


How do Iceberg, Delta Lake, and Hudi ensure atomicity?
When you write 3 files, you don't want to see only 1.5 files are persisted.

I will publish a paid article every Tuesday. I wrote these with one goal in mind: to offer my readers, whether they are feeling overwhelmed when beginning the journey or seeking a deeper understanding of the field, 15 minutes of practical lessons and insights on nearly everything related to data engineering.
I invite you to join the club with a 50% discount on the yearly package. Let’s not be suck as data engineering together.
Intro
In the context of a database, especially with the ACID (Atomicity, Consistency, Isolation, and Durability) guarantees, atomicity means that if multiple changes are made, all of them must be in one of two states: all succeed or all fail.
This simplifies the process of retrying the transaction in case of failure. Just imagine that the transaction has four changes. Without atomicity, two changes are committed, and the other two changes fail. How does the client determine which changes to retry?
Most relational databases are built from scratch with ACID in mind. Open table formats differ; Iceberg, Delta Lake, or Hudi were developed to work with object storage, which only supports single-object atomic operations. However, the lakehouse write workload can be spread across multiple objects. So, how does this table format approach offer atomicity support?
Let’s find out in this article.
This article focuses solely on how these table formats operate on object storage. Additionally, we will only discuss their atomicity properties; other properties, such as concurrency, will be explored in a future article.
My observation
Although there are differences in how they implement under the hood, the general idea is straightforward: they rely on a lightweight atomic operation that creates the metadata object (the metadata files in Iceberg, the object logs in Delta Lake, and the completed files in Hudi)
In addition, data in these table formats (or other OLAP systems) is immutable; modifying data requires writing new files. This facilitates the implementation of atomicity support, which is quite straightforward. They only need to abandon all the newly written files if the transaction fails, keeping the current state of the data unaffected.
Now, let’s dive into each table format.
Iceberg
Overview
Iceberg's architecture has three distinct layers to define a table's state.

The Data Layer consists of the actual data files in object storage.
The Metadata Layer has an immutable tree structure of metadata files. These metadata files also persist in object storage. The hierarchy allows Iceberg to track table state efficiently without relying on directory listings
Table Metadata File (
metadata.json): This file serves as the root of the tree for a given table version. It is a JSON file that contains a comprehensive definition of the table, including its current schema, historical snapshots, partitioning scheme, sort order, etc.Manifest List: This is a metadata file (in Avro format) that contains a list of all the manifest files that make up a particular snapshot. This allows query planners to skip entire groups of data files without having to read the manifest files themselves.
Manifest File: This is also an Avro file that lists a subset of a table's data files. For each data file, the manifest stores detailed statistics, like column-level metrics (such as minimum and maximum values, null counts, etc.). This file-level metadata is essential for query optimization, as it enables file pruning, allowing the query engine to avoid reading data files that don’t contain required data.
The Catalog Layer is the entry point for Iceberg table operations and is the single source of truth for the current state of any given table. Its primary responsibility is to map the table identifier to the location of that table's current metadata file.
How does it support atomic operations?
The core mechanism for achieving atomicity is the pointer swapping in the catalog. The process of committing a transaction is as follows:

Contact the catalog: The process begins by contacting the catalog to get the current metadata file.
Write New Data: The process then writes new data files in the object storage.
Create New Metadata Tree: The writer then creates the required metadata files for the new snapshot, including new manifest files and a manifest list.
Create New Table Metadata File: Finally, the writer creates a new table metadata file (
.metadata.json). This new file contains all the information from the previous metadata file, but it also has an entry for the latest snapshot.Swapping the pointer: If all the above step succeeds, the writer requests the catalog to atomically update the pointer from the path of the old metadata file to the path of the new metadata file. The writer tells the catalog: "If the current metadata pointer is still
v1.metadata.json, update it tov2.metadata.json."If one of the above steps fails, the writer doesn’t request the catalog to swap the pointer; the file write during the process becomes orphaned. The readers don’t see these files
If the swapping pointer operation succeeds, the new table state becomes visible to all subsequent readers. If this operation fails, the transaction is aborted, and the written files (e.g., the table metadata file, data files, or metadata files) become orphaned and are eventually garbage collected.
Delta Lake
Overview
Delta Lake leverages the logging pattern to support atomic operations. A Delta Lake table is a cloud object storage directory that consists of the table’s data objects and a log of transaction operations.

The data in a table is stored in Apache Parquet objects, which can be organized into directories using Hive’s partition (if the table is partitioned). The log stores transaction metadata, such as data files added or removed during the transaction.

In the Delta Lake table directory, the transaction log is managed in a subdirectory called _delta_log. The log is a sequence of JSON objects with increasing, zero-padded numerical IDs (e.g., 000003). Each log record object contains a series of actions to apply to the previous version of the table, generating the next one.
How does it support atomic operations?
Compared to Iceberg, Delta Lake doesn’t need a dedicated catalog to provide atomicity. When making changes to the Delta Lake table, the writer must write a new JSON log object after successfully writing all the data files. The written files become orphaned and invisible to readers when:
If the process of writing data files fails.
If the writer fails to commit the new JSON log object
Let’s dive into the process of committing a new log object:

Read the _delta_log folder to get the table’s current state.
The writers write new data files.
If all files are written successfully, the writer attempts to commit the log object. It does this by trying to create the following sequential JSON file in the
_delta_logdirectory. For example, if the highest existing log file at the beginning of the write process is000001.json, the writer will attempt to create000002.json.
To ensure the log entry writing step is atomic, only one client should succeed in creating the log object with that name. Delta Lake uses put-if-absent operations from object storage for this purpose:
They use existing atomic put-if-absent operations from Google Cloud Storage and Azure Blob Store.
Initially, Amazon S3 did not support the put-if-absent operation, so Databricks relied on an external service to manage the table lock. The client must first acquire the table lock to ensure that only one client can add a record with each log ID. However, Amazon announced that they supported conditional writing to S3 in August 2024. I guess Databricks won’t need the external locking service anymore.
These operations are also referred to as `conditional writes`. The idea is simple: the writer will specify a condition (e.g., only write the data if the storage doesn’t have a
000002.jsonfile)
Hudi
Overview
Hudi has a unique design compared to the Iceberg or Delta Lake formats. The ultimate goal of it is what you see over and over again in this article: processing data incrementally as efficiently as possible. To achieve this, Hudi has:
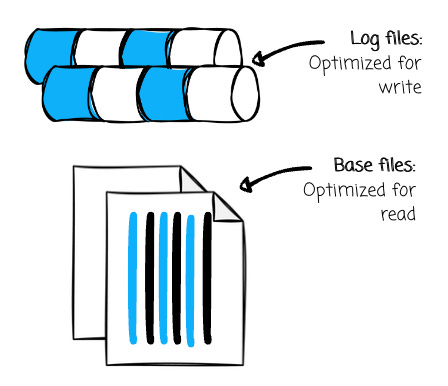
Two file formats: The base files store the table’s records. To optimize data reading, Hudi uses a columnar-oriented file format (e.g., Parquet) for the Base Files. The log files capture changes to records on top of their associated Base File. Hudi uses a row-oriented file format (e.g., Avro) for Log Files to optimize data writing.

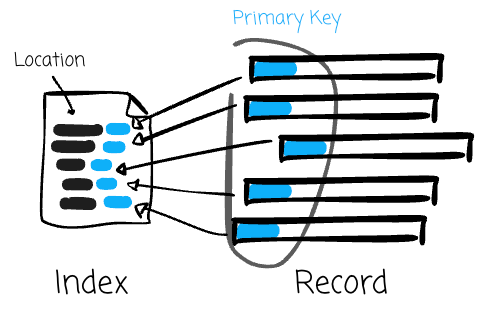
Primary key: Each record in a Hudi table has a unique identifier called a primary key, consisting of a pair of record keys and the partition's location to which the record belongs. Using primary keys, Hudi ensures no duplicate records across partitions and enables fast updates and deletes on records. Hudi maintains an index to allow quick record lookups.
Timeline: Hudi Timeline records all actions performed on the table at different times, which helps provide instantaneous views of the table while also efficiently supporting data retrieval in the order of arrival.



Essentially, Timeline shared some similarity to Delta Lake’s delta_log. It is physically stored as a set of files within the .hoodie directory at the root of the table path. Changes to Hudi tables are recorded as actions in the Hudi timeline.
Instants: Every action that occurs on a Hudi table, from data ingestion to background maintenance, is recorded on the timeline as an instant. Each instant is identified by a globally unique and monotonically increasing timestamp, which serves as its transaction ID. This timestamp is critical for ensuring a serial order of operations.
Actions and State Transitions: An instant is composed of an action type and a state. Hudi defines have key actions, including:
COMMIT: An atomic write of a batch of records to the base filesDELTA_COMMIT: An atomic write to a Merge-on-Read (MoR) table, which may involve writing to both log files and base files.COMPACTION: A background action that merges log files into the base files in an MoR table.CLEAN: A background action that removes old, unused file versions.ROLLBACK: An action that reverts a failed or partial commit.SAVEPOINT: An action that protects specific file versions from cleaning, enabling disaster recovery.…
Each action progresses through a series of states, with each transition being physically recorded by the creation of a new file on the timeline (located in the
.hoodiedirectory). The standard lifecycle is:<instant_time>.<action>.requested: The action has been scheduled but has not yet started.<instant_time>.<action>.inflight: The action is currently being executed.<instant_time>.<action>.completed: The action has finished successfully. The creation of this file is the atomic event that finalizes the transaction.
How does it support atomic operations?
The mechanism for achieving atomicity in Hudi is the final state transition on the timeline. The process for a write transaction is as follows:
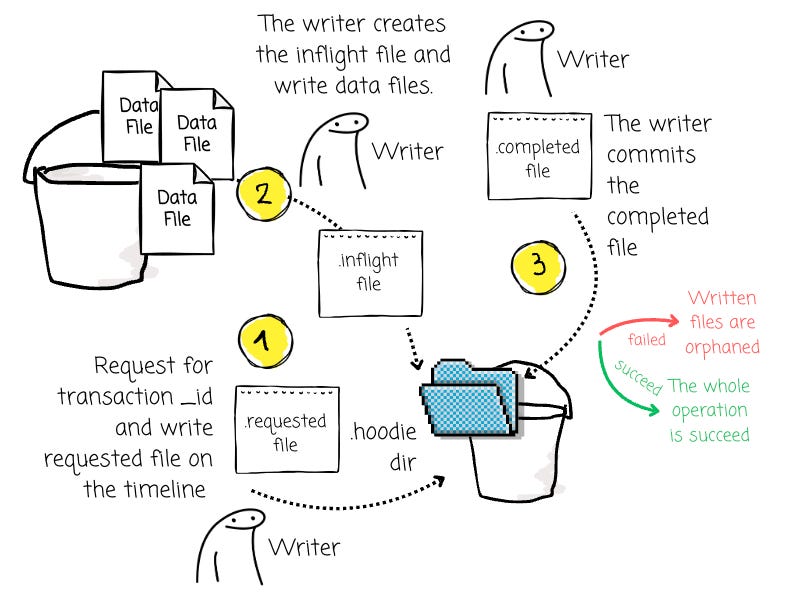
Request Instant: The write process begins by requesting a new, unique, and monotonically increasing timestamp for its transaction.
Mark as Requested: The writer creates the
<instant_time>.<action>.requestedfile on the timeline.Mark as Inflight and Write Data: The writer transitions the state to
inflightby creating the corresponding file and then proceeds to write the data files. During this phase, the new data is not yet visible to any query.Execute Atomic Commit: When all data is written successfully, the writer performs the final, atomic step: it creates the empty
<instant_time>.<action>.completedfile on the timeline. Like Delta Lake, this operation relies on the object storage’s `conditional writes` operation.
The atomicity of the entire transaction relies on the creation of this final file (<instant_time>.<action>.completed). Readers can only view the valid state of the table by consulting the timeline and reading data from instants marked as completed.
The written files become orphaned and invisible to readers when:
If the process of writing data files fails.
If the writer fails to create the
instant_time>.<action>.completedfile.
Outro
Thank you for reading this far. In this article, we revisit the high-level architecture of Iceberg, Delta Lake, and Hudi and explore how they ensure atomicity. Although this is a relatively short article compared to my recent work, I hope it can help you with some of the first steps when learning these table formats.
Now, see you next time.
Reference
[1] Tomer Shiran, Jason Hughes & Alex Merced, Apache Iceberg: The Definitive Guide (2024)
[2] Databricks, Delta Lake: High-Performance ACID Table Storage over Cloud Object Stores, (2020)
[3] Jack Vanlightly, Understanding Delta Lake's consistency model (2024)
[4] Timeline, Apache Hudi official document
[5] How does Hudi ensure atomicity? Design & Concepts FAQ, Apache Hudi official document