
AutoMQ: Achieving Auto Partition Reassignment In Kafka Without Cruise Control
AutoMQ’s stateless brokers and its self-balancing feature

My name is Vu Trinh, and I am a data engineer.
I’m trying to make my life less dull by spending time learning and researching “how it works“ in the data engineering field.
Here is a place where I share everything I’ve learned.
Not subscribe yet? Here you go:

I wrote this article with the help of Kaiming Wan, the Director of Solutions Architecture and Lead Evangelist at AutoMQ. For more information about AutoMQ, you can visit their website here.
Intro
If you’ve ever managed a Kafka deployment in your company, there’s a good chance you’ve done reorganizing partitions across clusters. Due to Kafka’s tightly coupled compute and storage setup, partition replicas must be redistributed across brokers when cluster membership changes (such as adding or removing brokers) or users want to load balances between brokers, leading to data movement.
Kafka provides a script for handling the reassignment process, but it requires user intervention and lacks robustness in planning. Tools like Cruise Control have stepped in, offering automatic replica balancing based on cluster state and a more sophisticated reassignment plan.
However, the data movement issue is still there.
This week, we’ll explore how AutoMQ addresses Kafka’s rebalancing challenge.
AutoMQ is a cloud-native solution offering 100% Kafka compatibility while storing data entirely on object storage. This approach provides a highly cost-efficient Kafka alternative without sacrificing low latency and high-throughput performance. More importantly, you will never need to transfer data between brokers.
Kakfa Partitions
Let’s first review the Kafka terminology.
Kafka’s data unit is a message. Messages in Kafka are organized into topics. You can think of messages as rows and topics as tables in the database system. A topic is split into multiple partitions.

Each partition of a topic corresponds to a logical log. Physically, a log is implemented as a set of segment files of approximately the same size (e.g., 1GB). Whenever a message is written to the partition, the broker appends that message to the last segment file.

To ensure data durability and availability, partitions are replicated to a configurable number of brokers (the replica factor).
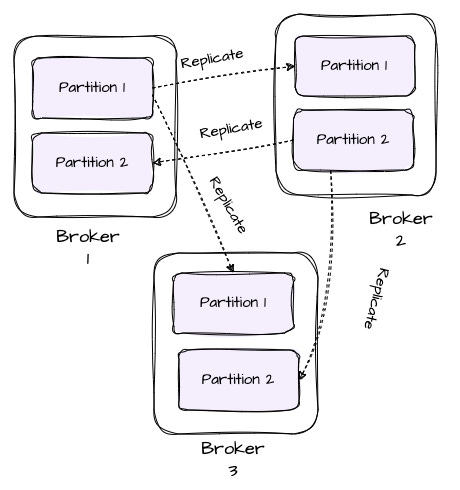
This helps automatically fail over the replicas when a broker fails, so messages remain available in the presence of failures. Each Kafka partition typically has a single leader and zero or more followers (those storing replicas). All writes must go to the partition’s leader and reads can be served by a leader or the partition's followers.
Kafka will distribute the partitions’ replicas in a cluster round-robin fashion to avoid placing all partitions for high-traffic topics on a few nodes.
Replica Reassignment In Kafka
Given that the replicas are distributed across the cluster, what happens when an existing broker dies or a new broker is added? Kafka replicas need to be reassigned. Imagine we have three brokers and two partitions, each with two replicas:

If a broker fails, Kafka will automatically reassign leadership of any partitions for which this partition was the leader to other brokers that hold replicas. Kafka may eventually create new replicas of these partitions on other available brokers to maintain the replication factor.

When a broker is added, the replicas are redistributed to ensure an even workload between brokers.

Besides changes in cluster membership, balancing the workload between brokers also requires partition replica reassignment. Balancing data between brokers helps prevent hot spots where some partitions might receive more traffic than others. Additionally, ensuring data is evenly distributed across brokers leads to optimal resource utilization.
Kafka's open-source version supports a tool to facilitate partition reassignment called kafka-reassign-partitions (bin/kafka-reassign-partitions.sh). The tool can run in 3 modes:
-generate: This mode is used to create the partition reassignment plan; given a list of topics and a list of brokers, the tool generates a candidate reassignment plan to move partitions of topics to the new brokers.-execute: In this mode, the tool executes the partition reassignment plan based on the user-provided one. This can either be a custom, manually created plan or provided by using the–-generateoption-verify: The tool verifies the status of the reassignment for all partitions listed during the last—-execute.
However, the user has done the reassignment process manually, which is error-prone and inefficient. Is there a way to automatically process this reassignment? Luckily, third-party tools have been developed for this purpose.
LinkedIn’s Cruise Control
Cruise Control is a tool that helps run Apache Kafka clusters at scale. Due to its popularity, many companies have ever-increasing Kafka clusters. At LinkedIn, operating ~7K+ Kafka brokers means balancing the workload of Kafka is challenging. Moreover, monitoring and detecting problems in large Kafka clusters is also crucial here.
Cruise Control provides the following features:
Resource utilization tracking
Current Kafka cluster state observability
Anomaly detection, alerting, and self-healing for the Kafka cluster
Admin operations such as broker add/remove or cluster rebalancing.
Multi-goal reassignment plan generation.
Cruise Control relies on recent replica load information to optimize the cluster. It periodically gathers resource utilization at both the broker and partition levels to capture each partition’s traffic pattern. Using these patterns, it determines each partition's load impact on the brokers. The tool then constructs a workload model to simulate the Kafka cluster’s performance. The goal optimizer explores various ways to generate optimization proposals for the cluster workload based on a user-defined list of goals.

This approach differs from kafka-reassign-partitions; while the Kafka native tool bases rebalancing solely on provided input, Cruise Control uses the workload model and offers a more robust set of goals for the rebalancing plan.
Although Cruise Control helps address the overhead of rebalancing operations, the need to move data between brokers across the network remains. As data transfers between brokers, the cluster must wait for a period to reach a balanced state. This also makes the balancing process with Cruise Control or other third-party tools potentially inaccurate at execution time; when the tool executes decisions, it only acts on the current snapshot of the cluster. Since data in Kafka needs to be replicated, decision execution is slow. The cluster state snapshot linked to this decision may change significantly by the time it’s executed, making the decision less accurate.
This issue persists in Kafka due to its design, which aims to keep storage and computing closely integrated.
AutoMQ: There is no need to move data around
When it comes to AutoMQ, things get easy here.
AutoMQ leverages Apache Kafka code to achieve 100% Kafka protocol while introducing the shared storage architecture to replace the Kafka broker’s local disk. Its goal is to make the system completely stateless.
While a Kafka broker writes messages directly to the OS page cache, an AutoMQ broker first writes messages to an off-heap memory cache, batching data before writing it to object storage. To ensure data durability if the broker fails to move data from memory to object storage, AutoMQ introduces a pluggable Write-Ahead Log (WAL) on disk. Brokers must confirm that the message is stored in the WAL before writing to S3. Upon receiving a message, the broker writes it to the memory cache and returns an acknowledgment only after persisting it in the WAL. AutoMQ utilizes data in the WAL for recovery if a broker failure occurs.
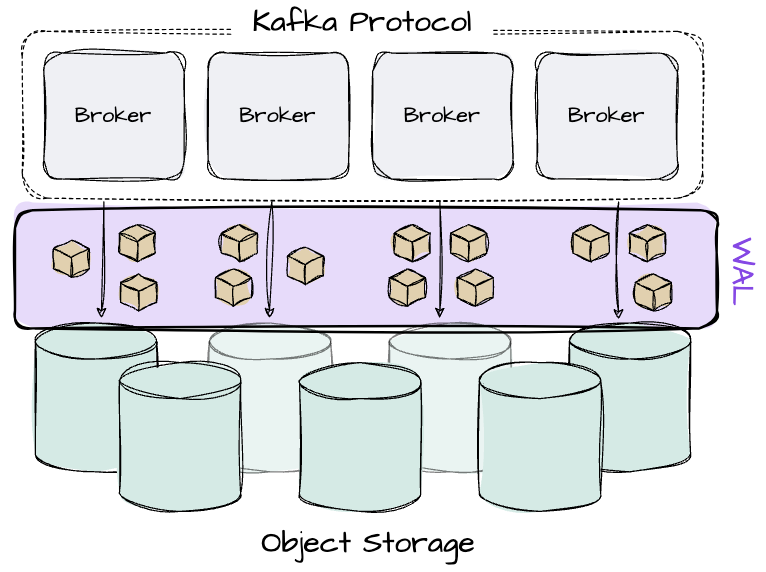
In this way, AutoMQ achieves complete compute-storage separation. The design of AutoMQ implies two essential facts:
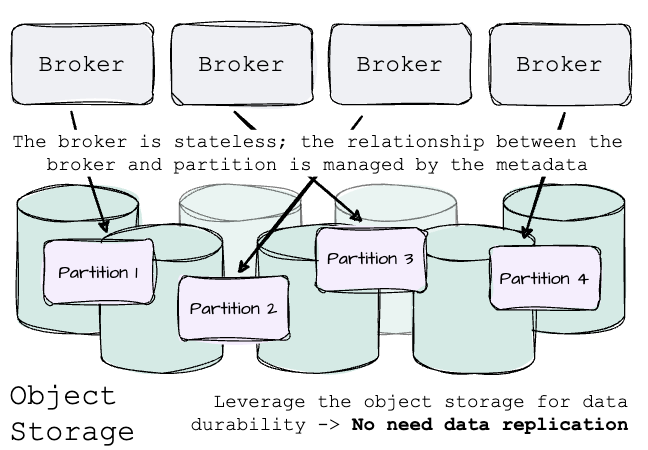
Because the object storage service guarantees data durability and availability, it is unnecessary to replicate data across brokers. Thus, every partition will have only one replica—the leader.
The broker is entirely stateless; the relationship between the broker and partition is only managed through the metadata instead of physically storing responsible partition data on the broker’s local disk.
Consequently, the rebalancing process becomes far more straightforward. Data does not need to be moved; AutoMQ only needs to adjust the metadata mapping between brokers and the partition. This allows decisions to be executed quickly, accurately, and effectively.
Speaking of metadata, AutoMQ leverages the metadata management architecture based on Kafka's Kraft mode. Initially, Kafka relied on separate ZooKeeper servers for cluster metadata management. With KRaft mode, Kafka uses an internal Raft-based controller quorum—a group of brokers responsible for maintaining and ensuring metadata consistency. Each broker in KRaft keeps a local copy of the metadata. At the same time, the controller quorum leader manages updates and replicates them to all brokers, reducing operational complexity and potential failure points.
AutoMQ stores the cluster metadata, such as the mapping between partitions and brokers, in the controller quorum leader. Only the leader can modify this metadata; if a broker wants to change it, it must communicate with the leader. The metadata is replicated to every broker; any change in the metadata is propagated to every broker by the controller.
AutoBalancer: The AutoMQ self-balancing feature
The Goals
A goal refers to a set of objectives or constraints that guide the optimization and balancing of the Kafka cluster. These goals define specific requirements, such as the distribution of load across brokers, resource utilization limits, partition replication, and latency targets.

Unlike Cruise Control, which provides predefined goals and allows users to write their own, AutoMQ's self-balancing feature, AutoBalancer, simplifies things by offering a set of robust, well-tested goals. Each goal in AutoMQ is defined with a threshold and an acceptable range. For example, if a goal involves balancing broker utilization with a CPU utilization threshold of 50% and a range of ±20%, the acceptable range spans from 30% to 70%. The goal is considered achieved as long as traffic stays within this range. AutoBalancer categorizes the goals into two types:
The detection type has goals like checking resource capacity violations (CPU or Network I/O).

The optimization type has goals like cluster traffic rebalancing. AutoMQ further categorizes the optimization goals into producer, consumer, and QPS (Query Per Second) balancing goals. Different types of balance goals address various metrics. For instance, the producer/consumer balance goal aims to ensure the producer/consumer traffic is balanced, or the QPS goal aims to balance the QPS between brokers.

To ensure the stability of the effect after the execution of the optimization goal, AutoMQ will carefully choose the threshold and range separately for the detection goal and optimization goal. For example, narrowing the range of the optimization goal can ensure more precise results after the optimization goal processing.
A specific goal might have a higher priority than others. AutoMQ classifies goals by priority as either hard or soft:
Hard Goal: These goals must be met under any circumstances, such as limiting the number of broker partitions or capping the upper limit of broker traffic.
Soft Goal: Soft goals can be disregarded if they conflict with hard goals. An example is a traffic-balancing goal.
For goal management, AutoMQ represents each goal with a mathematical model. Each model indicates whether a broker meets the goal based on specific mathematical conditions. In some cases, there may be multiple possible actions to achieve a goal (e.g., moving a partition from broker A to B or from broker A to C—both could help balance cluster traffic). AutoMQ also uses a mathematical system to determine the most optimal decision in specific circumstances. Each decision is scored based on goal-related parameters, and the decision with the highest score is executed.
Components
The implementation of the AutoBalancer mainly consists of the following three components:

Metrics Collector: Apache Kafka provides a metrics collection system based on YammerMetrics and KafkaMetrics. These metrics can be monitored via the MetricsRegistry and MetricsReporter interfaces. Based on these interfaces, AutoMQ has implemented the reporter to collect predefined metrics, such as network traffic throughput, periodically. AutoMQ uses an internal topic to transfer metrics between the broker and controller; after collecting the metrics, the reporter compiles them into multiple messages and sends them to the internal topic.
State Manager: On the controller, AutoMQ maintains a ClusterModel representing the cluster’s current state and partition loads. Changes to the cluster, such as broker additions, removals, or partition reassignments and deletions, are managed by monitoring KRaft metadata to update the ClusterModel. Meanwhile, the controller continuously consumes from the internal topic, preprocesses the extracted metrics, and updates the ClusterModel, ensuring it accurately reflects the cluster's current state.
Decision Scheduler: This component aims to help the cluster achieve a desired outcome, such as limiting the number of partitions per broker or capping traffic on a single broker. In AutoMQ, only the active controller is involved in decision-making and scheduling. Before beginning the decision-making process, AutoMQ takes a snapshot of the ClusterModel, using this snapshot state for subsequent scheduling. Once the snapshot is complete, the ClusterModel can continue to update. AutoMQ’s decision-making process uses a heuristic scheduling algorithm similar to Cruise Control.
Typical Process

Next, let's dive deep into the typical process of AutoMQ self-balancing:
The self-balancing scheduler process kicks off every interval (e.g., every 60 seconds) to check if the cluster meets all the goals. If yes, the scheduler goes back to sleep.
If not, the scheduler will get the list of brokers that violate the goal.
For each violated broker, the scheduler will form the partition reassignment plan to try to make the broker achieve the goal.
The scheduler then checks if the partition reassignment is feasible for the broker. If yes, the plan will be executed for this cluster. If not, this broker can not meet the goal, and the schedule will move on to check on the other brokers on the list.
Scenarios
Let's review the behaviors of AutoBalancer in different scenarios:
In the cloud context, “rack” can refer to an availability zone.
Topic creation: The AutoBalancer supports rack awareness for topic creation. It supports randomly distributing data across racks but considers the "weight" of each rack. Heavier-weighted racks will receive more data on average than lighter ones. Within a rack, data distribution among brokers will follow their individual weights. If one broker has a higher weight, it will receive a larger share of the data within that rack.
Adding brokers: AutoBalancer supports gradually warming up new brokers. Instead of sending all traffic to this new broker at once, the system will slowly direct traffic to it over time, avoiding overwhelming it. The AutoBalancer also tries to minimize cross-rack traffic during expansion to prevent network congestion unless a new rack is involved.
Removing Brokers: AutoBalancer support automatically migrates the partition responsible for the removed broker to another broker. It tries to migrate the partition to the broker in the same rack as the removed broker.
Unbalanced throughput: The system allocates traffic based on the broker’s ability to handle a specific rate of requests. Each physical broker has a "weight". This weight measures its capacity or capability to handle the load. For example, a more powerful broker might be assigned a higher weight. AutoMQ looks at factors like network, IO, or CPU cores to determine each broker’s weight. The system continuously monitors each node’s load and processing power to adjust scheduling to prevent overloading any single broker.
Single Node Failures: AutoBalancer support identifies slow brokers, which could signal potential problems. The system can then reduce the load on these slow brokers by transferring tasks to healthier nodes, allowing the slow nodes to recover without impacting system performance.
AutoBalancer vs Cruise Control
Before ending this article, let’s review some differences between AutoBalancer and Cruise Control:
AutoMQ natively supports the AutoBalancer capability, eliminating the need for complex operations and deployments. In contrast, Cruise Control requires independent deployment and management alongside the Kafka cluster.
Apache Kafka requires replicating large amounts of data when moving partitions to balance traffic, resulting in high execution costs. Consequently, Cruise Control’s balancing goals are designed to be strict and effective only in scenarios with minimal traffic fluctuations. For scenarios with significant load variations, Cruise Control struggles to remain effective. AutoMQ, with its compute-storage separation design, is better equipped to handle complex load scenarios.
Thanks to its design, AutoMQ allows AutoBalancer to execute replica reassignments more quickly than Cruise Control. Additionally, because AutoBalancer is an integral part of AutoMQ, it can directly consume the KRaft log, enabling it to react faster to cluster changes.
Outro
Thank you for reading this far.
In this article, we revisited some Kafka terminology, such as how partition replicas are distributed across brokers and why replicas need reassignment when cluster membership changes. We then explored Kafka’s native solution for the reassignment process.
Next, we examined how third-party tools like Cruise Control help users streamline the process more conveniently and robustly. We discovered that AutoMQ can fully resolve the data movement challenge during reassignment because data is stored outside the broker, allowing only metadata adjustments. Finally, we dive deep into the AutoBalancer, the AutoMQ self-balancing feature.
We’ve seen that while Cruise Control assists users with Kafka’s reassignment process, the core problem remains: data still needs to be transferred between brokers over the network. AutoMQ’s innovative architecture, which allows data to be stored entirely in object storage, makes many Kafka operations much more straightforward for users, especially during partition reassignment; only metadata needs adjustment when a partition is assigned to a different broker. This also makes its internal self-balancing more efficient and robust.
If you want to learn more about AutoMQ, I’ve written two detailed articles on this solution, which you can find here:


Now, it’s time to say goodbye. See you in my following writing.
References
[1] With the help of Kaiming Wan, Director of Solutions Architect & Lead Evangelist @ AutoMQ
[2] AutoMQ official documentation
[3] AutoMQ blog
[4] Confluent, Best Practices for Kafka Production
[5] Kafka Cruise Control Github Repo
Before you leave
If you want to discuss this further, please leave a comment or contact me via LinkedIn, Email, or Twitter.
It might take you five minutes to read, but it took me more than five days to prepare, so it would greatly motivate me if you considered subscribing to receive my writing.