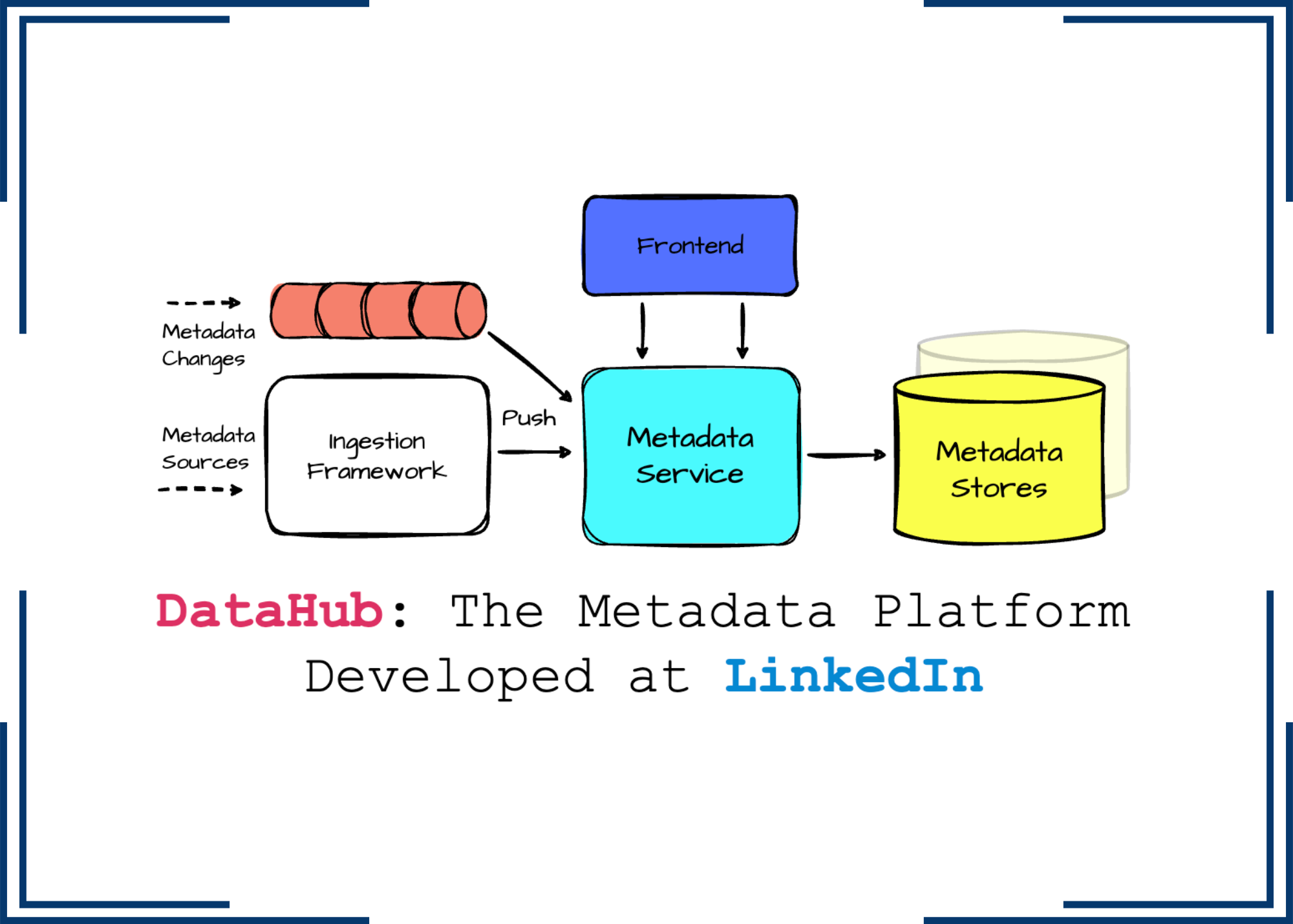
DataHub: The Metadata Platform Developed at LinkedIn
How did LinkedIn manage the data catalog at scale?

My name is Vu Trinh, and I am a data engineer.
I’m trying to make my life less dull by spending time learning and researching “how it works“ in the data engineering field.
Here is a place where I share everything I’ve learned.
Not subscribe yet? Here you go: