


Bauplan: Operate your lakehouse with zero infrastructure
FaaS data pipelines on S3

I’m making my life less dull by spending time learning and researching “how it works“ in the data engineering field.
Here is a place where I share everything I’ve learned. Not subscribe yet? Here you go:

Intro
AWS Lambda is a fascinating service.
I first used it in 2021, and the experience was seamless. I wrote some code and configured how it should be triggered, and that was it.
Whenever a new file arrived in S3, my Lambda function would wake up, execute some logic, and then go back to sleep. I didn’t have to worry anything about the infrastructure.
That made me wonder: could I achieve the same simplicity with my data pipelines?
What if there was no need to set up an Airflow environment or provision a Spark cluster? What if I could define the pipeline logic—similar to an AWS Lambda function—and somehow, the input data would transform into the desired output?
This week, we’re diving into Bauplan, a solution that makes that wish come true.
Overview
Function-as-a-Service (FaaS) is a cloud computing model that allows developers to run code in response to events without managing the infrastructure. It enables a serverless approach, where the cloud provider handles provisioning, scaling for bursty workloads, and execution, allowing engineers to focus on writing logic. A well-known example is AWS Lambda.

FaaS makes it simple for the developer.
Bauplan, a team from New York and San Francisco, believes that the FaaS model can also simplify work for data engineers, analysts, data scientists, or anyone who wants to work with data.

Still, the solutions available on the market cannot adapt to the data workload. We usually define a data pipeline as a Directed Acyclic Graph (DAG), in which each node is a function that receives data from previous nodes, applies logic, and outputs results for the following nodes.
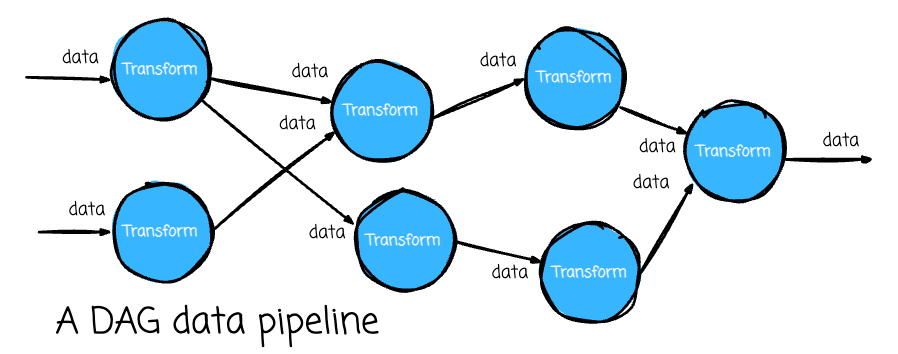
Modularizing the business logic into nodes makes developing, collaborating, and testing more convenient. But when implementing the DAG data pipeline using available FaaS solutions, some challenges emerge:
Scaling: Existing FaaS runtimes are designed for simple, independent functions that produce small outputs (e.g., a webhook). They have limitations when applied to data pipelines. Additionally, these FaaS platforms usually reuse instances for subsequent triggers. It can use the same function instance for 10 GB and 1TB of input with the same data function. “Out of memory” errors are common.

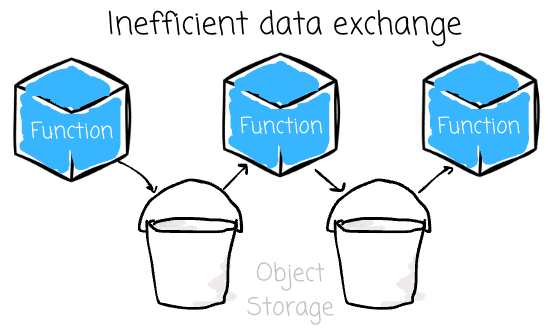
Image created by the author. Large intermediate I/O: To implement the DAG concept, users must chain functions. A function acts as a “node“ that receives input from previous functions and produces output for the following functions. Data functions typically have large inputs and outputs, which increases the cost of serializing and moving the data payload between functions. Popular FaaS platforms' chaining best practices are limiting because intermediate data frames can only be transferred through object storage.
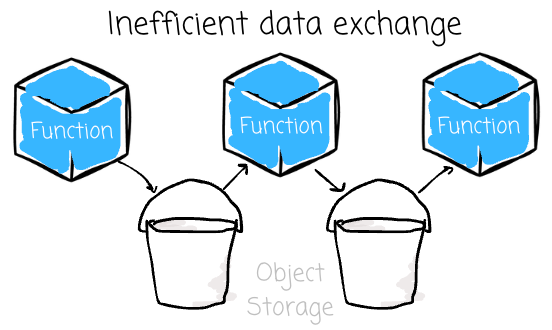
Image created by the author. Slow feedback loop: Data science projects are exploratory and require rapid iteration to validate hypotheses. Current FaaS platforms lack the interactivity needed for these projects due to their slow build times and lack of interactive logging. AWS Lambda provides only observability through Cloudwatch.

Image created by the author.


So, how does Bauplan promise to solve these problems?
The Bauplan FaaS
Bauplan is a FaaS service designed for data pipelines. Unlike other services, Bauplan initiates and scales independent instances for every run. It also promises to boost the intermediate data exchange process and allow users to modify and run DAGs interactively.
For the design principles:

Bauplan aims to make an execution stateless, and its instances only live during that run. Starting with new instances each time enables Bauplan to adapt to different resource requirements; the same pipeline can run with a 10GB dataset and later scale up to a 100 GB dataset.
For the infrastructure, the Bauplan pipeline will run on the cloud Virtual Machines (VMs), which offer the highest level of customization. Using cloud VMs also allows Bauplan to offer multiple deployment models, such as BYOC, where customers can control where data is stored and processed.
Bauplan is different from other tools because Bauplan has both data and runtime awareness (i.e., serverless runtimes like AWS Lambda don’t know about the data, and orchestration tools don’t know about the runtime). We’ll explore this design more deeply when we run some code later.
Bauplan brings an interactive experience to the developer; although the pipeline runs on the cloud, users can develop as it runs on their laptops. Bauplan provides a CLI tool and Python SDK for users to interact with the system.
Users define a function in Bauplan by specifying tables as input and output.
Architecture
Bauplan has a Control Plane (CP) and a Data Plane (DP):

The CP exposes multi-tenant APIs. It only deals with metadata. The CP lives in Bauplan’s VPC.
Each customer has a DP, a fleet of one or more cloud VMs that can be deployed in the customer VPCs. A Golang binary is installed in each VM to spawn the worker. These workers are the only Bauplan components that can access customer data.
To enable the developer to have an interactive experience, there is a bidirectional gRPC connection between customers and workers. Users write some print or logging statements to understand what happens during the pipeline run; although the code is run inside cloud VMs, the results are immediately visible to users thanks to the bidirectional connection.
Planning
So, the CP needs to deal with metadata, but what is its responsibility?
Bauplan acts like a database; it translates Python and SQL code into an execution plan when it begins running the pipeline. When the user requests a run, the code is routed to the control plane (CP). The CP will parse the code and reconstruct the DAG topology from the functions, resulting in a logical plan.
This plan only represents the dependencies between steps and the required packages as specified by the user. Importantly, Bauplan will refuse to run DAGs that refer to non-existing tables (unlike dbt, for example), point to wrong snapshots, or ship Python code with invalid formatting.

To give running instructions to the worker, the CP forms the physical plan from the logical one. This physical plan contains instructions for the containerized runtime of the transformation functions and mapping dataframes to a physical table in object storage. When having the physical plan, the CP sends it to workers to start the execution.
Data in Bauplan are store in Iceberg table in object storage, we will explore the storage layer soon.
The cache
As mentioned, function instances only exist during execution time. The two runs of the data pipeline will have different sets of instances. To reduce the latency when re-running the pipeline, Bauplan developed a robust package caching mechanism that avoids re-installing packages across runs, thus avoiding the overhead calls to PyPI.
For data caching, Bauplan’s data awareness makes database-like optimizations possible:
Re-using intermediate data: Functions produce intermediate dataframes, and Bauplan tracks the change in code and data to cache and reuse intermediate data.
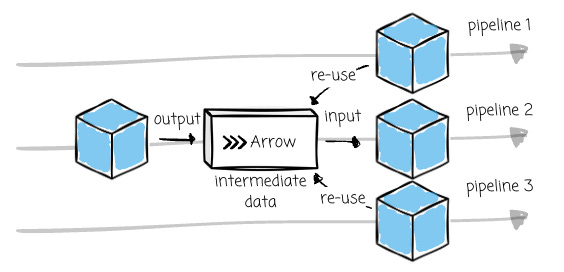
Image created by the author. Retrieving only missing columns: The first run reads four columns from the table, and the second run requires exactly these four columns plus column X. Bauplan will reuse the four columns from the cache and only download one additional column X from the data source.

Image created by the author. Cache invalidation: Because the physical data are stored in immutable files (via the Iceberg metadata), dataframe changes are identified with data commits such that the cache knows when data needs an update.
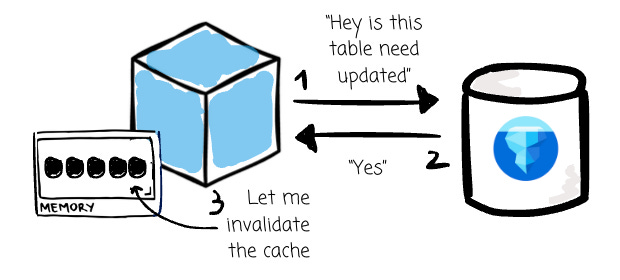
Image created by the author.



The data exchange
To enhance the data exchange process between functions, Bauplan represents intermediate dataframes as Arrow tables. From the official document:
The Arrow columnar format includes a language-agnostic in-memory data structure specification, metadata serialization, and a protocol for serialization and generic data transport.
Unlike file formats like Parquet or CSV, which specify how data is organized on disk, Arrow focuses on how data is organized in memory.

Arrow store values for each column contiguously in memory. This design is highly advantageous for data analytics workloads, which focus on a subset of columns when dealing with large datasets.

Before Arrow, each system used its internal memory format. When two systems communicate, each converts its data into a standard format before transferring it, incurring serialization and deserialization costs. Apache Arrow aims to provide a highly efficient format for processing within a single system. As more systems adopt it, they can share data at a very low cost, potentially even through shared memory at zero cost.

When Bauplan executes the pipeline, it will pick the sharing mechanism: memory or local disk (functions in the same worker) or Arrow Flight (across workers). Because other solutions only support S3-backed data exchange, moving data between functions in Bauplan can be hundreds of times faster, thanks to Arrow.
With Arrow, functions can read tables from shared memory, memory-map, or stream them from gRPC (with Flight), which gives the function greater flexibility when dealing with multiple data sources with different data transfer mechanisms.
A memory-mapped file is a segment of virtual memory that has been assigned a direct byte-for-byte correlation with some portion of a file or file-like resource. The benefit of memory mapping a file is increasing I/O performance, especially when used on large files.
Moreover, if a downstream function runs on the same worker as the upstream function, it can read the Arrow intermediate data on the worker without copying the data. Given intermediate data with 10GBs and four functions needed to read it, it only takes 10Gbs physical RAM instead of 10x4=40Gbs.
The storage
Bauplan does not stop there; beyond the FaaS data pipeline, they also aim to provide a complete lakehouse solution by offering a storage layer with Iceberg and Project Nessie.
If you have some Parquet files in the object storage, Bauplan can help you transform them into an Iceberg table in a single line of code. The data stays in your VPC; it doesn’t need to move anywhere.
Netflix created Apache Iceberg to achieve better table correctness and faster query planning (than Hives). An Apache Iceberg table has three layers organized hierarchically:

The data layer stores the table’s actual data, including the data and deleted files.
Manifest files track the data files in the data layer.
A manifest list captures the snapshot of an Iceberg table at a specific moment.
Metadata files contain information about an Iceberg table at a specific time, such as the schema or the latest snapshot.
The catalog is where every Iceberg data operation begins. It provides the engine with the location of the current metadata pointer and tells you where to go first.
Like other table formats, Iceberg's ultimate goal is to bring data warehouse capabilities to the data lake; one important one is the ACID constraints.
The Iceberg only ensures atomic transactions at the table level. To bring the software development experience to the lakehouse, Bauplan uses Project Nessie for the Iceberg table catalog. It is an open-source versioned metadata catalog that enables cross-table transactions for Iceberg. Users can update multiple tables together and guarantee all changes occur atomically – an all-or-nothing commit across tables.

Bauplan makes it easier for users to seamlessly work with Nessie and Iceberg tables by providing CLI commands and Python SDKs. Users will feel just like they are working with a Git repository.
In the next section, we'll explore all the cool Bauplan features mentioned above, where we'll run some code.
This post was written in collaboration with the Bauplan team. The final wording and opinions are mine.
Run some code
We will run some Python code and CLI commands; I prepared a Git repo so you can follow along. Make sure you pull the repo locally and enter the bauplan_example folder.
First, we need to set up a Python virtual environment with the requirements.txt file from the repo. We will install bauplan, streamlit and duckdb packages.
Next, we need the Bauplan API key, which gives you access to the Bauplan sandbox environment. You can contact Bauplan here for the key.
bauplan config set api_key "your_bauplan_key"Then, we will run some bash scripts to set up; let’s make those scripts executable:
chmod -R +x scripts/Bauplan is designed to operate exclusively in the cloud to ensure a fully auditable and secure data development cycle. They require us to store data in object storage so it can support importing to the Iceberg table.
Currently, Bauplan only supports S3 as the data source and Parquet and CSV as file formats. We will run a script that creates an S3 bucket, uploads some CSV files, checks out to a branch, creates a namespace, and then imports these files to the Iceberg table in Bauplan Sandbox. But first, make sure you configure your AWS CLI:
aws configure # Entering AWS access key, secret and default regionThen, run the setup.sh with the S3 bucket name you want to create and the Bauplan branch. The branch must be in a pattern <your-user-name>.<something>
./scripts/setup.sh <bucket name> <bauplan branch>
Wait for a while, and then you will have five tables in your catalog. The script will create a namespace called adventure. A namespace in Bauplan is a logical container that helps organize tables within a data catalog. We will work on your input branch and the adventure namespace from this time. Let’s list out the input tables:
bauplan table --namespace adventureBefore we move on, let’s understand the input data. We will have five input tables from the AdventureWorks sample dataset: product, product_category, product_subcategory, sale, and territories.
AdventureWorks database supports standard online transaction processing scenarios for a fictitious bicycle manufacturer - Adventure Works Cycles.
The relationship of the tables is:

In this project, we will write a Bauplan pipeline to transform these input tables into a dimensional data model with a fact_sale, dim_product, and dim_country:

We implement the transformation pipeline using Bauplan models. A model function takes tabular data as input and produces tabular data. We will write a DAG to transform the data using the duckdb engine:
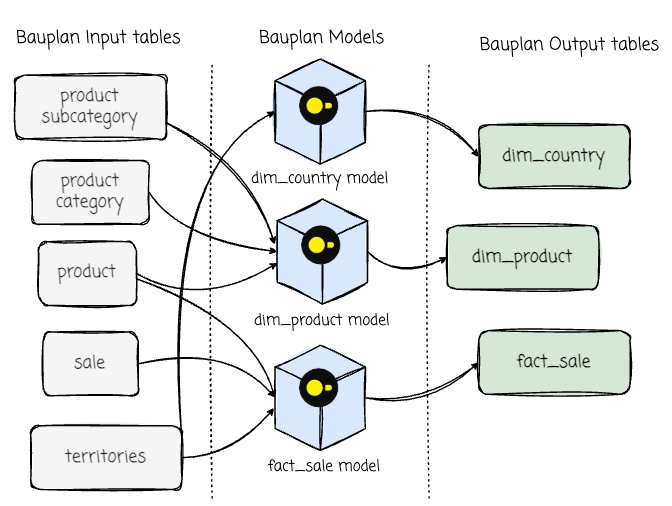
We define these models in the models.py file. A very important point is that the Bauplan model is aware of both data and runtime.
For runtime awareness, you can use Bauplan’s decorator to specify the runtime for each model, such as the Python version and packages, how to materialize the output, and allow for explicit column selection and filter pushdown.
For data awareness, each model must have inputs, which can be tables in the catalog or other models. We specify and use them like Python function parameters.
Here is the code of the dim_product model. As you can see, for this model, Bauplan knows that it must run the model with Python 3.11, duckdb 1.0.0 and the model has product, product_category, product_subcategory as input data.
You can check the codes for all the models here.

After having the models, we run the pipeline:
bauplan run --project-dir pipeline --namespace adventure We submit the code to Bauplan. It will plan and execute it. If there are any errors, it will display in real-time in the terminal for us thanks to the bidirectional gRPC connection between us and the Bauplan workers.
To run the pipeline, we need a bauplan_project.yml file containing the project’s unique ID and name. I located both the bauplan_project.yml and models.py files in the pipeline folder.
After the pipeline finishes, you can check the output tables by listing the namespace adventure again:
bauplan table --namespace adventureFinally, to have more fun with the project, I created a small Streamlit app with a world-class SQL editor (:D) to query the output table:
streamlit run streamlit/app.py Here is a quick demo video to showcase my world-class SQL editor:
To clean up, you can run the clean_up.sh to clean up the S3 bucket and Bauplan table automatically:
./scripts/clean_up.sh <bucket name> <bauplan branch>My thoughts
In a world where data is the new gold, every company wants the ability to capture, store, process, and serve data to drive business decisions. However, not every company has a dedicated data team. In many cases, you might be the team's first and only data person.
At the beginning of this article, I had a wish—and it came true. Bauplan handles tasks that would typically require an entire infrastructure team. Its goal is to provide a seamless, developer-friendly way to work with large-scale data directly in Python, eliminating infrastructure bottlenecks.
When running some code with Bauplan, I was truly impressed by how seamlessly it imports data files from object storage into Iceberg tables. Setting up an Iceberg catalog, configuring the Iceberg writer, and managing the physical layout is usually a painful process, but Bauplan simplifies it significantly.
Defining data transformations is also a pleasant experience, thanks to Bauplan’s concept of a “model.” I can run transformations with Python 3.9 or 3.10 simply by changing a few lines in a decorator. The model’s data-awareness makes it incredibly intuitive to write transformation logic—I can specify it as easily as defining function inputs in Python.
Bauplan is truly innovative. It’s well worth your time trying, especially if you’re a data engineer, data analyst, or data scientist—or if you simply love working with data.
Personally, I hope Bauplan will expand to support data processing runtimes like Spark or Trino. A serverless Spark or Trino cluster would be a game-changer. Additionally, a robust SQL editor for querying data in the catalog would be a valuable addition.
Outro
Thank you for reading this far.
In this article, we explore the challenges of implementing the data pipeline with available FaaS solutions, how Bauplan promises to solve them, Bauplan’s design goals and architecture, how Bauplan offers a complete zero-infrastructure lakehouse with the Iceberg + Project Nessie storage layer, and finally we write some code to build a Bauplan pipeline.
Now, it’s time to say goodbye. See you in my following articles.
Reference
[2] Jacopo Tagliabue, Tyler Caraza-Harter, Ciro Greco, Bauplan: zero-copy, scale-up FaaS for data pipelines (2024)
Thanks for sharing bro. Nice post.
Very well explained. Thanks for sharing :)