
How is Databricks' Spark different from Open-Source Spark?
Why don't they just use the open-sourced Apache Spark?

To celebrate the launch of learn-spark for paid subscribers, the CLI tool that helps you learn Spark faster and more affordably right on your laptop. I’m offering you a 50% discount on the annual plan—grab it now to get access to the learn-spark tool!
After becoming a paid subscriber, visit this link to get invited to the learn-spark repo.
The offer ends VERY SOON!

Intro
This week, we will explore the differences between open-source Spark and Databricks Spark, why the creators originally developed Spark, why Spark alone is insufficient for Databricks' Lakehouse solution, and how Databricks makes Spark significantly more efficient.
Apache Spark
Why it was created
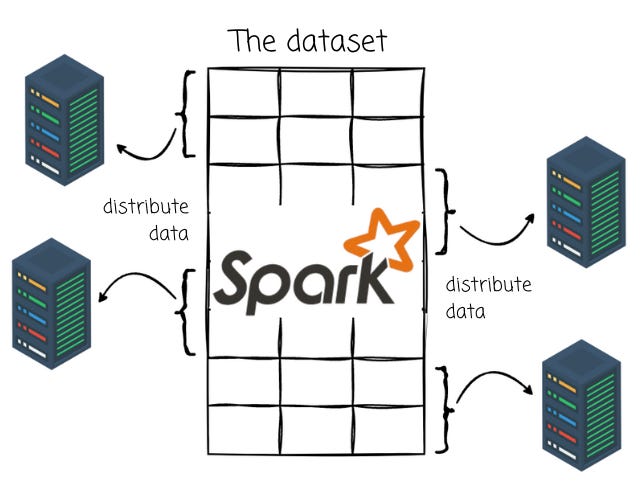
Apache Spark is an open-source distributed computing system designed to quickly process large volumes of data that can hardly accomplished by operating on a single machine. Spark distributes data and computations across multiple machines.
It was first developed at UC Berkeley’s AMPLab in 2009.
At the time, Hadoop MapReduce was the popular choice for processing big datasets across multiple machines. AMPLab collaborated with early MapReduce users to identify its strengths and limitations. They also worked closely with Hadoop users at UC Berkeley, who focused on large-scale machine learning requiring iterative algorithms and multiple data passes.

These discussions highlighted some insights. Cluster computing had significant potential. However, MapReduce made building large applications inefficient, especially for machine learning tasks requiring multiple data passes. For example, the machine learning algorithm might need to make many passes over the data. With MapReduce, each pass must be written as a separate job and launched individually on the cluster.
To address this, the Spark team created a functional programming-based API to simplify multistep applications and developed a new engine for efficient in-memory data sharing across computation steps.
SparkSQL
Spark was intended to focus more on a general-purpose cluster computing engine than a specified database’s query engine. Realizing the need for relation processing over big datasets, the people behind Apache Spark presented the new model Spark SQL in 2014. This new module lets Spark programmers leverage the benefits of relational processing (e.g., declarative queries and optimized storage). Spark SQL introduces two significant enhancements.
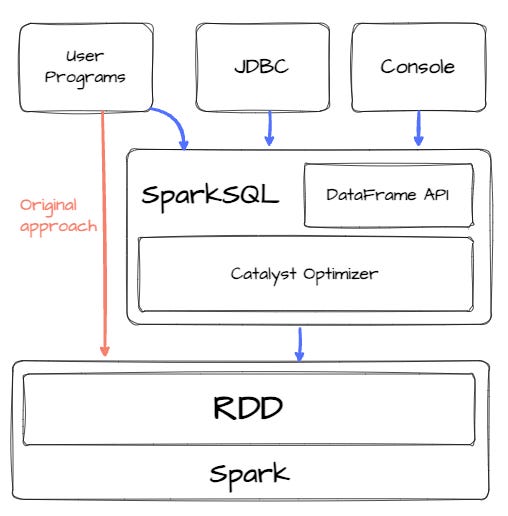
First, it integrates relational and procedural processing through a declarative DataFrame API.
Second, it incorporates a highly extensible optimizer, Catalyst, which leverages Scala's features to facilitate the addition of composable rules and manage code generation.
The goals of SparkSQL are:
Support relational processing of Spark’s native RDDs and external data sources using a convenient API.
Offering high performance using DBMS techniques.
Efficiently supporting new data sources,
Enabling extension with advanced analytics algorithms such as graph processing and machine learning.
The people behind Spark aim to make it a viable option as a query engine.
Databricks
The Apache Spark team founded Databricks in 2013. The company aims to simplify the process of building and deploying Spark applications for organizations. In 2019, Databricks introduced Delta Lake, a table format that provides the warehouse capability to the data lakes.
In 2021, they released a paper introducing the new data management paradigm, the Lakehouse. This paradigm combines the best of both worlds: the warehouse's robust management features with the lake's theoretically unlimited scalability.

Databricks aimed to solve some problems with the two-tier data architecture, such as the stale data in the warehouse compared to the lake’s, the difficulty and cost of consolidating the data lake and warehouse, and users being billed twice the storage cost for data duplication in the data lake and warehouse.
They have been offering the managed lakehouse solution with Delta Lake for the storage layer and Spark for the query engine.
The challenges
Databricks does not just want to offer a data management system; it must also ensure high performance to compete with other solutions in the market, such as Snowflake, BigQuery, and Redshift.
At that time, all the above solutions primarily positioned themselves as cloud data warehouse solutions—the lakehouse paradigm caused Databricks some problems because Spark was initially not developed to be a native query engine:
The Lakehouse query engines deal with a greater variety of data than traditional warehouses. From organized datasets to raw data with messy layouts, many small files, many columns, and no valuable statistics, the execution engine must be flexible enough to deliver good performance on a wide range of data.
Databricks initially offered Spark as the lakehouse engine. To enhance the query engine, they must ensure that many customers using Spark do not experience disruptions.
They need a more efficient query engine but can’t replace Spark. So, what did they do? Simple—they enhanced Spark in place.
To celebrate the launch of learn-spark for paid subscribers, the CLI tool that helps you learn Spark faster and more affordably right on your laptop. I’m offering you a 50% discount on the annual plan—grab it now to get access to the learn-spark tool!
After becoming a paid subscriber, visit this link to get invited to the learn-spark repo.
The offer ends VERY SOON!
Their effort
An important thing to note is that before this effort to enhance Apache Spark, Databricks already built their own Spark runtime, the Databricks Runtime (DBR), which is a fork of Apache Spark that provides the same interface but has enhancements for reliability and performance.
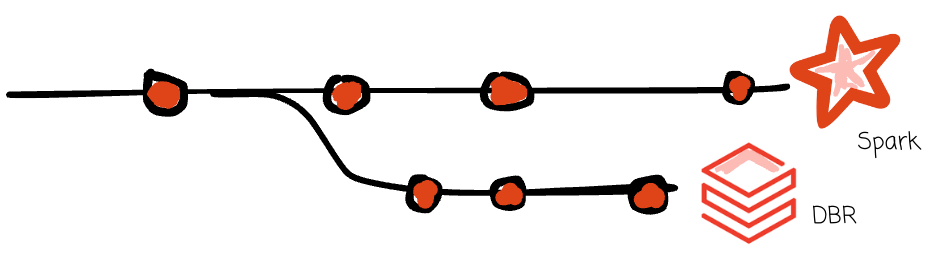
But they need a little more than that.
They built the Photon engine, a library that integrates closely with the DBR. The engine acts as a new set of physical operators inside the DBR. The query plan can use these operators like any other Spark. Databricks’s customers can continue to run their workloads without any changes and still benefit from Photon.
The system can run the queries partially in Photon; if it needs unsupported operations, they are switched back to SparkSQL. Databricks tests Photon to ensure its semantics are consistent with Spark SQL’s
Databricks built Photon using a vectorized model instead of the code generation approach that Apache Spark implements. Vectorized execution enabled support runtime adaptivity; Photon discovers, maintains, and leverages micro-batch data characteristics with specialized code paths to adapt to the properties of Lakehouse data.
Another essential design that Databricks made when developing Photon is writing it in C++ instead of following the Spark approach, which used the Java Virtual Machine (JVM). Databricks observed that “the Spark applications were hitting performance ceilings with the existing JVM-based engine.” Moreover, they found that the performance of native code was more effortless to explain than that of the JVM engine, as they can explicitly control aspects like memory management and SIMD in C++.
The Photon Designs
JVM vs. Native Execution
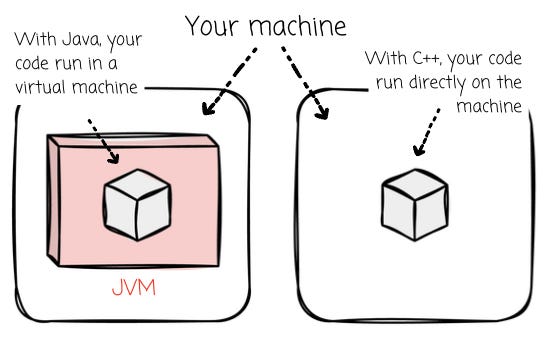
Databricks decided to move away from the JVM and implement a native code execution engine. Integrating the new engine with the existing JVM-based runtime is challenging for Databricks. Here are several reasons that led Databricks to the decision to develop a new native execution engine:
The Lakehouse paradigm demands processing a wide range of workloads that stresses the JVM engine's in-memory performance.
Improving the JVM engine performance requires deep knowledge of JVM internals.
Databricks found they lack control over lower-level optimizations such as custom SIMD kernels.
They also observed that garbage collection performance degraded on heap memory larger than 64GB. Databricks had to manually manage off-heap memory in the JVM-based engine, which made the codebase more complex.
Interpreted Vectorization vs. Code Generation
Modern OLAP systems build high-performance engines predominantly using two approaches: interpreted vectorized design inspired by the MonetDB/X100 system or code-generated design used in systems like Spark SQL or Apache Impala.
Vectorized engines use a dynamic dispatch mechanism like virtual function calls to choose the code block for the execution; then, the system will process data in batches and enable SIMD to amortize virtual function call overhead. On the other hand, code generation uses a compiler at runtime to generate specific code for each query; this way, the approach doesn’t have to deal with virtual function call overhead. Databricks tries to implement both of the above methods; here are their observations:
Code generation is more complicated to build and debug because the approach generates executing code at runtime; Databricks engineers need to add extra code manually to find issues. In contrast, the interpreted approach only deals with native C++ code; print debugging was much more manageable. As a result, their engineers only needed a couple of weeks to prototype the vectorized approach, while it took them two months with the code-generated approach.
Code generation removes interpretation and function call overheads by collapsing and inlining operators into a few functions. Despite the performance boost, this makes observability difficult. Operator collapsing prevents the engineers from observing metrics on how much time is spent in each operator, “given that the operator code may be fused into a row-at-a-time processing loop.” In contrast, the vectorized approach maintains clear boundaries between operators.
Photon can adapt to data properties by choosing a code path at runtime based on the input’s type. This is critical in the Lakehouse context because constraints and statistics may not be available for all queries.
Databricks found they can achieve code-generated specialization with vectorized engines by creating specialized fused operators for the most common cases.
For these reasons, Databricks chose the vectorized approach for the Photon engine.
If you want to learn more about vectorization and code generation, here are the two resources you should check out:
Row vs. Column-Oriented Execution
Traditionally, Spark SQL represents records in memory with a row-oriented format. Since the Lakehouse execution engine mainly deals with columnar files like Parquet, scanning data from disk to memory requires expensive column-to-row pivoting when using the Spark SQL engine.
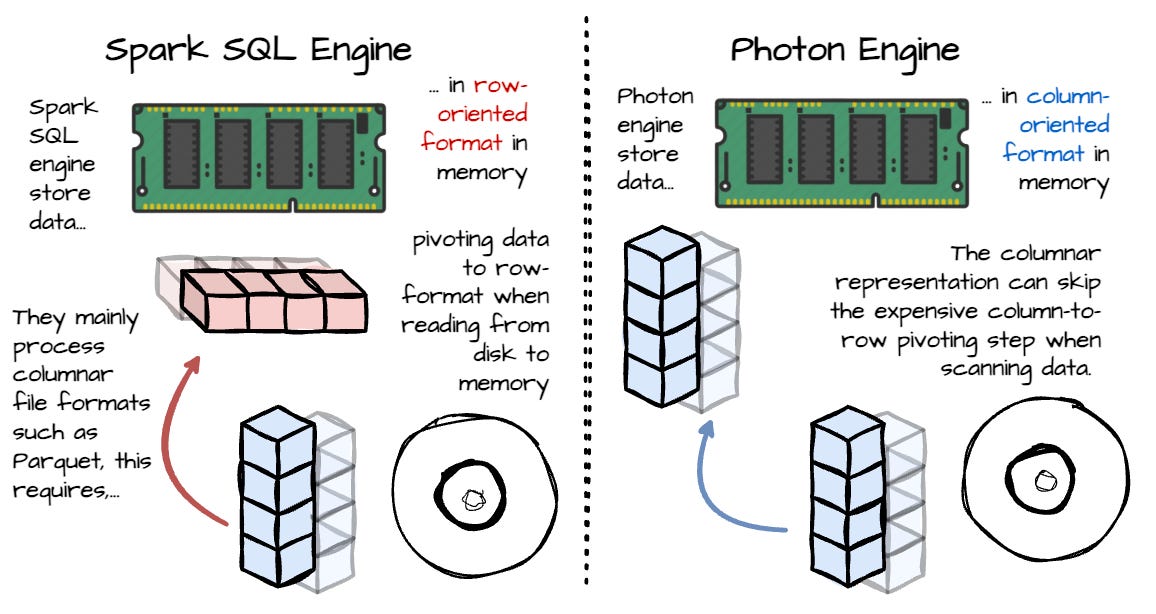
In contrast, Photon adopts columnar in-memory data representation; the system stores values of a particular column contiguously in memory. This layout is more convenient for SIMD and enables more efficient data pipelining and pre-fetching. Moreover, it allows for the efficient working of columnar data on disks, eliminating the column-to-row pivoting process and making it easier to write data to disks with the columnar engine.
Outro
Based on my observation, many solutions are out there that try to do the same things as Datbricks has done with Spark: they tried to make Spark more efficient as a query engine by implementing state-of-the-art techniques for OAN LAP systems while keeping it compatible with Spark.
Apache DataFusion Comet implements Apache Datafusion as a runtime for Spark to achieve improvement in terms of query efficiency and query runtime.
Apache Gluten(incubating) is a middle layer that offloads JVM-based SQL engines’ execution to native engines.
Even with the community versions, contributors actively work to make Spark more efficient as an OLAP query engine. One significant improvement is the introduction of Adaptive Query Execution (AQE), which allows query plans to be adjusted based on runtime statistics collected during execution.
Your turn: What’s your experience with Databricks’ Spark? Do you think the open-source version of Spark will catch up with Databricks’ version at any point in the future?
—
Thank you for reading this far. If you notice any logical gaps, please let me know.
It’s time to say goodbye—see you in my next article! ;)
Reference
[1] Databricks, Photon: A Fast Query Engine for Lakehouse Systems (2022).
[2] Michael Armbrust, Reynold S. Xin, Cheng Lian, Yin Huai, Davies Liu, Joseph K. Bradley, Xiangrui Meng, Tomer Kaftan, Michael J. Franklin, Ali Ghodsi, Matei Zaharia Spark SQL: Relational Data Processing in Spark (2015)
[3] Liz Elfman, A brief history of Databricks (2023)
A lot of insights in your post, thank you
Impressive! Very clear explanation.