

To celebrate the launch of learn-spark for paid subscribers, the CLI tool that helps you learn Spark faster and more affordably right on your laptop. I’m offering you a 50% discount on the annual plan—grab it now to get access to the learn-spark tool!
After becoming a paid subscriber, visit this link to get invited to the learn-spark repo.
The offer ends VERY SOON!

Table of contents
Context and Challenge
The old architecture
The new architecture
Evaluation
Intro
A few weeks ago, we learned how Uber handles their real-time infrastructure to process millions of events daily. This week, we will see another big tech company deal with the data real-time processing requirement: Twitter.
This article uses this blog from Twitter for reference; it was released in 2021, so it might not reflect the current real-time solution at Twitter (X).
Context and Challenge
Twitter processes 400 billion events in real time and generates a petabyte (PB) of daily data. The events come from many sources, including different platforms and systems: Hadoop, Kafka, Google BigQuery, Google Cloud Storage, Google PubSub, etc. To deal with the massive scale of data, Twitter built their internal tool dedicated to each demand: Scalding for batch processing, Heron for stream processing, TimeSeries AggregatoR framework for both, and Data Access Layer for data consumption.
Despite the technology's robustness, the data growth still puts pressure on the infrastructure; the most bolding example is the interaction and engagement pipeline, which processes large-scale data in batch and real-time. This pipeline collects and processes data from various real-time streams and server and client logs to extract Tweet and user interaction data with many levels of aggregations and metrics dimensions. The aggregate data of this pipeline serves as the source of truth for Twitter’s ads revenue and many data product services. Thus, the pipeline must ensure low latency and high accuracy. Let’s see how Twitter handles this mission.
The following sections describe Twitter's original interaction and engagement pipeline solution.
The old architecture
Overview
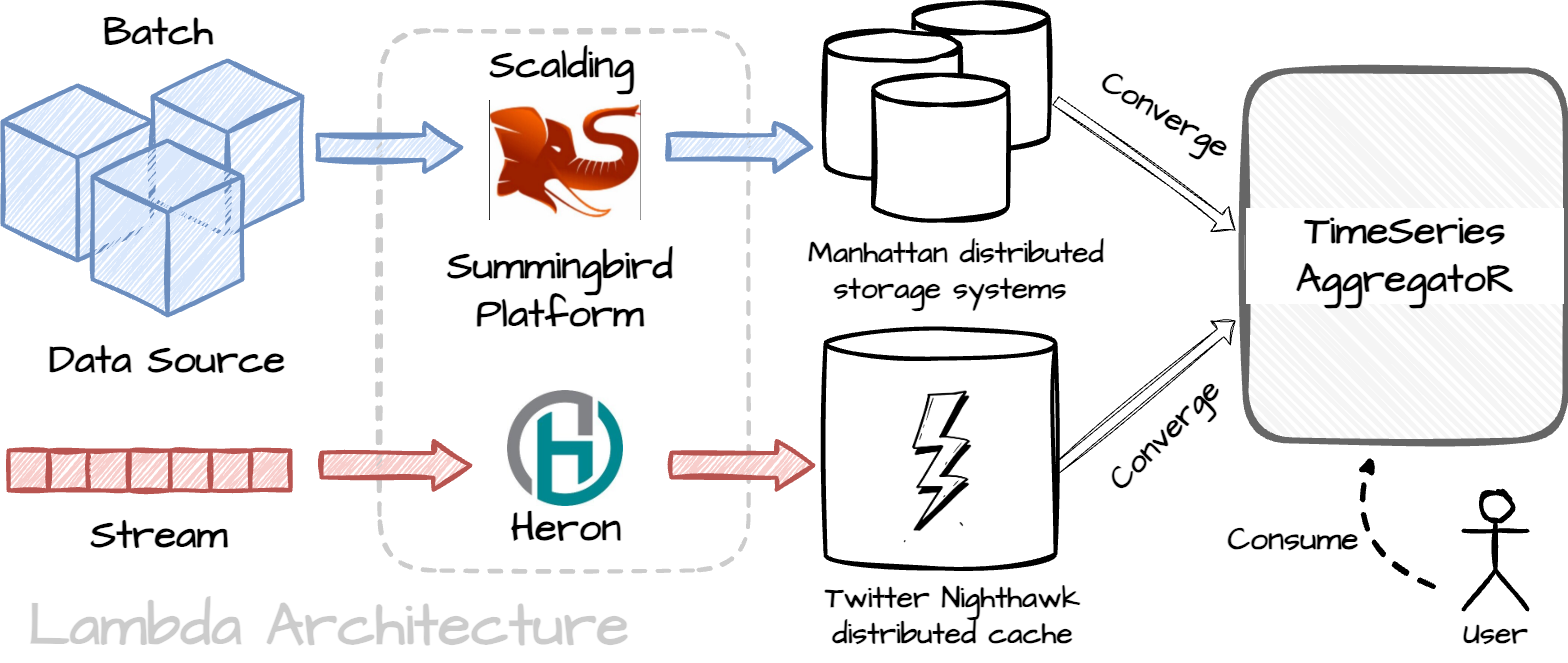
Twitter employs the lambda architecture for the original solution. There are two separate pipelines: batch processing, which provides accurate views of batch data, and real-time stream processing, which offers views of online data. The two view outputs will be converged at the end of the day. Twitter built the architecture with the following:
Summingbird Platform: as I understand, this platform includes multiple distributed engines like Scalding and Heron and a dedicated library that allows users to define MapReduce logic and execute it on these engines.
TimeSeries AggregatoR: a robust and scalable real-time event time series aggregation framework.
Batch: The source for the batch pipeline can come from logs, client events, or tweet events in HDFS. There are many Scalding pipelines to preprocess the raw data and then ingest them into the Summingbird Platform. The result of the pipeline will be stored in the Manhattan distributed storage systems. To save cost, Twitter deploys batch pipelines in one data center and replicates the data in the other 2 data centers.
Real-time: The source of the real-time pipeline comes from Kafka topics. The data will “flow“ to Heron within the Summingbird Platform, then the result from the Heron will be stored in the Twitter Nighthawk distributed cache. Unlike the batch pipeline, the real-time pipeline is deployed in 3 different data centers.
There is a query service on top of batch and real-time storage.
Challenge
Due to the high scale and high throughput of real-time data, there can be a risk of data loss and inaccuracy. If the processing speed does not catch up with the event stream, backpressure will arise in the Heron topology (a directed acyclic graph indicates the Heron flow of data processing). When the system is under backpressure for a while, the Heron bolts (think it’s like the workers) can accumulate lag, which leads to overall high system latency.
In addition, many Heron Stream Managers can fail (Stream Manager manages data routing between topology components) due to backpressure. Twitter’s solution is to restart Heron containers to bring up the stream managers. However, restart certainly causes event loss, thus reducing the overall accuracy of the pipeline.
The following sections describe Twitter's new solution after realizing the limitations of the original solution.
To celebrate the launch of learn-spark for paid subscribers, the CLI tool that helps you learn Spark faster and more affordably right on your laptop. I’m offering you a 50% discount on the annual plan—grab it now to get access to the learn-spark tool!
After becoming a paid subscriber, visit this link to get invited to the learn-spark repo.
The offer ends VERY SOON!
The new architecture
Overview
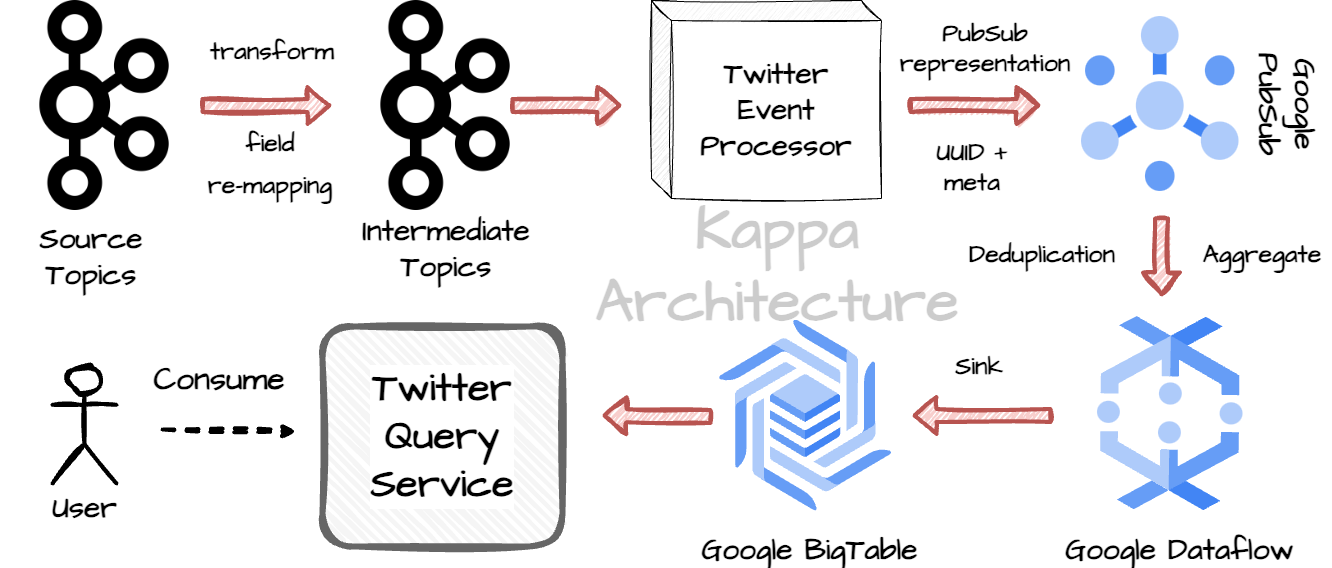
With the new approach, Twitter used the Kappa architecture to simplify the solution with only one real-time pipeline. The architecture will leverage both internal Twitter and Google Cloud Platform solutions:
On-premise: they built their preprocessing service, which converts Kafka topic events to Google Pubsub events representation.
On Google Cloud: They use Pubsub for event ingestion, Dataflow jobs for deduplication and real-time aggregation, and BigTable for output sinks.
The process flow of the new architecture can be described like this:
Step 1: They consume data from the source Kafka topics, do transformations and field re-mapping, and finally send the result to the intermediate Kafka topics.
Step 2: The Event Processors transform data from the intermediate Kafka topics to Pubsub representation and decorate the event with UUID (used for deduplication in Dataflow) and some meta information related to the processing context.
Step 3: The Event Processors send the events to the Google Pubsub topic. Twitter almost infinitely retries for this PubSub-published process to ensure the messages are delivered in at-least-once manner from The Data Centers to Google Cloud.
Step 4: The Google Dataflow job will process the data from the PubSub. The Dataflow workers handle deduplication and aggregation in real-time.
Step 5: The Dataflow workers write the aggregate result to the BigTable.
Evaluation
Twitter observation on the new architecture
Achievement of the new approach
The latency is kept stable at ~10s compared to the 10s - 10 min latency of the old architecture.
The real-time pipeline can achieve up to ~1GB/s throughput compared to the max ~100 MB/s of the old architecture.
Ensuring nearly exactly once processing thanks to at-least-once data publishing to Google Pubsub plus the deduplicated effort from Dataflow.
Saving the cost of building the batch pipelines.
Achieving higher aggregation accuracy.
The ability to handle late events.
No event loss when restarting
How do they monitor the duplicate percentage?
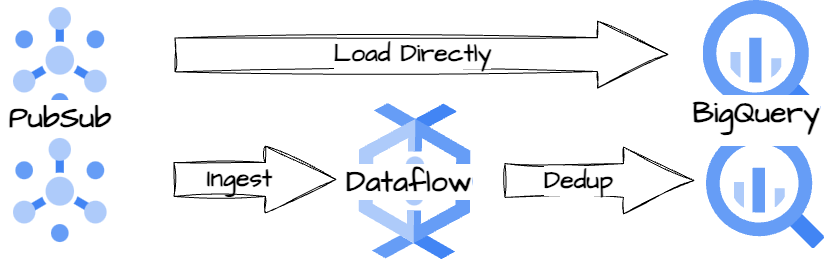
Twitter creates two separate Dataflow pipelines: one pipeline routes raw data directly to BigQuery from Pubsub, and another pipeline exports deduplicated event counts to BigQuery. This way, Twitter can monitor duplicate event percentages and percentage changes after deduplication.
How do they compare the deduplication count from the old batch pipeline with the new Dataflow pipeline?
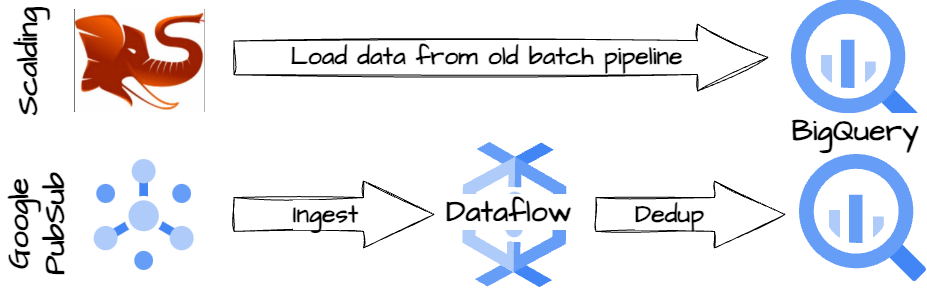
The new workflow, besides writing to the BigTable, also exports deduplicated and aggregated data into BigQuery.
Twitter also loads the old batch data pipeline results into BigQuery.
They run scheduled queries to compare the duplicate counts
The result is that more than 95% of the new pipeline results exactly match the old batch pipeline. The 5% discrepancy is mainly because the original batch pipelines discard late events, which the new pipeline can capture efficiently.
Outro
By moving to the new Kappa architecture, Twitter improved significantly in latency and correctness compared to the old architecture. Not only better performance, but the new architecture also simplified the data pipeline, which only remains the stream one.
See you on the next blog.
References
[1] Lu Zhang and Chukwudiuto Malife, Processing billions of events in real-time at Twitter (2021)
Before you leave
Leave a comment or contact me via LinkedIn or Email if you:
Are interested in this article and want to discuss it further.
Would you like to correct any mistakes in this article or provide feedback?
This includes writing mistakes like grammar and vocabulary. I happily admit that I'm not so proficient in English :D
It might take you five minutes to read, but it took me more than five days to prepare, so it would greatly motivate me if you considered subscribing to receive my writing.
4 billions seems small for a Twitter like company, may be they don't log all events.