer to point to this metadata file’s location.
Insert some data
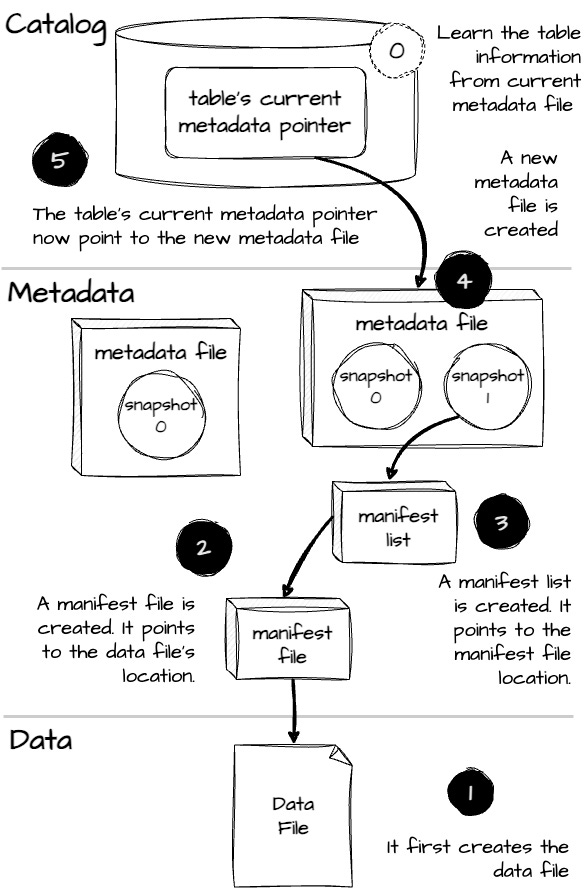
Now, let’s see what happens when we put some data into the table:
The user sends an
INSERTstatement to the engine, something like INSERT INTO this_table VALUES.The first thing the engine needs to do is query parsing.
Because it’s a write data request, the engine needs table information; it contacts the catalog for the current metadata’s location to learn about the table schema and the partition scheme.
Next, it creates a Parquet data field at
…/data/abc.parquet. If the table is defined with a partitioning scheme in the metadata file, the engine will write the database using this scheme.A manifest file is created at
…/metadata/def.avro. It points to the data file’s location. Plus, the engine records statistical details like a column's upper and lower bounds. This helps the query engine to skip unnecessary files later when reading the data.A manifest list is created at
…/metadata/snap-xyz.avroto keep track of the manifest file. It points to the manifest file location and also keeps track of details like the number of added or deleted data files or rows. It also records statistics about partitions, like the lower and upper bounds of the partition columnsA new metadata file is created based on the previously current metadata file with a new snapshot
s1, as well as keeping track of the previous snapshots0. It points to the manifest list and includes details like the file path of the manifest list, the snapshot ID, and a summary of the operation.The catalog updates the table’s current metadata pointer to the new metadata file.
The Select Query
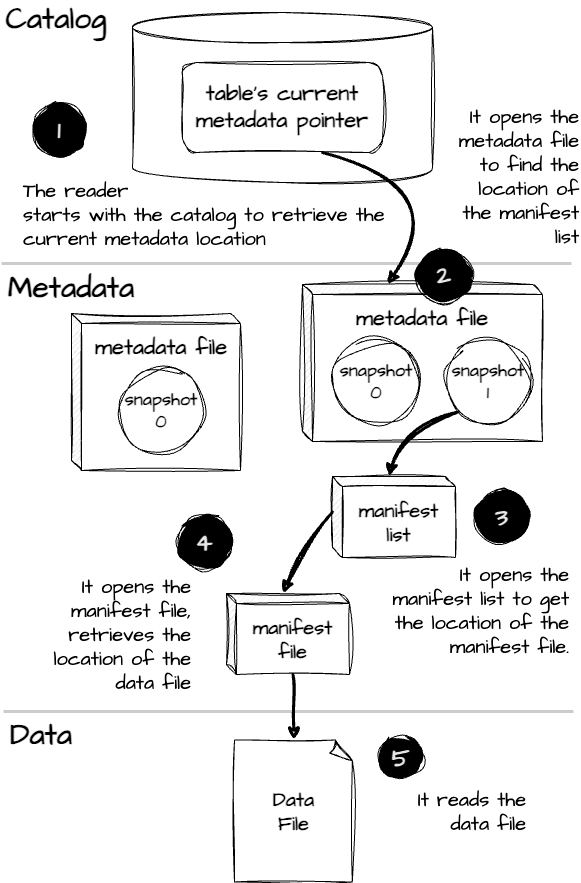
What happens when we select some data from the table:
The engine starts by reading the to retrieve the location of the table’s current metadata file.
It opens the metadata file to get some information. First, the engine learns the table's schema to set up its internal memory structures for reading data. Then, it learns about the table's partitioning scheme to understand the physical data layout. This helps the query engine to skip irrelevant data files later on. It then finds the location of the manifest list for the current snapshot,
s1.Then, it opens the manifest list to get the location of the manifest file.
It opens the manifest file and determines the datafile path based on the partition filter (if specified in the query)
The engine follows the location of the data files and returns the data to the user.
Reading data from the past
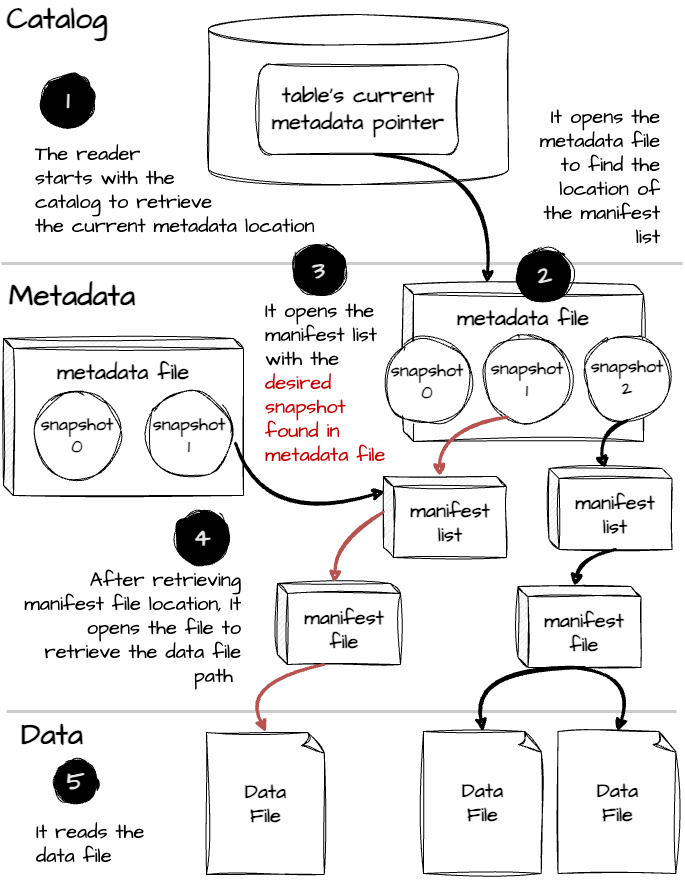
Let's say after one more data insert operation, the table's current snapshot is S2 and for some reason, the user wants to time-travel back to the snapshot S1, here is what happened behind the scenes:
First, the engine will parse the input query.
Like the regular data reading operation, it will also reach the catalog to locate the current metadata file.
The engine then reads the current metadata file to retrieve table information; since the metadata file keeps track of all Table snapshots, the engine can choose the snapshot it wants to read based on the time-travel filter from the query.
In this case, the engine will follow the location of the manifest list of the snapshot.
s1.The engine then opens the manifest list to get the manifest file location.
It opens the manifest file and determines the data file path. The engine follows this path to read the data and return it to the user.
Outro
Based on what I've learned, I’ve just covered the high-level overview of Iceberge.
Although this article might only take 10 minutes to read, I hope it can give you a basic understanding of the Apache Iceberg, why it was created, and its architecture.
I'm writing about Iceberg from a beginner's perspective, so if you notice any misunderstandings or inaccuracies, please don't hesitate to discuss and correct me. It'll be an excellent way for all of us to learn together.
References
[1] Tomer Shiran, Jason Hughes & Alex Merced, Apache Iceberg: The Definitive Guide (2024)
[2] Jason Hughes, Apache Iceberg: An Architectural Look Under the Covers
It might take you five minutes to read, but it took me days to prepare, so it would greatly motivate me if you considered increasing my subscriber count.
Very good overview.
Very nice, Thanks