
I spent 5 hours learning how ClickHouse built their internal data warehouse.
19 data sources and a total of 470 TB of compressed data.

To celebrate the launch of learn-spark for paid subscribers, the CLI tool that helps you learn Spark faster and more affordably right on your laptop. I’m offering you a 50% discount on the annual plan—grab it now to get access to the learn-spark tool!
After becoming a paid subscriber, visit this link to get invited to the learn-spark repo.
The offer ends VERY SOON!

Intro
You might have heard of ClickHouse.
You might know that ClickHouse is fast for both real-time and batch analytics.
But here’s something you might not know: how the engineers at ClickHouse — the company behind one of the world’s most powerful OLAP systems — build their internal data warehouse.
This blog post shares my takeaways after reading insights from their engineers. We’ll explore how they built their data warehouse and continuously improved and strengthened it to handle 50 TBs of data daily.
Background
ClickHouse is a high-performance, open-source columnar database designed for fast, real-time analytical queries. Built to handle large-scale data, it excels in OLAP scenarios, delivering rapid query execution even on massive datasets.
In May 2022, ClickHouse launched its cloud product.
When you launch a product, you want to know how customers use it. Do they like it? Is the product working well?
ClickHouse wanted to answer these questions, too.
They aim to better understand their customers, including how they use the service, the challenges they face, how ClickHouse can help, and how to make pricing affordable.
ClickHouse needed to collect and process data from several internal sources: the Data Plane, which manages customer database pods (on Kubernetes); the Control Plane, which handles the customer-facing UI and database operations; and AWS Billing, which provides exact cost details for running customer workloads.
So, they built an internal data warehouse with their own product, ClickHouse Cloud, at its core. In the following sections, we will explore this in more detail.
Before building the data warehouse, internal users had to perform manual analysis using Excel.
I think using their own product is a great way to gain a deeper understanding of it from a customer’s perspective.
The first stage
Overview
From a 10,000-foot view, here are the tech stacks that ClickHouse initially used to build their data warehouse.
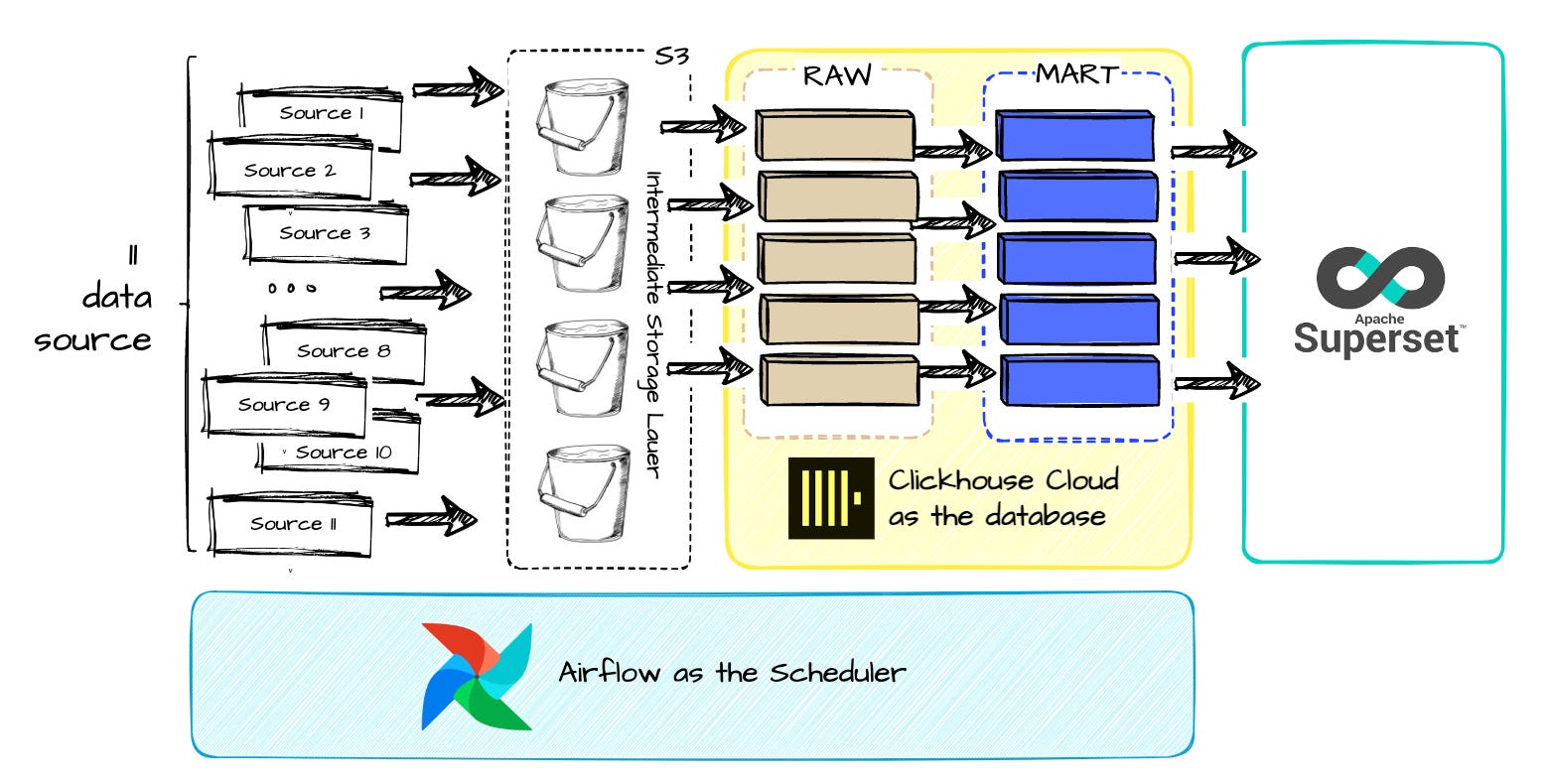
They used Airflow as the scheduler.
They used AWS S3 for the data intermediate layer.
They used Superset for the BI tool and SQL interface.
And, of course, Clickhouse Cloud is used as the database and processing engine.
Data source
Following their sharing, here is the list of sources they planned to ingest into their warehouse:

Infrastructure/Service Costs and Usage
AWS CUR: AWS costs and usage for infrastructure.
GCP Billing: GCP costs and usage.
AWS Public Prices: Prices for every AWS SKU across regions.
GCP Prices: Prices for every GCP SKU across regions.
Database and System Metrics
Control Plane: Meta information about database services (type, size, CSP region, scaling settings, etc.).
Data Plane: Database system metrics (stats, query stats, table stats, pod allocation, etc.).
Galaxy: Event-based observability and control plane/UI layer monitoring.
Customer and Billing Information
Salesforce (CRM): Customer account data, usage plans, subscriptions, discounts, leads, and support issues.
M3ter: Accurate billing and usage information.
Marketing and Event Data
Segment: Additional marketing data.
Marketo: Sent email meta information.
With these sources, they made the following assumptions:

To celebrate the launch of learn-spark for paid subscribers, the CLI tool that helps you learn Spark faster and more affordably right on your laptop. I’m offering you a 50% discount on the annual plan—grab it now to get access to the learn-spark tool!
After becoming a paid subscriber, visit this link to get invited to the learn-spark repo.
The offer ends VERY SOON!
Data Transformation and Serving
To ingest and capture data from multiple sources to S3 buckets, they employ the following approaches:

Regarding the large fact tables, they collect incrementally every hour. For tables that have updated existing records, they take a snapshot of the whole table every hour.
Hourly data collected in the S3 bucket is imported into the ClickHouse database using the ClickHouse S3 table function.
ClickHouse S3 table function provides a table-like interface to select/insert files in Amazon S3 and Google Cloud Storage.
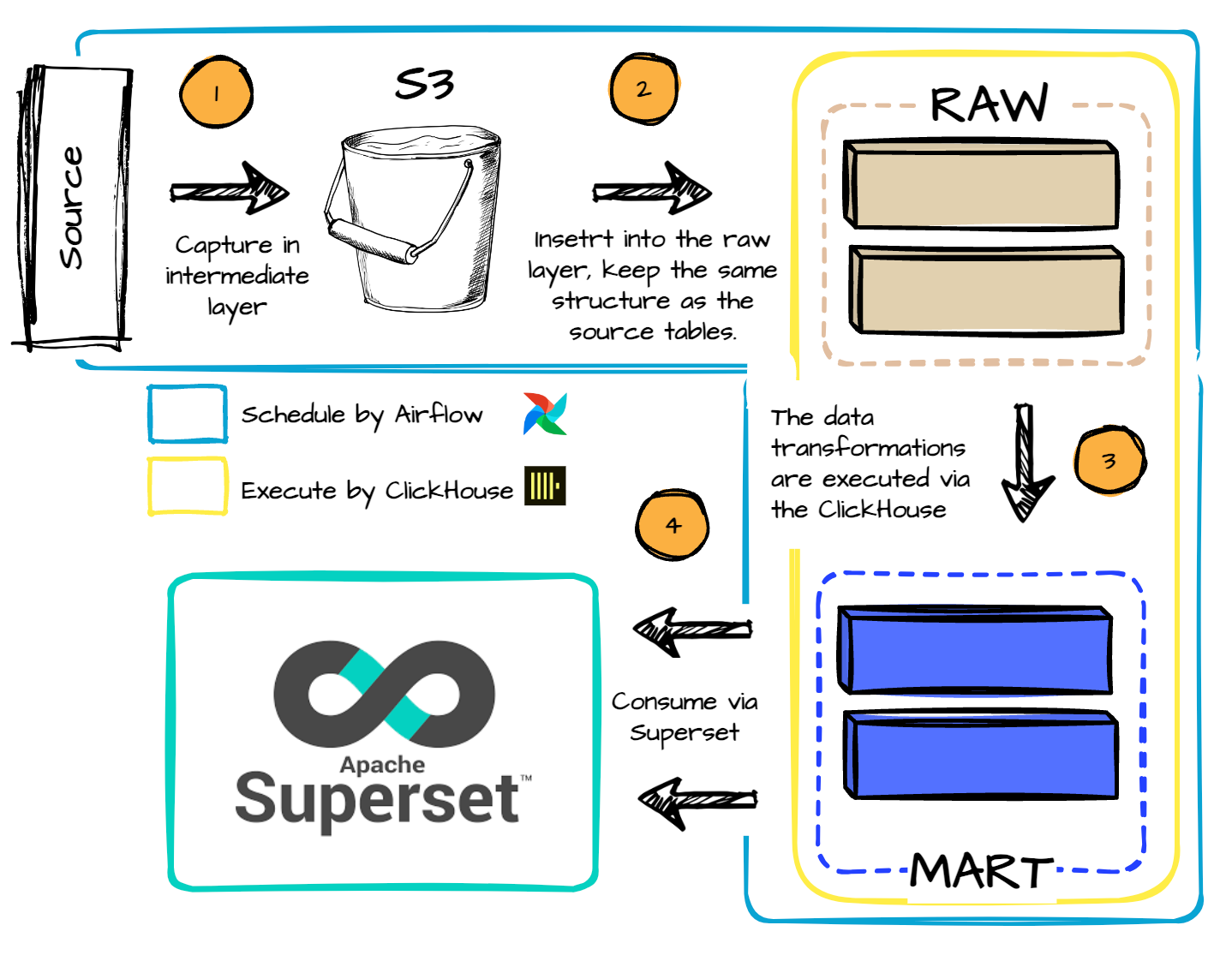
The data is first inserted into the raw layer, maintaining the same structure as the source tables.
The data transformations are carried out via the Clickhouse engine with the help of the Airflow scheduler.
Transformed data is put into a marts table, which represents business entities and meets the needs of internal stakeholders.
For data consumption, internal users query MART tables and create charts and dashboards using Superset.
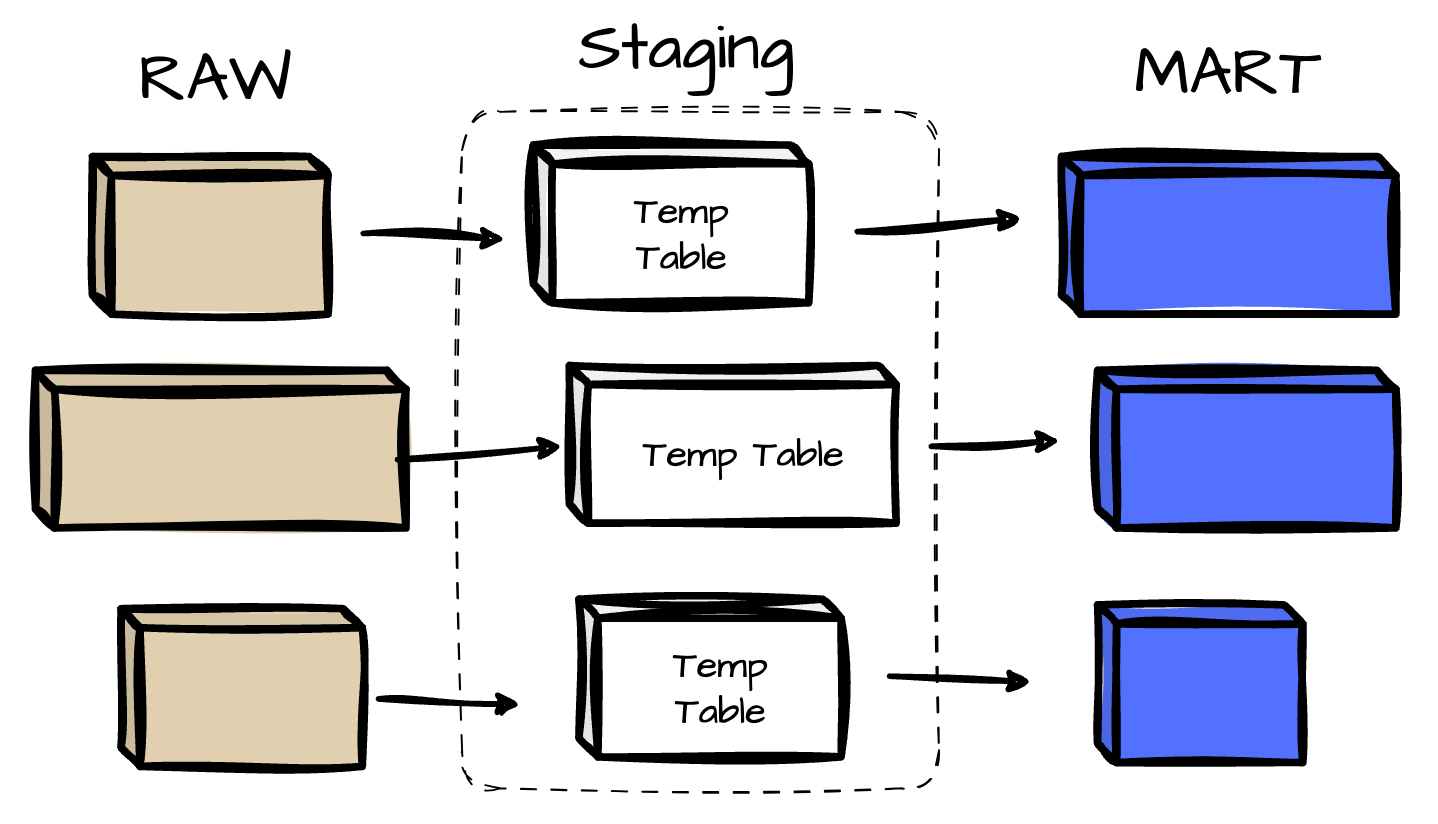
Many temporary tables are created between the raw and mart tables during the transformation. Transformed data is first written to a staging table before being inserted into the target table. This provides flexibility by allowing the reuse of these staging tables. Each staging table has a unique name for every Airflow DAG run.
Idempotency
To achieve idempotency, tables in ClickHouse use the ReplicatedReplacingMergeTree engine, which handles duplicates by retaining only the latest record for each key. This allows data for a specific hour to be inserted multiple times without duplication.
Because Airflow jobs/DAGs can retry multiple times for the same data interval, using ReplicatedReplacingMergeTree makes the pipeline idempotent, allowing safe re-execution without duplicates.
Consistency
By default, ClickHouse offers eventual consistency, which may work well for real-time analytics but can be less ideal for data warehouse (DWH) scenarios. For instance, inserting data into a staging table might lead to partial data availability; the next step in the data pipeline could read data when only three out of four nodes have received the written data, resulting in incomplete data being read.
To address this, ClickHouse provides a consistency mode that ensures data is replicated across all nodes before returning success. By setting insert_quorum=n (n is the total number of nodes in the cluster), data is guaranteed to be in all replicas. The trade-off is that the latency will be higher, but for batch processing, this isn’t a significant issue with ClickHouse.
Infrastructure
Given the goal of building a simple data warehouse solution that is easy to operate and scale, they deployed the whole infrastructure using Docker containers:

The setup includes separate machines for the Airflow web server, Airflow worker, and Superset, all running in Docker containers.
On Airflow machines, a container runs every 5 seconds to synchronize the repository containing DAG code, ELT queries, and configuration files with the local machines.
Superset is used for dashboards and alerts and is supported by schedulers and worker containers.
Airflow and Superset share a Redis instance on a separate machine. Redis handles execution states for Airflow and cached query results for Superset.
AWS RDS for PostgreSQL serves as the internal database for both Airflow and Superset.
Two environments (Preprod and Prod) run independently with their own ClickHouse Cloud, Airflow, and Superset setups.
The Preprod environment remains consistent, allowing a seamless switch in case the Prod environment becomes unavailable.
Develop Flow
The developer creates a branch from the dev or production branch.
The developer makes changes.
The developer creates a Pull Request (PR) for the Preprod branch.
Once the PR is reviewed and approved, changes are tested in the Preprod env
When changes are ready for production, they create PR from the Preprod to the Prod.
Airflow Design

Essentially, they design their DAGs as follows:
Separate DAGs for loading data from the source to S3 (e.g., M3ter to S3).
A single main DAG that handles all data transformation when data arrives in S3. All required dependencies are listed within the tasks of the main DAG.
Enhancement
dbt

After a year, the number of data sources grew from 11 to 19, requiring a more efficient process for onboarding new sources.
In the initial design, raw data was ingested from the source into S3 buckets and then transformed by ClickHouse to generate reports for internal users. Most of the processes were managed through Airflow. However, this approach became unsustainable as they added more data sources, developed complex business metrics, and served an increasing number of internal stakeholders.
To address this, they adopted dbt to centralize the transformation logic for batch reporting.
Real-time analytics
Based on user feedback, they began incorporating more real-time data sources into reporting, as this type of data was highly valuable and intuitive, even if it was less structured and required light processing during queries (e.g., parsing fields from JSON columns).
The engineers exposed this real-time data in raw and transformed formats. ClickHouse’s library and supported data formats made exploring raw real-time data convenient, allowing users to perform SQL analysis without needing data engineers' direct support.
The combination of the dbt and Clickhouse database lets users combine batch-processed reporting with real-time data streams.

They use dbt to define aggregations for real-time data. These aggregations are also configurable within ClickHouse using features like materialized views. Real-time aggregations are joined with existing reports to track and enrich metrics such as the "number of customers with failed queries."
More options for data consumption
In the first iteration, ClickHouse used Apache Superset as the BI tool for users to access data. At this stage, the only way for users to query data in ClickHouse was through Superset's SQL client. However, they found that the Superset SQL client had many bugs, negatively impacting the user experience.

To resolve this, they let users access the data warehouse via ClickHouse Cloud's native SQL console. The SQL console offered a significantly better experience for users writing ad-hoc SQL queries and exploring various database tables and views. Users shared that the SQL console provided a superior experience to Superset's native SQL client.
For A/B testing, they integrate GrowthBook into Clickshouse, allowing users to run A/B tests using data from the data warehouse. Because GrowthBook directly queries ClickHouse Cloud, running experiments on raw, log-level data is easy.
Clickhouse also set up a data export job from ClickHouse Cloud to Salesforce, enabling the sales team to consume DWH data directly in the CRM. They pushed the data from the warehouse into an S3 bucket and let Salesforce query the bucket as needed.
Outro
In this article, we’ve explored the journey of ClickHouse as they built their internal data warehouse around ClickHouse Cloud. We saw how they landed data from multiple sources using S3 as an intermediate layer, executed data transformations, and achieved idempotency and consistency with the help of the ClickHouse database. Finally, we learned how they elevated their data platform by introducing dbt.
Now, it’s time to say goodbye. See you in the next blog!
P.S. Do you want to read a dedicated article about the Clickhouse database in the future?
References
[1] Dmitry Pavlov, How we built the Internal Data Warehouse at ClickHouse (2023)
[2] Mihir Gokhale, How we built our Internal Data Warehouse at ClickHouse: A year later (2024)
Before you leave
If you want to discuss this further, please leave a comment or contact me via LinkedIn, Email, or Twitter.
It might take you five minutes to read, but it took me more than five days to prepare, so it would greatly motivate me if you considered subscribing to receive my writing.