
Data architecture 101
What are Data Warehouse, Data Lake, Data Lakehouse, Data Fabric, and Data Mesh? Is Medallion a data architecture? How does data modeling fit into the picture?

I invite you to join my paid membership list to read this writing and 150+ high-quality data engineering articles:
If that price isn’t affordable for you, check this 30% ANNUAL DISCOUNT
If you’re a student with an education email, use this 50% ANNUAL DISCOUNT
You can also claim this post for free (one post only).
Intro
In this week’s article, I note my understanding of the data architecture, what it is, and its purpose, drawing on my humble experience, observations, and learning. Then we will visit terms, such as the warehouse, the lake, the lakehouse, or the data mesh.
The article also includes my clarifications on other questions, such as “Is Medallion a data architecture?” “How does data modeling fit into the picture?”, or “How about the Modern Data Stack?“
Note: this article is purely my train of thought; if you see anything off, I welcome any feedback.
What is data architecture?
Like software architecture, there isn’t a single agreed-upon definition of data architecture. In the scope of this article, I will refer to the definition from Joe Reis and Matt Housley in the book Fundamentals of Data Engineering:
Data architecture is the design of systems to support the evolving data needs of an enterprise, achieved by flexible and reversible decisions reached through a careful evaluation of trade-offs.
It’s the blueprint for any operations that provide insights from raw data within the organization, from data ingestion, storage, transformation, management, and serving. More importantly, as the author emphasized, the data architecture must be flexible and agile to support the rapidly growing demand from business users.
There are two main approaches to data architecture: centralized and decentralized.
Centralized architecture
In a company, data hardly comes from a single source. That might be the case at first, but over time, your company will have more services/applications and integrate with more external tools, each generating its own data. Business users are always hungry for data insights; more data generated means they see more opportunities to observe, learn, and optimize the business with the data.
In the centralized approach, data is consolidated in a single “place“. This “place“ is the source of truth for data ingestion, storage, processing, and serving. A centralized team mainly handles data management.
Bill Inmon called this place the data warehouse.
In the following sections, we will discuss the implementations of the data warehouse concept.
Relational Data Warehouse
In the past, the data warehouse was mostly implemented using transactional databases, which were not designed for analytical workloads.
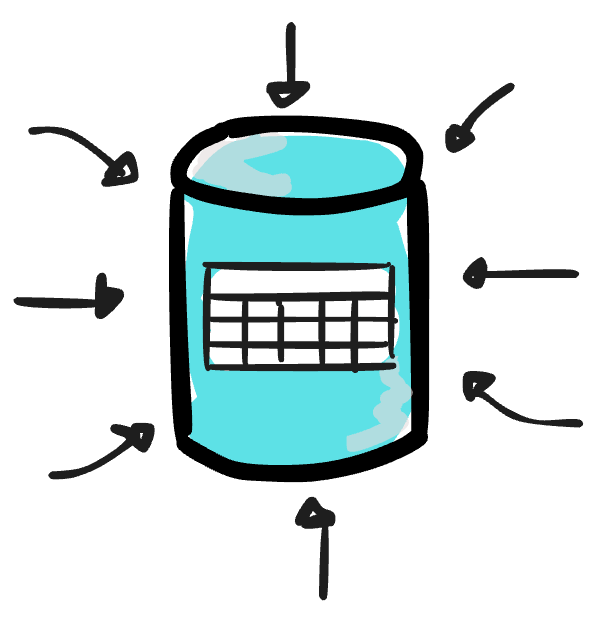
In the 2000s and 2010s, OLAP databases bloomed.
The ability to process large amounts of data through scanning and aggregation, plus the pay-as-you-go pricing models of cloud solutions, has made implementing the data warehouse more performant and cost-effective.
The relational data warehouse implementation usually has a bad reputation for accepting only structured data, which is the main motivation for the data lake implementation (covered next).
However, most of the data warehouse solutions these days have richer support for semi-structured data (e.g., JSON data) or even unstructured data (e.g., Snowflake and BigQuery now support storing and retrieving unstructured data such as text, image, or audio)
Data Lake
The data lake is a concept that describes the process of storing vast amounts of data in its native format (in HDFS or later in cloud object storage). Unlike relational data warehouses, the data lake doesn’t require a schema definition in advance, so that all data can be stored in the lake without concern for its format.
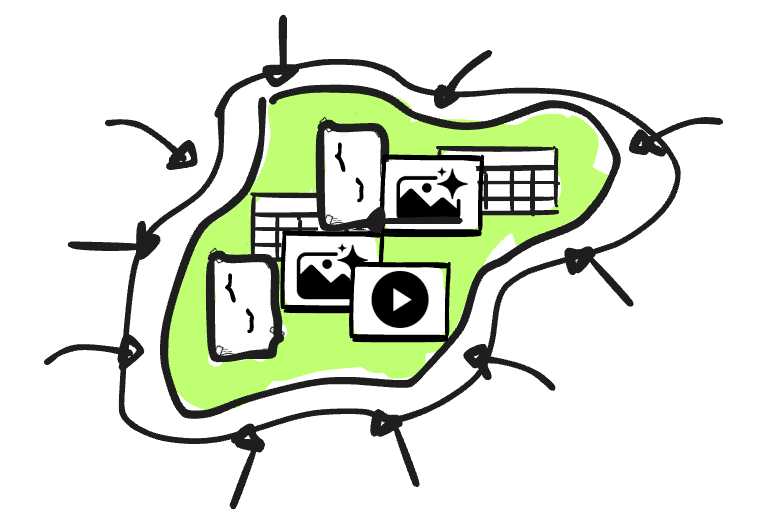
At first, people tried to replace the traditional data warehouse with a data lake by bringing processing directly on top of the lake.However, the approach had many serious drawbacks; the data lake soon became a data swamp due to a lack of proper data management features in the warehouse, such as data discovery, data quality and integrity guarantees, ACID constraints, and data DML support…
Thus, they combined the data lake and the data warehouse.
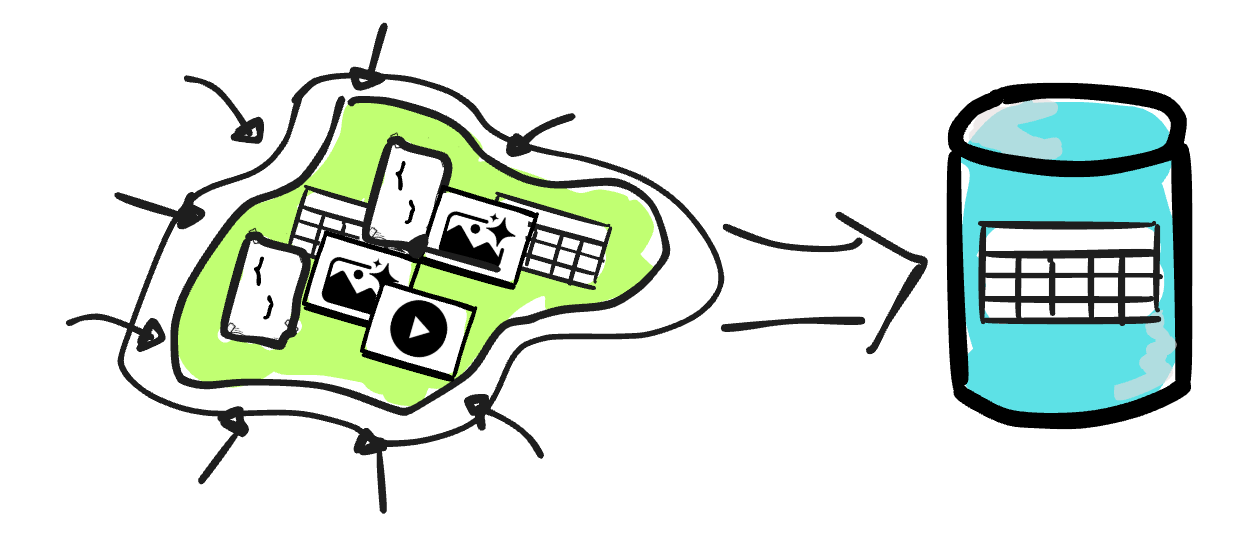
That is why, from the mid-2000s to the 2020s, the implementation that uses the data lake for raw data ingestion and the data warehouse for a subset of transformed data is the most widely recommended approach for building a data warehouse.
Data Lakehouse
I invite you to join my paid membership list to read this writing and 150+ high-quality data engineering articles:
If that price isn’t affordable for you, check this 30% ANNUAL DISCOUNT
If you’re a student with an education email, use this 50% ANNUAL DISCOUNT
You can also claim this post for free (one post only).
