
I spent 8 hours learning about vector databases
From their typical workload, how it stores to how it serves the data

I will publish a paid article every Tuesday. I wrote these with one goal in mind: to offer my readers, whether they are feeling overwhelmed when beginning the journey or seeking a deeper understanding of the field, 15 minutes of practical lessons and insights on nearly everything related to data engineering.

Intro
Cursor, Gemini, ChatGPT, and many other AI tools are dominating the world.
They work and serve humans based on existing data. And, the data must be stored somewhere so that the LLM models behind these applications can access it. The database seems a strong candidate, just like your company backend needs to be stateful with the help of a transactional database.
However, traditional OLTP and OLAP databases are not designed to work with AI.
A new kind of database is emerging.
In this article, we will explore vector databases, the data management systems designed for AI workloads. At the end of this article, you will understand the general idea and fundamentals of a vector database.
Vector embedding
Since the early 2000s, the speed of data proliferation has not slowed down. It’s not only about the volume, but also the variety of the data; from documents, text, images, to videos, the demand is not only to collect and analyze tabular data, but also the unstructured one.
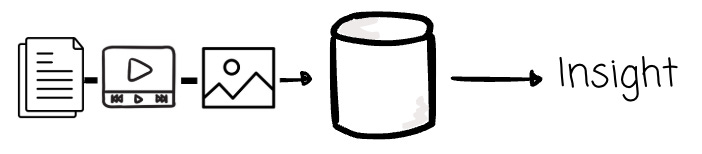
Then comes the AI era, the time when we speak to Gemini or ChatGPT more than we spend time with our friends. Increasingly, companies want to feed data to LLM models, hoping to receive valuable insights in return. The thing is, these models don’t see the image or the videos the way we do.

There must be a translator.
That’s where vector embedding shines. It translates complex, “unstructured” data—like a word, a sentence, a picture, or a song—into a list of numbers (a “vector”).
A simple text like: “The quick brown fox”

Can be vectorized into a list of floating point numbers like this via specialized machine learning models: [0.12, -0.45, 0.98, ..., -0.22]
The cool thing is that this list of numbers (which can be hundreds or thousands of items long) captures the semantic meaning or context of the original data.
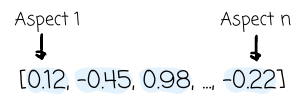
A number is called a dimension; each is used to represent an aspect of the data. For example, the first dimension provides information about the color, the second tells us about the shape, and so on.
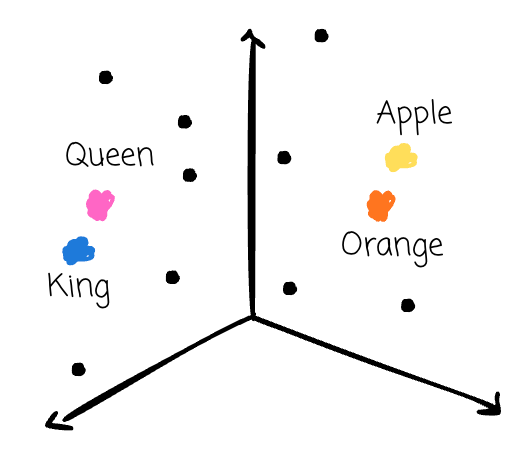
By representing the data in vector embedding, we can map the data in a high-dimensional “meaning space,” and use some mathematical magic to check the closeness of the data; for example, the vectors for “king” and “queen” would be very close to each other. The vector for “apple” and “orange” would also be close. But the vector for “king” would be very far away from the vector for “apple.”
Now, LLM models can understand the semantics of our data and can query for the related data based on the input. That fundamental backs a lot of use cases, from classification and clustering to recommendation engines and semantic search, as well as how ChatGPT or Gemini answers your questions.
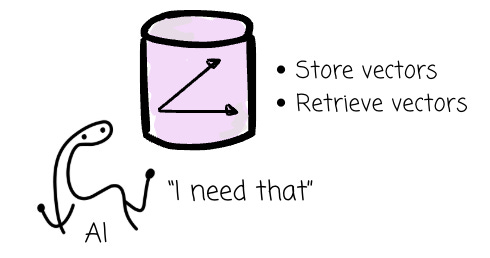
It’s no exaggeration to say the ability to store and retrieve vector embedding efficiently is the backbone of AI workloads.
Vector databases
Because of that trend, more systems have emerged to give that ability. Some choose to build a dedicated vector database from scratch, such as Weaviate. Others build a system to serve both vector embedding and traditional analytics workloads, such as LanceDB. Some choose to extend an existing system with new capabilities, such as pgvector.
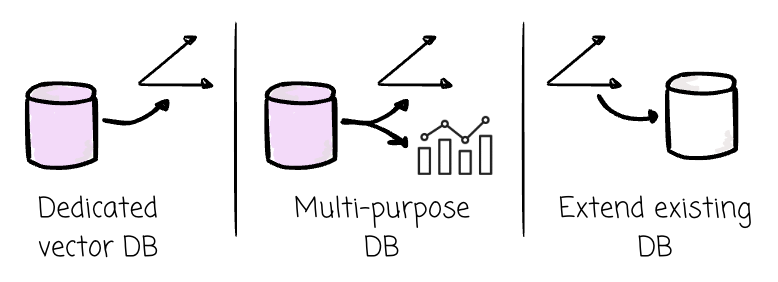
Despite the difference in how they approach, all the vendors try to offer two things:
The ability to efficiently store vector embedding
The ability to efficiently do neighbor search (input’s related vectors)
I believe three aspects need to be discussed here:
How is the data stored? Does the vector system use row or column format?
How does the system do the neighbor search, and what techniques can make it faster?
Space efficiency when storing vector embedding data.
How is the data stored?
Keep reading with a 7-day free trial
Subscribe to VuTrinh. to keep reading this post and get 7 days of free access to the full post archives.