
DuckDB at a high level
The motivation, what make it fast, how it is used in production and more.

With only $7/month (billed annually), you can access all the materials you need to grow from junior → senior DE.
200+ deep-dive data engineering articles
practice-spark: 65 LeetCode-style problems to practice Spark SQL/DataFrame
learn-spark/dbt/airflow: CLI tools to master Spark/dbt/Airflow
If you’re a student with an education email, use this 50% ANNUAL DISCOUNT
If you’re a Vietnamese user, please DM me for an upgrade due to payment issues. As compensation for the inconvenience, you’ll get 50% OFF the annual plan.
If you'd like more articles on DuckDB, please give a like or comment to let me know.

Intro
About 20 years ago, people thought we needed a lot of machines and complex programming abstraction to process and analyze data. Everyone wants MapReduce.

About 10 years ago, people still thought we needed a lot of machines to process and analyze data; however, the programming abstraction must be simpler. Everyone wants Spark.

Recently, people haven’t thought that way anymore.
We can now process and analyze data with only a single machine and a simpler programming abstraction.
Single-node processing tools, such as DuckDB (SQL) and Polar (DataFrame API), are receiving increasing attention.

I believe that when a medium-sized company starts building its data infrastructure, Spark is no longer the only option on its list, given that DuckDB and Polar can handle hundreds of GB of data with unfair simplicity.
—
I analyzed the rise of the single-node processing tools in the past. What I’m trying to do in this article is discuss DuckDB, a unique OLAP system introduced in 2019 that is gradually changing our thinking about “big data”.

Note: This article is NOT sponsored by DuckDB. What you're gonna read is based purely on my own research and understanding.
The motivation
DuckDB is quite unique, not only in the OLAP world but in the database world in general.
Most databases are designed on a client-server model, where the client (you) and the server (the database) are usually on separate compute instances.
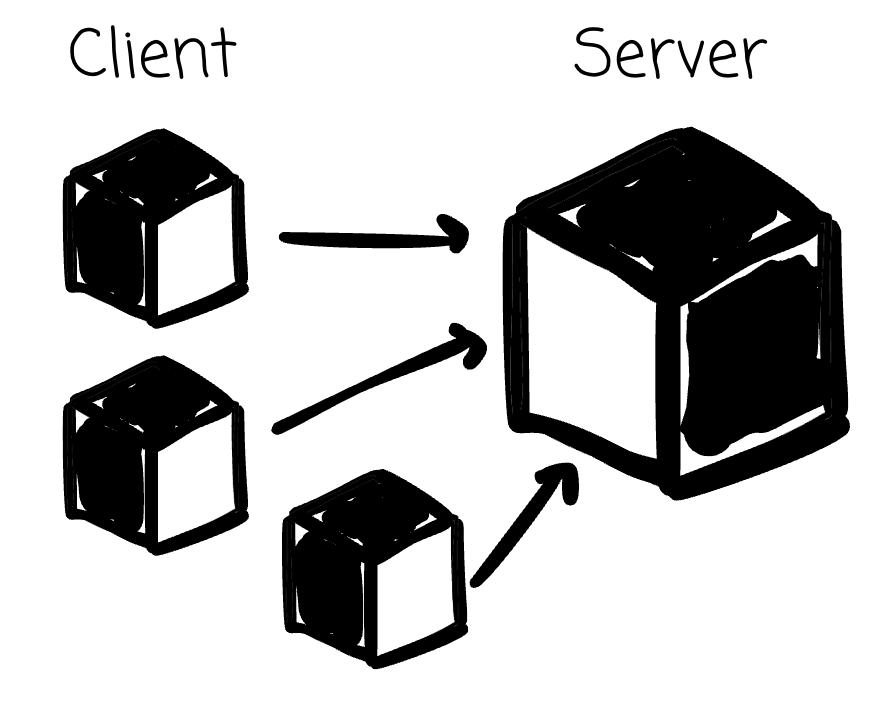
DuckDB isn’t like that. It aligns with the philosophy of simplicity and embedded operation, drawing inspiration from the famous SQLite (from the OLTP world).
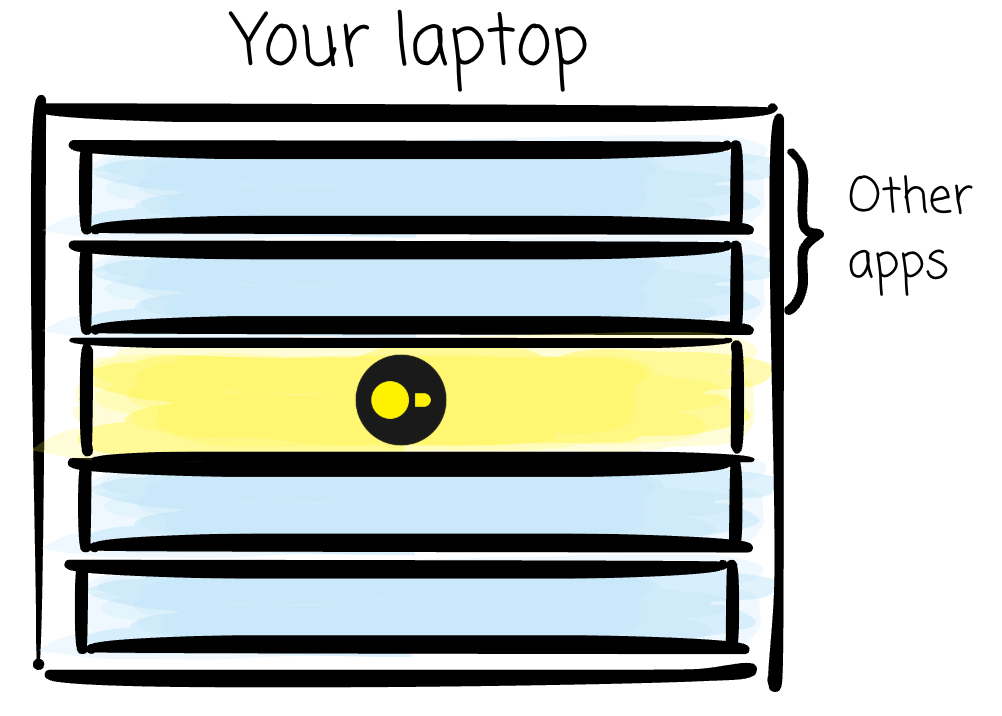
From the user’s point of view, DuckDB is simply an SQL interface running alongside other applications on your laptop, integrating the (powerful) analytical functionality into the host process.
In other words, when you install DuckDB on your laptop, it runs as a process, just like other applications, such as Chrome or Visual Studio Code.
—
Mark Raasveldt, co-founder of DuckDB Labs, spent his PhD solving a problem.
At a database architecture research group, surrounded by people whose entire job title started with the word “data,” and who still avoided database systems entirely.
Terabytes of CSVs sitting on disk, but they prefer scripting languages like Python or R rather than traditional databases. Mark didn’t stand it. A piece of technology with 50 years of engineering behind it: query optimizers, compression, concurrency control, all the stuff people spend entire careers on, and the people whose job is literally "data" want nothing to do with it.
The challenges are:
Setting up a client-server database (even something as lightweight as Postgres) is quite overhead, especially with ones that only want to work with data (e.g., data scientists).
Getting data in and out of the database is costly. To process data, they must ingest it into the database. To route the data to other systems, they have to extract it from the database (e.g., port the data to Pandas). However, moving (a decent amount of) data effectively is always a challenge.

And, the dependencies are worth mentioning here. If you pack your analytical logic in a Jupyter notebook or a shared script, a client-server database introduces external state. Now your “self-contained” snippet of code depends on a server (database) running somewhere else.

SQLite solved some of this; it’s embedded, no server, just a library you import. But SQLite is an OLTP. Single-threaded, built for point lookups and small writes.
So product-market fit might look like this: something with SQLite’s embedded philosophy, but built for analytics from the ground up: columnar, vectorized, parallel, easy data integration.
That’s the motivation behind DuckDB.
Architecture
With only $7/month (billed annually), you can access all the materials you need to grow from junior → senior DE.
200+ deep-dive data engineering articles
practice-spark: 65 LeetCode-style problems to practice Spark SQL/DataFrame
learn-spark/dbt/airflow: CLI tools to master Spark/dbt/Airflow
If you’re a student with an education email, use this 50% ANNUAL DISCOUNT
If you’re a Vietnamese user, please DM me for an upgrade due to payment issues. As compensation for the inconvenience, you’ll get 50% OFF the annual plan.