
How does Netflix ensure the data quality for thousands of Apache Iceberg tables?
The Write-Audit-Publish pattern with Iceberg Branches

To celebrate the launch of learn-spark for paid subscribers, the CLI tool that helps you learn Spark faster and more affordably right on your laptop. I’m offering you a 50% discount on the annual plan—grab it now to get access to the learn-spark tool!
After becoming a paid subscriber, visit this link to get invited to the learn-spark repo.
The offer ends VERY SOON!

Intro
The last time I wrote about Netflix Data Engineering Stacks, I learned that Netflix employs the Write-Audit-Publish pattern to keep thousands of Iceberg tables in high-quality status.
This week, we will examine the Write-Audit-Publish pattern and how it can be implemented with the Apache Iceberg table format.
The article will only have a glimpse over the Apache Iceberg; if you want to learn the details of this table format, you can check out my two articles here:


Iceberg at Netflix
By the way, Iceberg is orginally created at Netflix
Internally, thousands of Apache Iceberg data tables cover all aspects of Netflix's business. For the data audits, Netflix employs the WAP (Write-Audit-Publish) pattern. They first write the data to a hidden Iceberg snapshot and then audit it using an internal data auditor tool. If the audit passes, this snapshot is exposed to the user.
Write-Audit-Publish
The main idea of the Write-Audit-Publish (WAP) pattern for controlling data quality is simple. Before releasing the data asset to production, it must be placed in the “staging“ environment to check its quality.
The pattern is similar to the common CI/CD workflows when you need to deploy your code changes to the staging environment to check for bugs; if everything goes well, you merge the changes into the production environment.
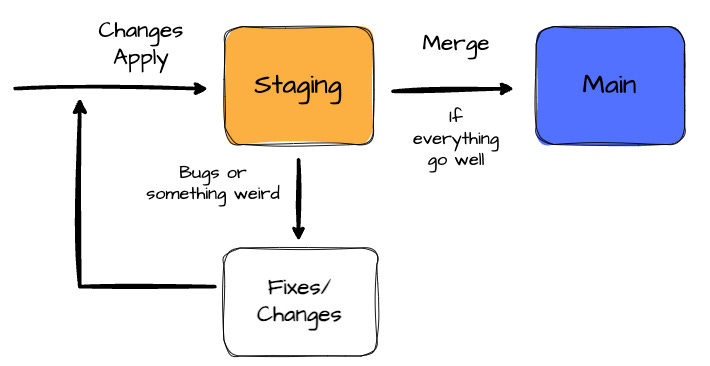
In Iceberg, implementing the WAP pattern lets data producers validate all changes before exposing them to downstream consumers. This can reduce data quality issues that lead to downtime and prevent dashboards with weird trends/numbers.
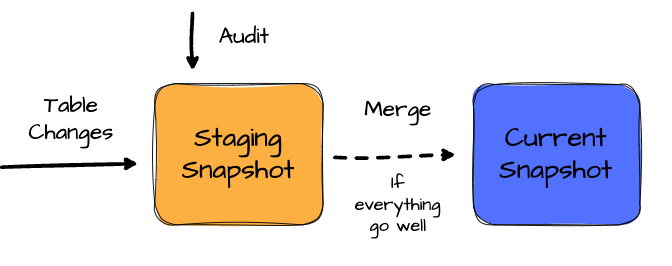
The following section will review the Apache Iceberg table format to understand how the WAP pattern can be implemented with Iceberge specifications.
Iceberg Review
An Apache Iceberg table has three layers organized hierarchically: the catalog layer is at the top, followed by the metadata layer, which includes metadata files, the manifest list, and the manifests file. The final layer is the data. Since each higher layer tracks the information of the one below it, we'll start from the bottom and work our way up.
The following sub-sections will review the metadata layer of Iceberg.
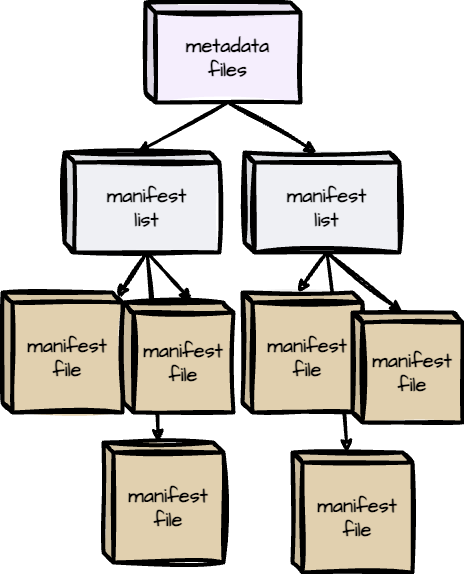
Manifest Files
Manifest files keep track of the data files in the data layer and provide statistics, like the minimum and maximum values for each column in a data file. They also define the file format of the data files, such as Parquet, ORC, or Avro.
Manifest Lists
A manifest list captures the snapshot of an Iceberg table at a specific moment. It includes a list of manifest files and details such as the manifest file’s location and partition information.
Metadata Files
Metadata files contain information about an Iceberg table at a specific time, such as the table's schema, partition details, snapshots, and the latest snapshot. When the Iceberg table changes, the catalog creates a new metadata file and marks it as the latest version.
The catalog
The catalog is where every Iceberg data operation begins. It guides you on where to go first. The catalog will point you to the current metadata pointer's location. Iceberg catalog is required to support atomic operations when updating the pointer, which ensures that all readers and writers see the same table state at any moment.
To celebrate the launch of learn-spark for paid subscribers, the CLI tool that helps you learn Spark faster and more affordably right on your laptop. I’m offering you a 50% discount on the annual plan—grab it now to get access to the learn-spark tool!
After becoming a paid subscriber, visit this link to get invited to the learn-spark repo.
The offer ends VERY SOON!
Iceberg’s Tag and Branch
Every data writes results in new snapshots (new manifest list). Iceberg keeps track of all snapshots to allow readers to read desired snapshots based on snapshot ID or timestamp.
Tags and branches were later supported in Iceberg to track snapshots more efficiently. Both reference snapshots in the table’s metadata. The first is read-only and lets users give particular snapshots a name. The latter allows users to keep track of snapshots under different paths and can be updated like the table.
We will focus more on the branching feature of Iceberg from now on.
Apache Iceberg table branching allows the creation of independent snapshot lineages. Each is a named reference pointing to a series of snapshots. Each branch points to the head of the branch, which is the most recent snapshot in the branch history. Without any surprise, the table’s current state is the main branch. Each branch can also be configured for the maximum snapshot age (time-to-live) and the minimum number of snapshots.
The interesting thing here is Iceberg branching can be achieved on two levels:
Branching on individual tables (natively supported in Iceberg)
Branching on the catalog level (using Project Nessie for the catalog)
The first option offers changes isolation at the table level, creating branches for specific tables.
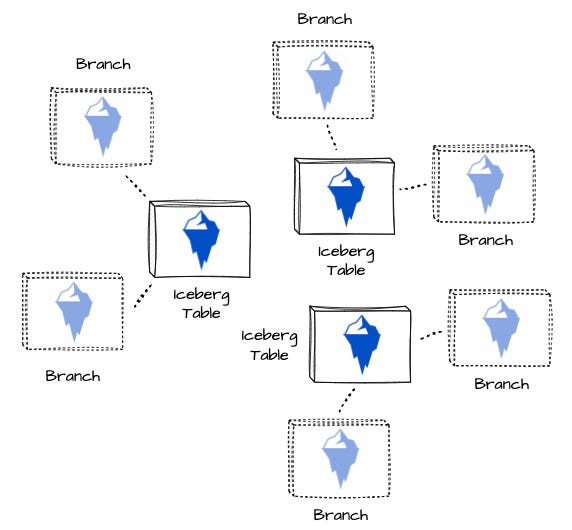
It can capture table-specific changes well. However, specifying branching for each table can be overhead and challenging in a scenario when you need to re-create the whole production environment for a staging/testing environment with a large number of tables.
Isolating changes at the catalog level allows you to capture changes across multiple tables.
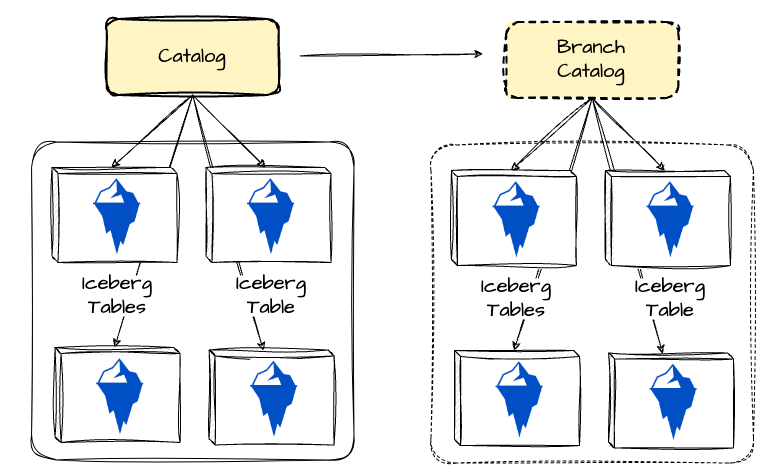
With Project Nessie, users can take a snapshot of the complete catalog at a particular time. This approach offers a more robust version control strategy, enabling users to replicate the production data environment efficiently.
The decision between the two options lies in the scale of the data environment. Table-level branching can offer flexibility for individual tables but might become challenging in a large-scale data environment. On the other hand, catalog-level branching provides a robust way to capture changes across multiple tables, but it might be “too much“ for small-scale use cases.
If you found the Iceberg branching feature familiar, you’re right; it is similar to the git’s features, in which Iceberge table snapshots are like the commits in the git repo. In addition, Iceberg uses a tree structure similar to git that efficiently stores snapshot data and metadata. Only changed files are rewritten to output a new snapshot, and most of the existing data and metadata are reused across snapshots.
WAP implementation in Iceberg
This sections just go through the overview of the process, if you prefer the detailed tutorial, you can check out the WAP guide with Iceberg + Spark from Tabular here.
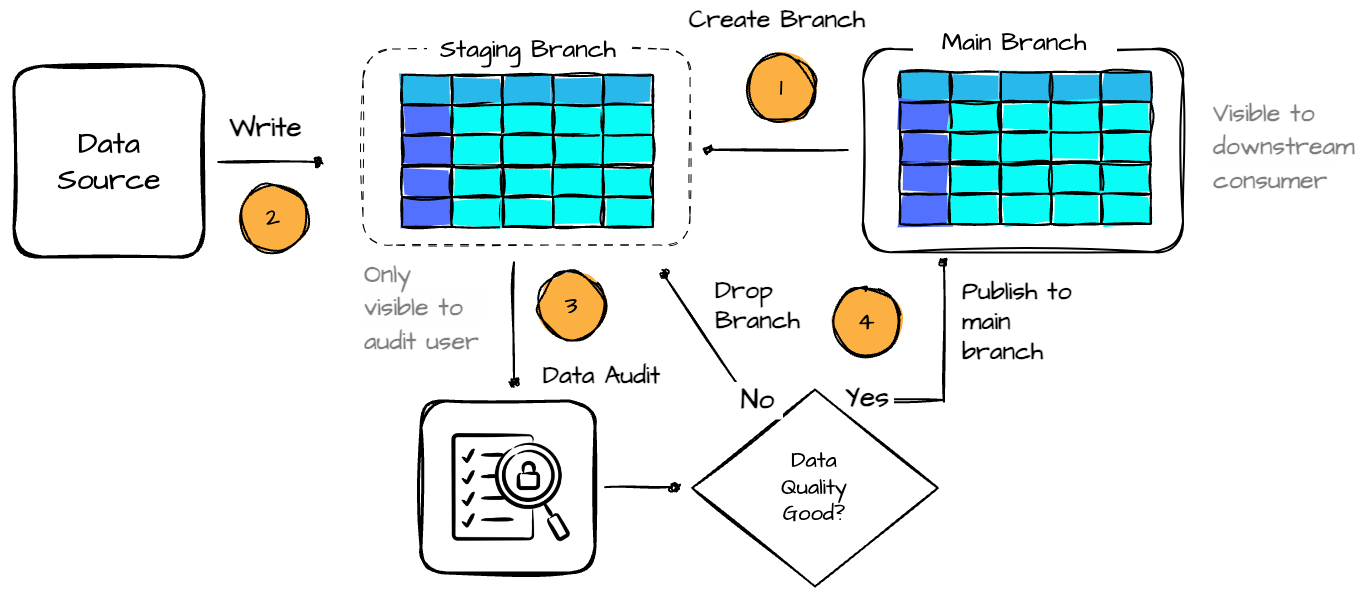
Creating the Iceberg table branch.
Users write into the branch. The Iceberg-Spark extensions include a mechanism to enable the WAP pattern. With the configuration enabled, the Spark job writes to tables will be staged in the predefined branch instead of writing to the main branch.
When the write is present in the branch, the users can audit the data in any way they want.
If the data quality checks are successful, the users can fast-forward all changes made to the staging branch to the table’s main branch. This is similar to merging a git pull request to the master.
Outro
Thank you for reading this far.
In this article, we explored how Netflix relies on the WAP pattern to audit thousands of Iceberg tables. We then covered the general idea of WAP, reviewed the Apache Iceberg specifications and how they enable the WAP pattern, and finally, checked out the typical Iceberg WAP process.
See you on my next blog ;)
References
[1] Chris Stephens, Pedro Duarte, Netflix Data Engineering Tech Talks - The Netflix Data Engineering Stack (2023)
[2] Tabular, Write – Audit- Publish (WAP) Pattern
[3] Tabular, Creating Branches and Tags
[4] Tomer Shiran, Jason Hughes, Alex Merced, Apache Iceberg: The Definitive Guide: Data Lakehouse Functionality, Performance, and Scalability on the Data Lake
Before you leave
If you want to discuss this further, please leave a comment or contact me via LinkedIn, Email, or Twitter.
It might take you five minutes to read, but it took me more than five days to prepare, so it would greatly motivate me if you considered subscribing to receive my writing.
Hi Vu, great article..
By the way, which tool do you use to create the images ?