
Diving Deep into LinkedIn's Data Infrastructure: My 6-Hour Learning & Key Takeaways
Things I distill after reading the paper: Data Infrastructure at LinkedIn

To celebrate the launch of learn-spark for paid subscribers, the CLI tool that helps you learn Spark faster and more affordably right on your laptop. I’m offering you a 50% discount on the annual plan—grab it now to get access to the learn-spark tool!
After becoming a paid subscriber, visit this link to get invited to the learn-spark repo.
The offer ends VERY SOON!

Intro
While writing the Kafka series, I came up with a paper from LinkedIn on how they built their data infrastructure. Read next to get everything I distill after reading the paper.
Instead of covering all the tools, the paper just introduced some important LinkedIn internal solutions: Voldemort (the key-value store), Databus (the CDC solution), Espresso (the document data store), and Kafka (the messaging system).
Let’s overview the data architecture at LinkedIn before we delve into each tool.
Overview
At LinkedIn, there are three logical service tiers: a data tier that maintains a persistent state (e.g., user data), a service tier that implements an API layer, and a display tier for translating APIs into user interfaces. These tiers communicate via RPC. The service and display tiers are stateless, providing them with better scalability; they don’t need to move data around in case of node adding or removing: data can be re-loaded from the persistent tier.
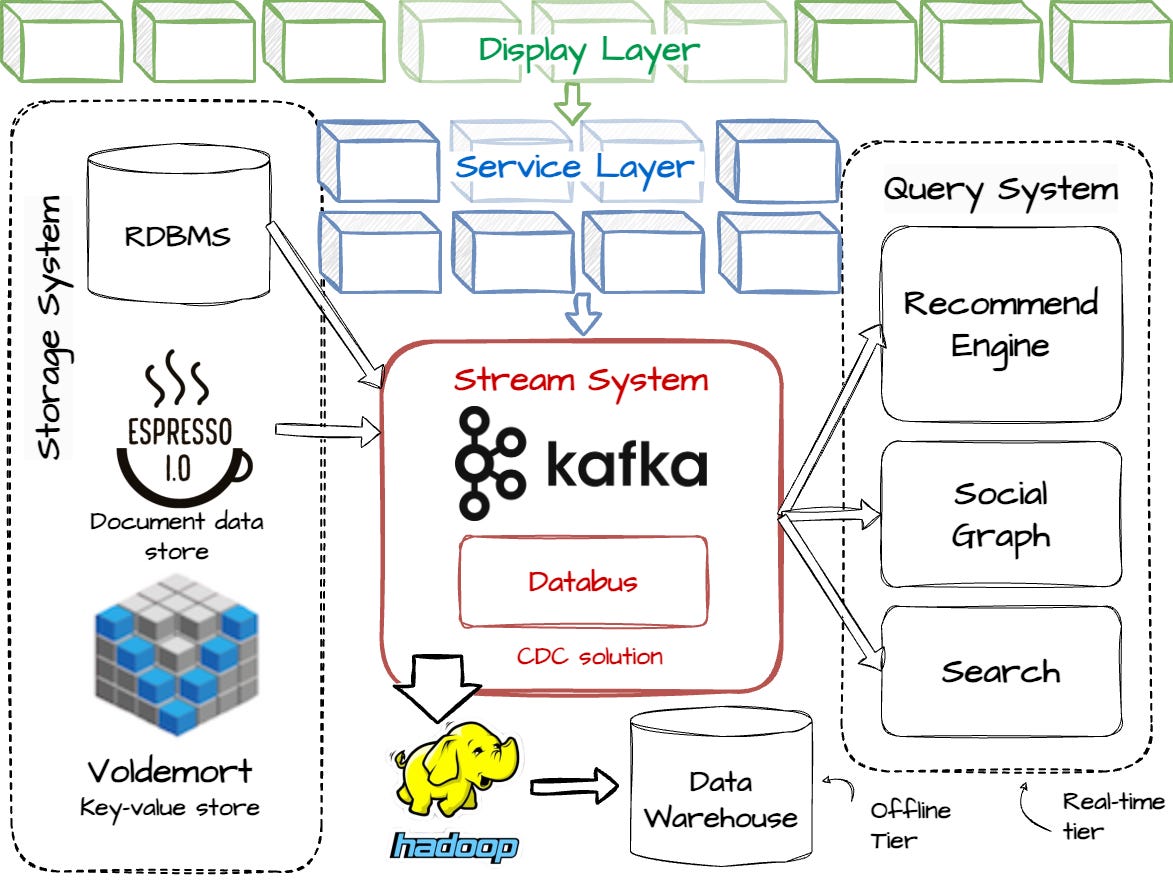
LinkedIn’s core data system has the following pieces:
Live storage is a variation of traditional OLTP databases, which power web applications and serve most of the data requests from the user.
Stream systems deliver data to applications and various other data systems.
Social Graph serves graph queries. For example, the graph will serve the queries showing user paths.
The recommendation and Search systems are responsible for people search, one of LinkedIn's core features.
Batch computing consists of large-scale offline data processing jobs that run at fixed intervals, e.g., hourly or daily. It is divided into two categories: jobs that generate datasets for the website’s users and jobs for analytics workloads.
The following section will discuss Voldemort, the key-value store solution at LinkedIn.
Voldemort
🧙🏻♀️ He-Who-Must-Not-Be-Named
Overview
Voldemort is a highly available, low-latency distributed data store developed at LinkedIn in 2008 to serve as a key-value store for products like “Who viewed my profile?”. Later, Voldemort was improved to add nodes without downtime, which support scaling to handle tens of thousands of requests per second.
Architecture
A Voldemort cluster can have many nodes, each with a unique ID. Tables in Voldemort are called stores. Each store is located in a single cluster, and the store’s partition is distributed to all cluster nodes. Every store has its configurations, like the replication factor, the schema, and the required number of nodes to participate in reading and writing.
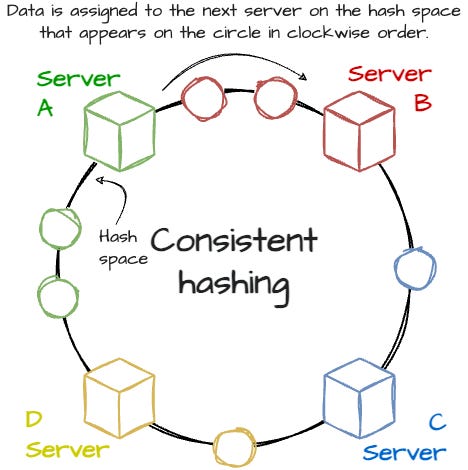
Voldemort used consistent hashing to allocate the store’s partition to nodes in the cluster. To understand the hashing mechanism better, check out this video from the ByteByteGo channel: Consistent Hashing | Algorithms You Should Know #1.
Voldemort's architecture is pluggable, inspired by Amazon's Dynamo paper. Every module implements the same code interface, making it easy to interchange modules and test code.
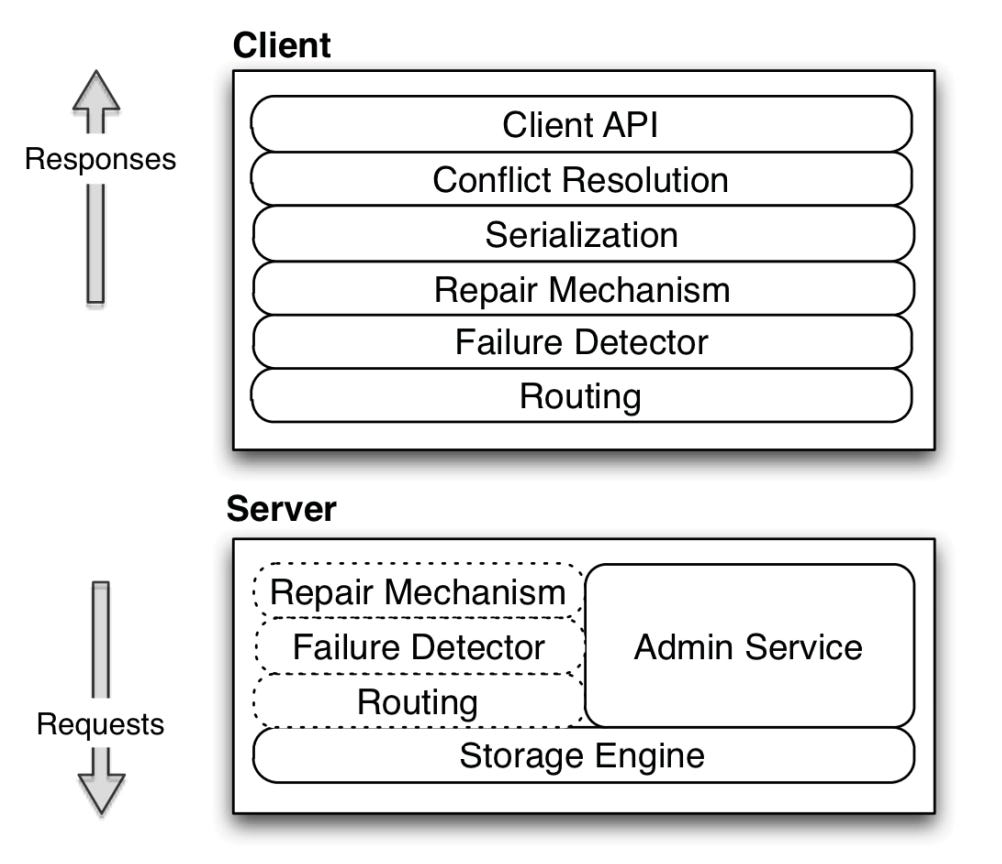
The architecture has the following blocks:
Client API and Conflict Resolution: Voldemort differs from other master-slave replicated systems in that any replica of a given partition can accept a write. LinkedIn used vector clocks to version the tuples and let the application resolve the conflict of concurrent versions.
If you are interested in the vector clock, you can find all the details of it from Dr. Martin Kleppmann’s video lecture.
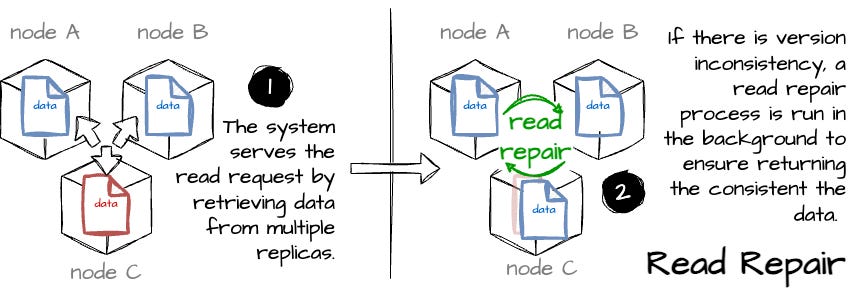
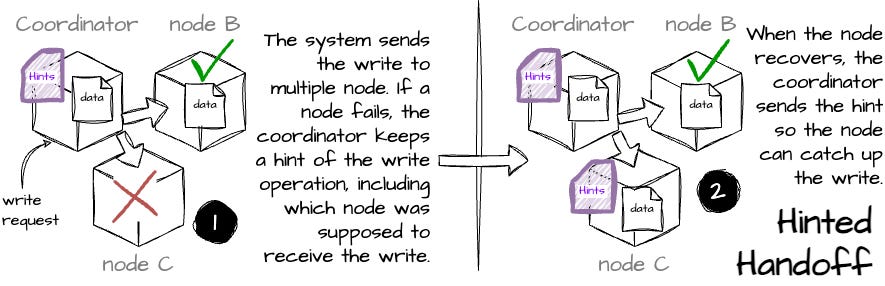
Repair mechanism: Voldemort reconciles inconsistent key versions using two mechanisms from the Dynamo paper: read repair and hinted handoff. Read repair detects inconsistencies during reading and hinted handoff is triggered during writing.
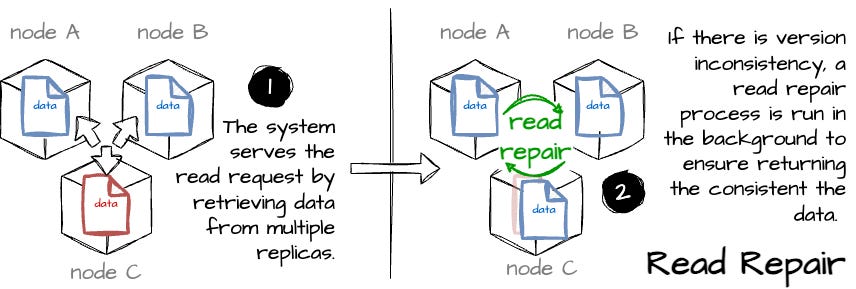
Image created by the author. 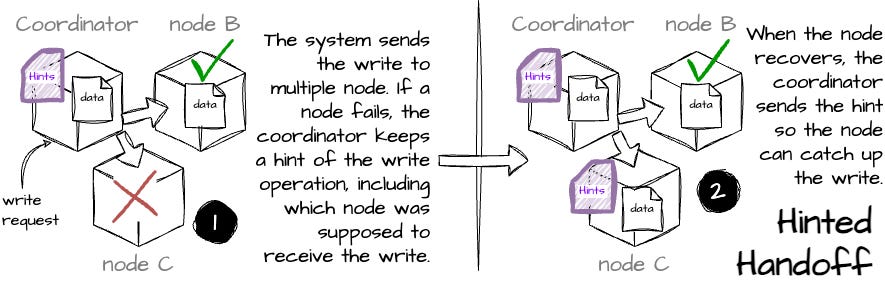
Image created by the author. Failure Detector: Voldemort uses various failure detectors, the most common of which marks a node as down when its success ratio (successful operations/total) drops below a specified threshold.
Routing: This module employs a simple implementation of consistent hashing to replicate data over the node.
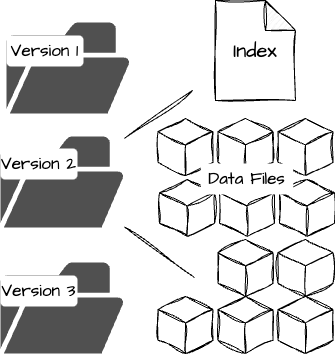
Storage Engine: The most common engines for Voldemort are BerkeleyDB Java Edition for read-write traffic and a custom read-only storage engine for static offline data. The latter was built for applications running multi-stage algorithms using systems like Hadoop. The data layout on Voldemort’s node consists of a compact index and data files within versioned directories per store. Every data deployment will result in a new directory, allowing instant rollbacks if problems occur.
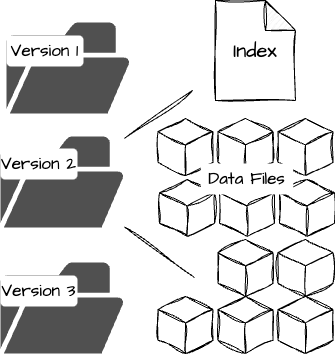
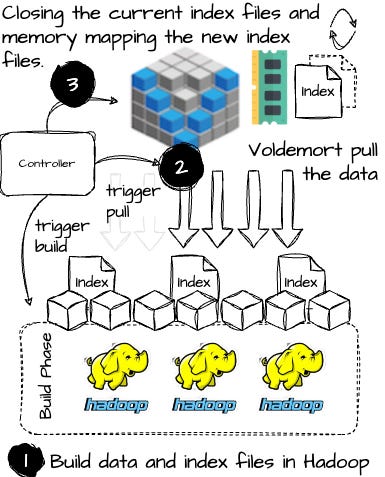
Image created by the author. A controller coordinates the complete data pipeline to get static data into Voldemort. The detailed flow of this pipeline is delivered via the figure below.
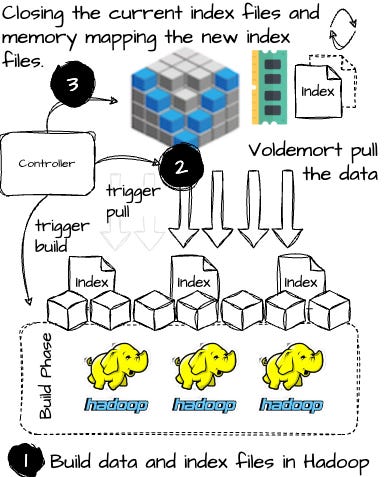
Image created by the author. Admin Service: Each node runs an administrative service for executing privileged commands, including adding/deleting stores and rebalancing the cluster by changing partition ownership (from one to a different node). The system keeps consistency during rebalancing by redirecting requests to the partitions’ new destinations.
Usage at LinkedIn
LinkedIn has ten Voldemort clusters: nine handle read-write traffic, and one handle read-only traffic with a custom engine. The largest read-write cluster, serving 60% reads and 40% writes, processes around 10K queries per second with an average latency of 3 ms. The read-only cluster handles 9K reads per second with less than 1 ms latency. Data sizes range from 8 KB to 2.8 TB for read-only stores and up to 1.4 TB for read-write stores.
The following section will discuss Databus, the CDC solution at LinkedIn.
To celebrate the launch of learn-spark for paid subscribers, the CLI tool that helps you learn Spark faster and more affordably right on your laptop. I’m offering you a 50% discount on the annual plan—grab it now to get access to the learn-spark tool!
After becoming a paid subscriber, visit this link to get invited to the learn-spark repo.
The offer ends VERY SOON!
Databus
Overview
LinkedIn developed Databus, a change data capture (CDC) system to provide a standard for delivering CDC events from LinkedIn primary databases to various applications, such as the Social Graph Index, the People Search Index, or processors like the Company Name and Position Standardization.
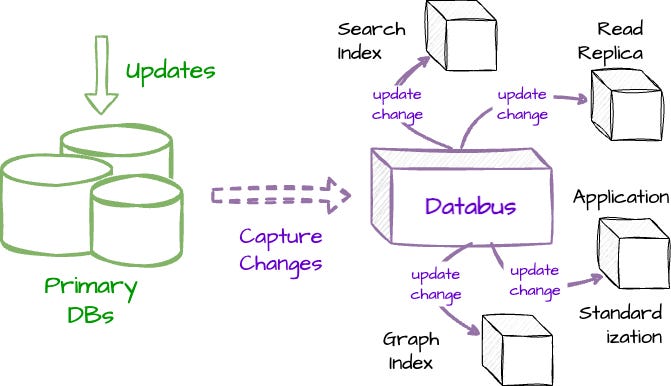
For the source, Databus has adapters for Oracle and MySQL, LinkedIn's primary databases. It also enables users to extend support for other data sources. For the sink, it has a subscription API that allows applications to subscribe to event changes from data sources.
Architecture
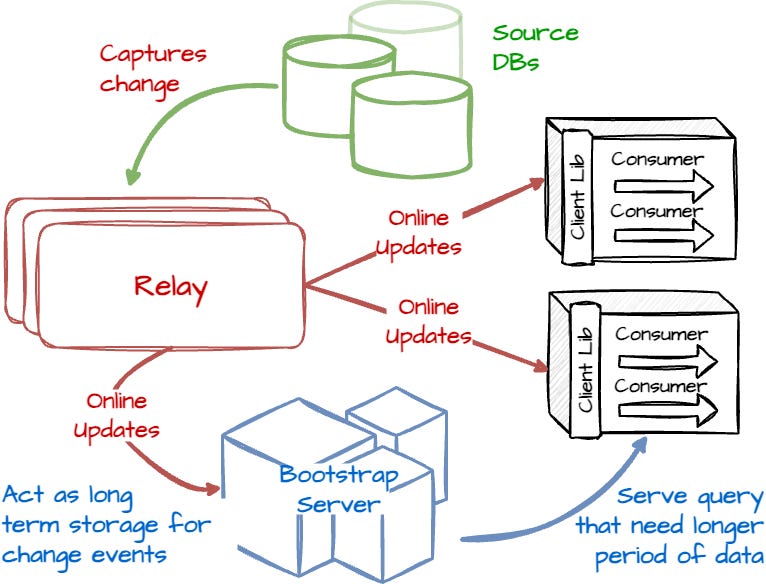
The Databus pipeline has three main components: the relay, the bootstrap server, and the Client Library.
The relay captures changes from the source database, serializes them into a binary format, and buffers them. Each change is represented by a Databus CDC event, which includes a sequence number, metadata, and serialized change payload. Relays serve these events to clients and bootstrap servers. The bootstrap servers handle long look-back queries in the Databus event stream, which relieves the source database from managing these queries.
Next, we will discuss the relay component in more detail.
As mentioned earlier, the relay's primary responsibility is capturing changes from the source database. There are two capture strategies: triggers or consuming from the database replication log. Changes after capturing are serialized to a binary format; LinkedIn chose Avro for this purpose.
Serialized events are stored in an in-memory buffer to serve the clients. LinkedIn deploys multiple shared-nothing relays directly connected to databases or other relays, ensuring replicated availability of the change stream.
The bootstrap server’s primary task is to provide long-term storage for the Database events stream. It serves all client requests that the relay cannot process because of its memory limitation. There are two types of queries that the server supports:
Consolidated delta since a position.
Consistent snapshot at a position.
The first case is when the clients must catch up in the event timeline. They can retrieve a consolidated delta from the bootstrap server. This approach returns only the latest update to each row/key, enabling quicker client catch-up with the relay's event stream.
For the second case, if the clients don’t have any consumed state, the bootstrap server provides a recent consistent snapshot of the database and a sequence number indicating the last transaction applied in that snapshot. Clients can use this number to continue consuming from the relay.
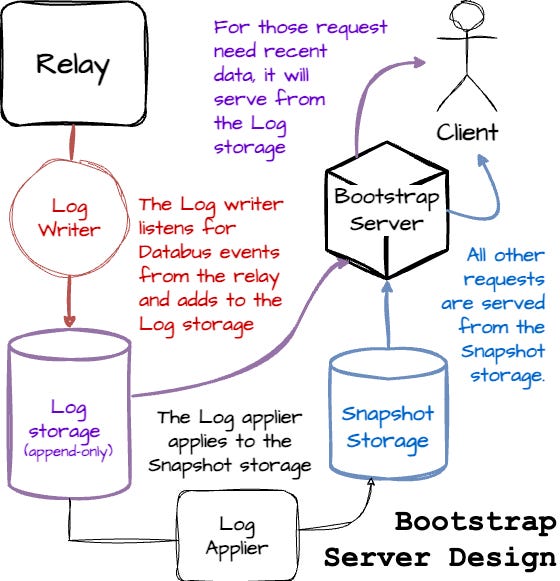
To provide consistent results for the above cases without affecting the relay events, LinekdIn uses two separate storages: the log and the snapshot storage. The log writer captures Databus events from the relay and appends them to an append-only log. The log applier monitors new entries in that log and applies them to snapshot storage, which stores only the latest event for each row/key. The server optimizes response paths: recent requests are served directly from the log storage, and other requests are served from Snapshot storage.
The final component is the client library. It connects relays, bootstrap servers, and consumer business logic. The client offers:
Progress tracking in the event stream.
Push or pull interface options.
Local buffering and flow control for uninterrupted event streams.
Multi-thread processing support.
Retry logic for handling failures.
Usage at LinkedIn
Databus began as a way to keep LinkedIn’s social graph and search index consistent and up-to-date with database changes. Over time, it evolved into a standard replication system for read replicas, cache consistency, and near-line processing. Regarding operational scale, Databus provides change capture for nearly a hundred data sources using tens of relays at very low latencies.
The following sections will describe Expresso, a LinkedIn document store.
Espresso
Overview
Espresso is a distributed, scalable, and timeline-consistent document store developed internally at LinkedIn. It was first deployed in 2011 to serve read traffic for features like company profiles, products, and reviews. The store supports secondary indexing and transactions (both are supported locally).
Data Model and API
A database in Espresso contains tables; each table consists of documents that are identified by URIs:
http://<host>:<port>/<database>/<table>/<resource_id>/[<subresource_id>]
A resource specified by a resource_id can reference either an individual document or a collection resource, which is a set of related documents; each is defined by a subresource_id.
Each database, table, and document has a schema represented in the format specified by Avro. The schema defines the partition scheme, which can be hash-based partitioning or unpartitioning (all documents stored on all nodes).
The document schema defines the structure of the documents in a table. Users can update the schema by issuing a POST request for a new version of the schema URI. New schemas must be compatible with Avro schema resolution rules to ensure that existing documents can be updated. Each document is stored in a binary serialized form along with the schema version required for deserialization.
Fields in the document schema can be decorated with indexing constraints, implying that documents must indexed for retrieval via the field’s value. Espresso allows the retrieval of documents using these secondary indexes via HTTP query parameters.
Espresso can update tables in a database with the same resource_id schema transactionally. It ensures that all tables indexed by the same resource_id path element are partitioned identically, enabling transactional updates.
Architecture
Espresso has four components: routers, storage nodes, relays, and cluster managers.
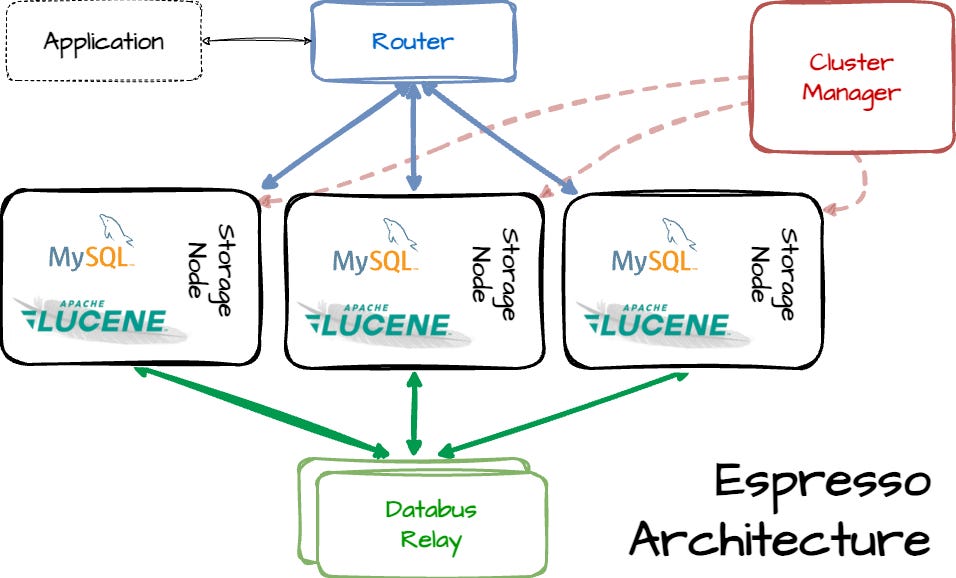
The first one is the router. It handles HTTP requests by inspecting resource URIs and directing them to the correct storage node. For a given request, it checks the database element in the path, retrieves the routing function from the database schema, and applies it to resource_id in the URI to compute a partition ID. Then, it references the routing table maintained by the cluster manager to identify the master storage node for the partition and finally forwards the HTTP request to the selected node.
The second component is the storage node. A request for a document will be routed to the partition master node. The node maintains a consistent view of each document in a local datastore. It can optionally index each document in a local secondary index according to the constraints defined in the document schema. LinkedIn initially implemented MySQL as the local data store and Lucene as the local secondary index. Each document is stored physically as a serialized byte stream indexed by the resource_id and any subresource_id.
Espresso partition tables are set according to the URL's resource_id component. The replication factor can be specified in the database’s schema. Each storage node acts as a master or slave.
The next component is the relay. It is in charge of Espresso replication. It ensures the following characteristics:
Timeline consistency: Changes are applied to a slave partition in the same order as on its master partition. The process involves three steps: (1) Changes on a storage node are tagged with their transaction sequence number and recorded in the MySQL binlog. (2) The system transfers MySQL binlog to a Databus relay node via MySQL Replication. (3) Other storage nodes pull changes from the Databus relay and apply them to the local partitions.
Efficiency: Replication minimizes resource usage on storage nodes to avoid impacting query performance by (1) Maintaining a single replication log on each storage node and (2) Offloading work to Databus relay nodes. Each storage node runs one MySQL instance, logging all master partition changes in a single MySQL binlog. Each slave partition subscribes only to its master partition's changes, which requires binlog sharding. MySQL replication publishes the binlog to the Databus relay, which is sharded into separate event buffers per partition. Slave partitions then consume events from their corresponding Databus buffer.
Robustness: Transaction changes are durable even under failures. Espresso writes changes in two places before committing: the local MySQL binlog and the Databus relay. If the first place fails, Espresso can still find the change in the Databus.
Espresso ensures fault tolerance and elasticity through replication. If a master partition fails, a slave partition takes over by first consuming all outstanding changes from the Databus relay before becoming the new master. When new nodes are added to an Espresso cluster, they handle specific master and slave partitions. The new partition is bootstrapped from a snapshot of the original master and then updated with changes from the Databus relay since the snapshot. Once up-to-date, the new partition operates as a slave.
The final one is the cluster manager. Espresso uses Helix to manage the cluster. It ensures:
Robust hosted services: Offering control flow for fault tolerance and optimized rebalancing during cluster scaling.
Load balancing: Allocating resources to nodes based on their capacity and resource profile (e.g., partition size).
Service discovery: Centralizing cluster configuration and providing automatic service discovery to route requests.
Server lifecycle management: Managing the entire operational lifecycle of a server without downtime.
Health check: Monitoring and altering
The following section discusses the Kafka, the message system at LinkedIn
Kafka
Many LinkedIn applications require online data consumption. Their engineer developed Kafka, a system that collects and delivers data internally; it was later open-sourced in 2011.
Terminology
The Kafka unit data is a message that contains a payload of bytes and is serialized to be sent over the network. Messages are organized into topics, which are divided into partitions. The clients who write the message on the topic are called producers, and those who read the message by subscribing to the topic are called consumers. Kafka stores messages physically at servers called brokers.
Architecture
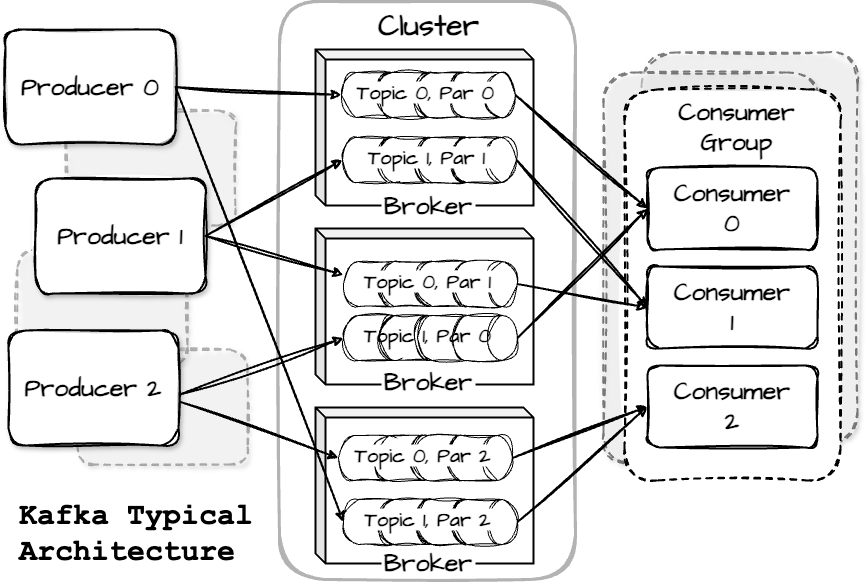
Kafka’s brokers work together as a cluster. A topic is divided into multiple partitions for load balancing, and each broker stores one or more partitions. Various producers and consumers can publish and retrieve messages.
Under the hood
Each topic’s partition corresponds to a logical log. Kafka implements a set of same-size segment files for the log. When a producer publishes a message to a partition, the broker appends the message to the last segment file. Kafka leverages the OS page cache for segment files read/write.
Consumers always consume messages sequentially. Initially, the consumer makes an async pull request to the broker with the offset at which they want to start consumption. The broker will search via the index file (mapping to the memory for faster lookup) to locate the segment file where the message resides. Then, the broker returns this message to the consumer. To prepare for the subsequent request, the consumer adds the length of the current message to its offset to calculate the next message offset.
For the agreement upon message consumption, consumers tell the broker that they have already consumed the message at a specific position, and the broker will imply that all messages before that position are consumed.
One thing worth mentioning about Kafka is that it doesn’t cache data in memory. Instead, it stores data in the filesystem and leverages the OS page cache. Thus, sequential access patterns are crucial in guaranteeing the system's performance. Using the OS page cache also lets Kafka leverage the zero-copy mechanism, which reduces the number of data copies when transferring messages between machines.
Speaking of Kafka, I’ve just finished the Kafka series article, in which I noted things when researching the message system. You can find them here: vutr.substack.com/t/kafka
Outro
Thank you for reading this far. I’ve just shared some insights from the Data Infrastructure at LinkedIn paper.
If you found this article valuable, please stop by, give me a reaction, leave a comment, or share so more people can read it. It will motivate me a lot.
Now, see you next time ;)
Reference
[1] LinkedIn, Data Infrastructure at LinkedIn (2012)
Before you leave
Leave a comment or contact me via LinkedIn or Email if you:
Are interested in this article and want to discuss it further.
Would you like to correct any mistakes in this article or provide feedback?
This includes writing mistakes like grammar and vocabulary. I happily admit that I'm not so proficient in English :D
It might take you five minutes to read, but it took me more than five days to prepare, so it would greatly motivate me if you considered subscribing to receive my writing.
Great post.
(Likedin -> Linkedin)