
I spent 8 hours learning CSV, JSON, Avro, and Parquet
File Formats for Data Engineers

To celebrate Lunar New Year (the true New Year holiday in Vietnam), I’m offering 50% off the annual subscription. The offer ends soon; grab it now to get full access to nearly 200 high-quality data engineering articles.
Intro
We, data engineers, work with data nearly every day. We capture and consolidate digital data from multiple sources, transform it, and store it.
For every data interaction, we:
Write data to disk
Or, read data from disk.
From pulling data from a remote server via API to appending data to a table, we interact with digital records persisted on physical disks. However, we don’t work directly with the raw device, such as an HDD or SSD, most of the time. We work with the file abstraction instead
Not every file is the same. They differ in the way the data is organized, making data writing and reading ideal for specific use cases.
A photographer might not care how his image is stored in a PNG file. However, data engineers should pay attention to how data is organized and ensure that data read-write operations are as efficient as possible.
This article explores the most common file formats that data engineers may encounter: CSV, JSON, Parquet, and Avro.
Text-based format vs binary format
It’s helpful to understand the difference between text and binary formats.
All data stored on a disk is a sequence of 0s and 1s. However, the way these 0s and 1s are interpreted distinguishes the "text-based" file from a "binary" format.
Text-based formats rely on character encoding to serve as a dictionary between binary numbers and the characters displayed on the screen.
Every single character—a letter like 'A', a number like '9', or a symbol like ','—is assigned a unique numerical code by a standard like ASCII or Unicode. When you save a text file, the computer converts each character into its corresponding binary representation.
The most important benefit of text-based files is that they are human-readable. We can read and edit the text files using Notepad or collaborate on Google Docs. It will be a nightmare if you open a .py file and try to adjust a function by editing bits 0 and 1.
However, this approach creates a crucial inefficiency, especially for numbers. To store the number 256, the computer stores the binary codes for three separate characters: '2', '5', and '6'. This takes up more space and requires the computer to perform an extra step of parsing these characters back into a single number during processing.
Not caring much about whether humans can understand it or not, the binary format is designed for machine efficiency. While strings within a binary file are still encoded (typically using UTF-8), other data types are stored in their raw, native binary form.
The number 256, in a binary format, stores the direct mathematical representation of that integer. For example, as a 16-bit integer, it would be stored as 00000001 00000000.
This approach is far more compact and faster for a computer to process. There is no need to parse three separate characters and convert them into a number; the CPU can interpret the binary value directly.
CSV
Characteristics
At its core, Comma-Separated Values (CSV) is a plain-text format designed to store data in a structured manner. When opening a CSV file in any text editor, you will see text that is separated by newline characters.
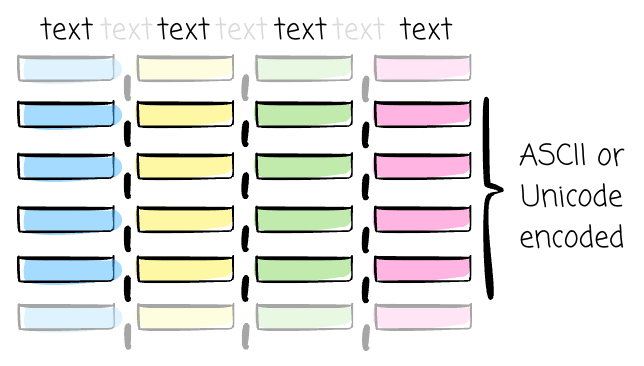
Each line in a file represents a data record or row. The values within that record are separated by a delimiter, which is typically a comma. Every line should have the same fields. (The exact number of commas.).
The format's simplicity makes it universally understood by nearly every data application, from spreadsheet programs like Microsoft Excel to relational databases. This factor makes it the widely adopted option for data exchange, especially with non-technical stakeholders.
The primary advantage of CSV is its compatibility and ease of use. Users can display the contents in the CSV file in a well-organized table via Google Sheets, edit, and update it with their keyboard.
Challenges
However, some things must be considered:
A CSV file has no built-in mechanism for defining a schema or enforcing data types. This put the responsibility on the reading system to parse and interpret the data.
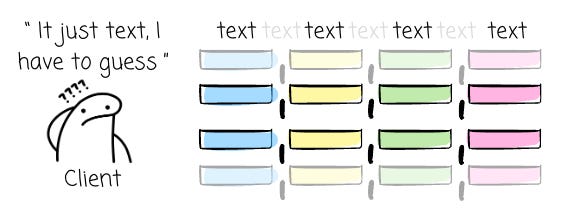
This process is not only computationally intensive but also a common source of critical errors, such as “1“ should be a string, not a number.
To ensure a reliable parsing process, it is recommended that the reader tell the system about the column’s data type and schema beforehand.
The format's lack of a standard leads to numerous potential failure points that make ingestion pipelines brittle. Common issues include:
Delimiter Conflicts: Data fields that naturally contain the delimiter (e.g., a text description containing a comma) can break the structure if not properly escaped.
Inconsistent Quoting: There is no universal rule for when to quote fields, leading to ambiguity that parsers must resolve.
Varying Encodings: While UTF-8 is a best practice, it is not guaranteed. Files may arrive in different encodings, which can lead to data corruption if not handled explicitly.
Not good for analytics: As a row-oriented text format, CSV is fundamentally inefficient for large-scale analytics. To access a single column, the entire row must be read from disk and processed, leading to excessive I/O.
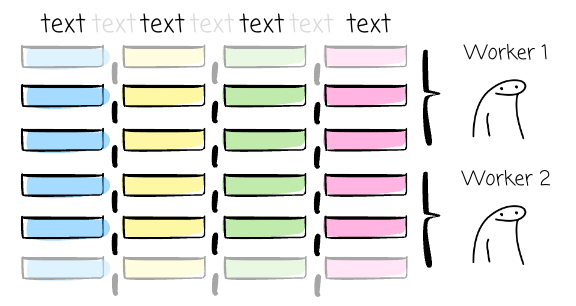
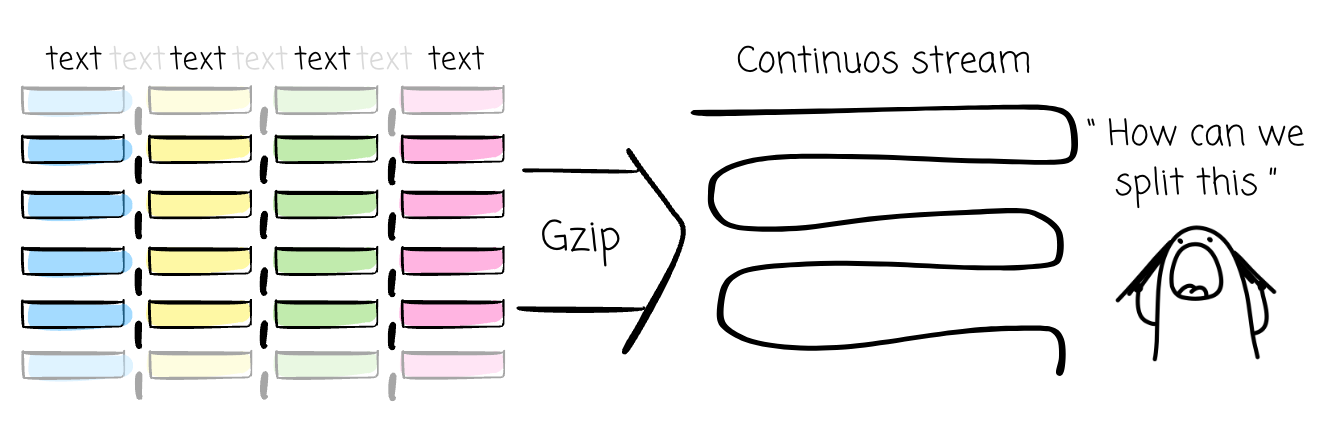
An uncompressed CSV file is splittable and can be read in parallel. Because each line in the file represents a complete, independent record, different workers can handle a set of lines.
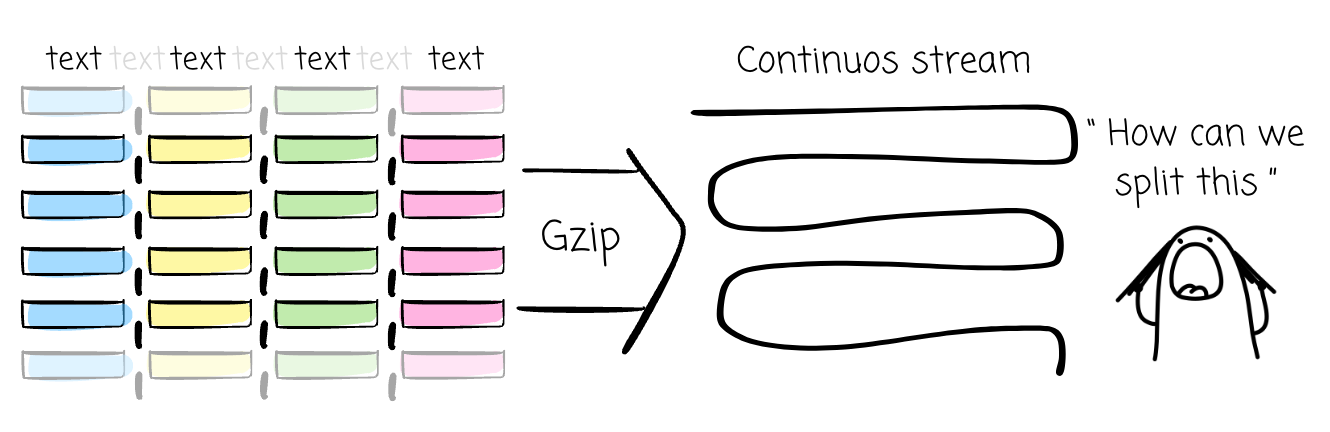
However, if we use a non-splittable compression algorithm, such as Gzip, the entire file becomes a single, continuous compressed stream. A processing engine can’t divide the work.
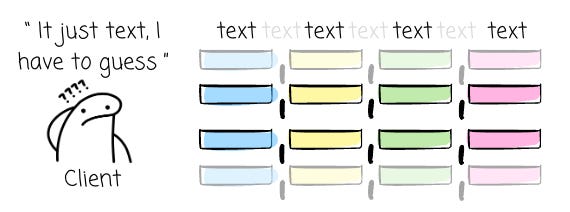
CSV lacks support for nested and repeated data.
JSON
To celebrate Lunar New Year (the true New Year holiday in Vietnam), I’m offering 50% off the annual subscription. The offer ends soon; grab it now to get full access to nearly 200 high-quality data engineering articles.