
How does Doordash evolve realtime processing platform with Iceberg
Apache Flink + Apache Iceberg

To celebrate Lunar New Year (the true New Year holiday in Vietnam), I’m offering 50% off the annual subscription. The offer ends soon; grab it now to get full access to nearly 200 high-quality data engineering articles.

Intro
In the previous article, we examined how DoorDash, one of the largest food delivery platforms in the United States, utilizes Apache Kafka, Apache Flink, and Snowflake for their real-time processing platform. They used Flink to consume Kafka messages and write them to S3, which is later loaded into Snowflake to serve data users.
Recently, DoorDash has shared how they improved this architecture with the introduction of Iceberg. Let’s dive into DoorDash’s motivation, challenges, and benefits of this decision.
All credit for the technical details goes to the DoorDash Engineering Team. This article serves as my note after consuming their technical sharing resource.
Background
DoorDash developed an internal streaming platform to process real-time events from applications, enabling efficient support for business decisions.
At peak, the platform might receive a very high throughput workload with more than 30 million messages per second, which is approximately 5 GB of event data flowing into their system per second. These events originate from customers, dashers, merchants, or DoorDash's internal applications.
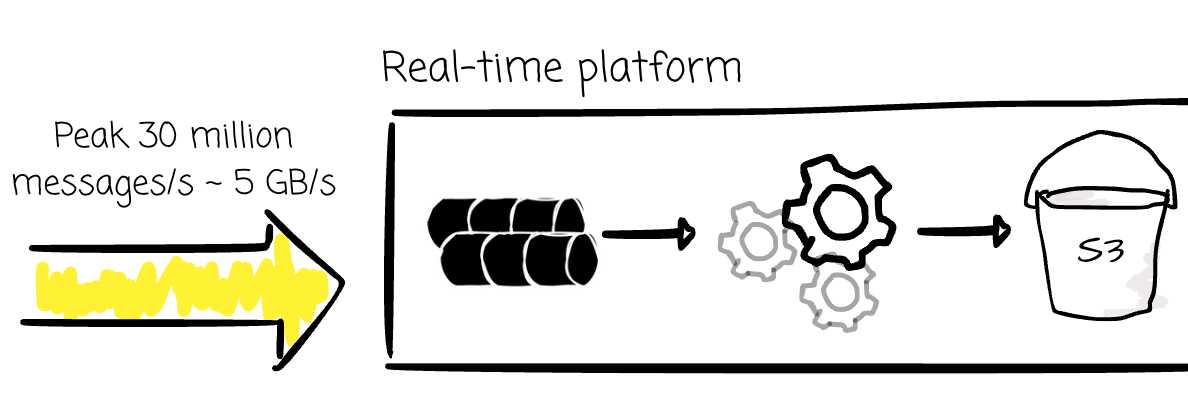
The stream platform will consume these events, process them, and write them to the associated tables in the data warehouse. Some use cases require the data to be available in near real-time.
So, how did DoorDash ensure their platform is low-latency and highly scalable?
As we recall from the previous article, DoorDash buffered incoming data with Kafka and used Flink to process and write the data to the sink.

Apache Flink is a framework and distributed processing engine for stateful computations over unbounded and bounded data streams, unlike Spark, which treats bounded data as a first-class citizen and aligns stream data into micro-batches. For Flink, everything is a stream; the batch is just a special case.
If you want to learn more about Flink, check out my article to understand its architecture and how it can achieve fault-tolerance and provide stateful processing capability.

The Flink application will consume the data from Kafka and upload it to S3 in the Parquet format. Then, DoorDash used Snowpie to copy data from S3 to Snowflake. Based on the notifications from the Amazon SQS, Snowpie will load data from S3 to Snowflake as soon as it is available using the COPY statement.
Challenges
The Flink → S3 → Snowpie → Snowflake has some challenges:
Snowflake's cost increases when more users use the data platform. When designing this solution in the first place, DoorDash only planned for hundreds of thousands of messages at peak, which is far smaller than the current peak workload (30 million messages)
The solution wrote the data twice, the first time is Flink writing data to S3, and the second time is Snowflake writing data to Snowflake

It’s vendor lock-in (Snowflake)

To celebrate Lunar New Year (the true New Year holiday in Vietnam), I’m offering 50% off the annual subscription. The offer ends soon; grab it now to get full access to nearly 200 high-quality data engineering articles.
Solutions
They chose Iceberg for the new real-time data sink. DoorDash also experimented with Delta Lake, but the table format didn’t meet their expectations in terms of operational and cost aspects.

From their perspective, Iceberg can help because:
The open table format has more mature support for Flink. In contrast, Delta Lake is more Spark-centric.
It offers flexible schema and partition evolution.
Iceberg has a very active community
It supports concurrent table writes. From what I know, this feature is not exclusive to Iceberg, as all table format supports concurrent writes with optimistic concurrency control.
Architecture
With the introduction of Iceberg, the DoorDash real-time processing platform remains the same, except for the S3 → Snowpie → Snowflake pipeline. Now, the Flink continues to sink data to S3 in Parquet format, but this time these files are “wrapped” with the Iceberg metadata layer.

The pipeline that writes data to Snowflake is not necessary anymore, as Snowflake users can query Iceberg data directly on S3. This enables data consumers to continue using Snowflake to interact with the data without major changes or interruptions. In addition, DoorDash also spins up Trino clusters to query this data with the help of the AWS Glue catalog.
To implement the new solutions, Doordash needs to adjust the Flink jobs.
A typical Flink application comprises three parts: the source, the transformation, and the sink. For the new approach, DoorDash only needs to change the application’s sink to the new one that writes data to S3 in Iceberg format.
Flink provides support for an out-of-the-box Iceberg sink connector, so DoorDash only needs to make minor code changes to make things work.
Challenges when adopting Iceberg
Schema Evolution
Although the Iceberg specification supports schema evolution, the Flink-Iceberg connector does not support it and requires the table schema to be static. If the schema changes, they have to stop the Flink job, adjust the logic, and restart it.
However, with all the benefits that Iceberg could bring (more on this later), DoorDash considers this not a very big deal.
Query Performance
Some users reported that their queries were very slow compared to the original solution. In these use cases, users typically query very large nested fields with hundreds of key-value pairs. This was handled well in Snowflake with the Variant Snowflake type.
DoorDash flattens these fields in Iceberg and allocates more resources for the query workload.
Benefit
So, is it worth it?
Cost saving
With Iceberg, Doordash observed a 25-49% reduction in storage costs compared to native Snowflake storage, using only the default compression scheme (zstd).
The cost savings also come from the elimination of duplicate data writing from the original solution, which writes data first to S3 and later loads it to Snowflake's native storage.
The resources used for Snowpie are now allocated for the Iceberg operation process, such as table compaction.
The reliability and availability
The support for concurrent writes enables DoorDash to develop multiple pipelines for a single Iceberg table. This allows them to write data from different sources or have different workloads, such as a standard data sink pipeline along with the backfill pipeline at the same time.
DoorDash also enjoys the native support of Iceberg’s time travel. Although Snowflake also supports this feature, users must pay more to achieve higher data retention. With Iceberg, DoorDash can achieve time travel capabilities with more control over data retention.
The Iceberg adoption aligns with their data-lake approach, which limits the dependency on any vendor, thus providing them more flexibility. For example, they can now use other engines such as Trino to query the data.
Hidden Partitioning
Generally, partitioning a table using a transformation on a column (e.g., partition by day requires transforming the timestamp column to day and creating an extra column). Users must use this exact column to benefit from partition pruning.
For example, a table is partitioned by day, and every record must have an extra partition_day column derived from the created_timestamp column. When users query the table, they must filter on the exact partition_day column so the query engine can prune unwanted partitions. If the user isn’t aware of this and uses the created_timestamp column instead, the query engine will scan the whole table.

This is where Iceberg’s hidden partitioning shines:

Instead of creating additional columns to partition based on transform values, Iceberg only records the transformation used on the column.
Thus, Iceberg can save storage cost because it doesn’t need to store extra columns.
Another challenge with traditional partitioning is that it relies on the physical structure of the files being laid out into subdirectories; changing how the table was partitioned required rewriting the whole table.
Apache Iceberg solves this problem by storing all the historical partition schemes. If the table is first partitioned by scheme A and then later partitioned by schema B, Iceberg exposes this information to the query engine to create two separate execution plans to evaluate the filter again with each partition scheme.
Given a table initially partitioned by the created_timestamp field at a monthly granularity, the transformation month(created_timestamp) is recorded as the first partitioning scheme. Later, the user updates the table to be partitioned by created_timestamp at a daily granularity, with the transformation day(created_timestamp) recorded as the second partitioning scheme.
The data will be organized according to the partition scheme in place at the time of writing.

When the application queries this table using created_timestamp, the query engine applies both the first and second transformations to created_timestamp to enable partition pruning.

By leveraging Iceberg’s hidden partition, DoorDash helps users feel less confused when they need to know precisely what technical columns are used for partitioning.
My thought
One of the advice I remember the most after reading the book Fundamentals of Data Engineering is choosing common components wisely.
According to the author, data engineers should select common components that facilitate team collaboration and break down silos. They could be S3 for object storage, GitHub for version-control systems, Airflow for orchestration tools, or Spark for processing engines.
These components act like a toolkit for solving problems and prevent the need to reinvent the wheel. For the lake house specific problem, Iceberg is a strong candidate for your organization’s common component. It can work well with many systems. If you open a document from any cloud data warehouse or data processing engine, there is a very high chance that you will see Iceberg support at some level.
This provides you with more flexibility. You can make more reversible decisions. You no longer like Snowflake and want to try BigQuery, or you want to return to a self-managed, open-source solution engine like Trino. Iceberg can help you with that.
This does not mean Iceberg is the go-to choice for any data project. Every technical decision will have trade-offs, and the data practitioners should evaluate and make decisions based on the organization’s needs, not following trending tools.
Compared to using managed cloud data warehouses like BigQuery or Snowflake with their native storage offerings, adopting Iceberg requires more effort to understand how the table format works behind the scenes.
With DoorDash, I think they made a very good choice by storing data in S3 in the first place, rather than loading it directly into Snowflake. This might come from the intention of having total control over their data, but over time, this choice brings them many benefits. The most obvious one we see in this article is that it helps them onboard Iceberg more easily onto the platform.
Another observation is that we can see the advantage of “working well with many systems “ from the Iceberg, which could help DoorDash operate the Flink-Iceberg connection with just a few problems that could be easily debugged and fixed. From their sharing, DoorDash mentions more than once that they have trouble getting Flink to work with Delta Lake.
Outro
In this article, we explore the motivation for the adoption of Iceberg for their real-time process platform, including its architecture, challenges, and benefits of the new approach. Finally, I have some thoughts on the trend of adopting Iceberg.
Thank you for reading this far. See you in my next article.
Reference
[1] Tristan Culp, Gaurav Sharma, Iceberg with Flink at DoorDash (2025)
Showpie should be snowpipe
Great article. What i didn't understand is that how did door dash solve the following:
1. Iceberg is not great with frequent updates. Did they use iceberg v3?
2. Iceberg has a limit on number of concurrent writers it can support. How did they get over this.
3. Since fetching data from s3 is slow, how did door dash adapt their architecture to power real time analytics using iceberg?