

My name is Vu Trinh, and I am a data engineer.
I’m trying to make my life less dull by spending time learning and researching “how it works“ in the data engineering field.
Here is a place where I share everything I’ve learned.
Not subscribe yet? Here you go:

Intro
Do you remember feeling so immersed in something as a kid that you forgot about space and time?
For me, it was playing football (not American football) as a child.
Three months of summer vacation, seven days a week, every day at 4 PM, I’d head to my grandma’s house and play football with other kids until 6 PM. Bare feet, a plastic ball, and four bricks as goalposts — Literally forgetting space and time.
As I grew up, I rarely found myself immersed in anything the same way.
I thought that feeling had returned when I started learning about stream processing. I can’t explain why it felt similar, but maybe it was the excitement of imagining applying what I was learning, much like I imagined being my football idol as a kid.
However, that feeling soon faded. Perhaps it was because I didn’t have the opportunity to apply stream processing in my daily jobs, so my subconscious told me to shift my interest to other topics. (Maybe that is why Peter Pan never wants to grow up)
Today, as I sat down, scratching my head for a topic to write about, a thought popped into my mind:
‘Why not revisit stream processing?’
Overview
So, what’s the first tool that comes to mind when you think of real-time processing?
For me, it’s Apache Flink.
Straight from its homepage:
Apache Flink is a framework and distributed processing engine for stateful computations over unbounded and bounded data streams
The term unbound data describes data that doesn’t have a boundary, e.g., the user interaction events of an active e-commerce application; the data stream only stops when the application is down.
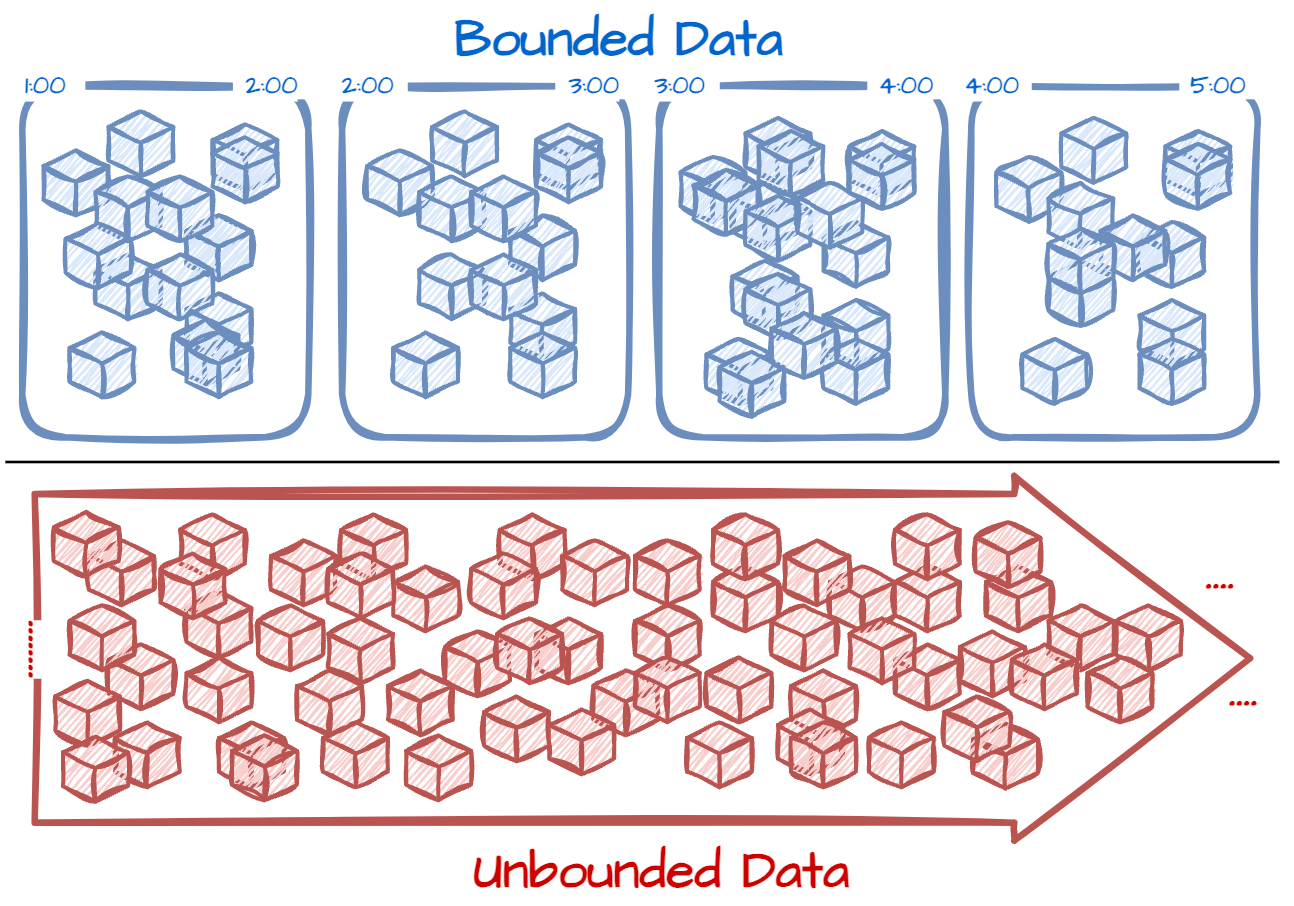
Bounded data can be defined by clear start and end boundaries, e.g., daily data export from the operational database.
Apache Spark can also be used for stream processing, but there is a big difference between it and Flink; it considers bounded data a first-class citizen and aligns stream data into micro-batches. For Flink, everything is a stream; the batch is just a special case.
If you have streams from Kafka, Google Cloud Pubsub, or Amazon Kinesis and want to consume them, apply logic to the data, and route them somewhere else, Apache Flink can help. You will start by defining a Flink application, including the processing logic, through a set of rich APIs and then deploy it on a cluster environment such as YARN or Kubernetes.
Architecture
A typical Flink setup includes four components, all of which are JVM processes:
The Dispatcher provides a REST interface for users to submit Flink applications. It also runs a dashboard to display information about job executions.
The JobManager is the master that controls the execution of a Flink application; a different JobManager controls each application.
Flink has different ResourceManagers for different resource providers, such as YARN or Kubernetes. This component's primary responsibility is to manage TaskManager slots, Flink’s processing unit.
TaskMangers are Flink worker processes. There are multiple TaskManagers for a Flink setup. Each provides a number of slots. Each task is executed on a slot, and the number of tasks a TaskManager can handle is capped by the number of slots.
Here is a typical flow of a Flink application:
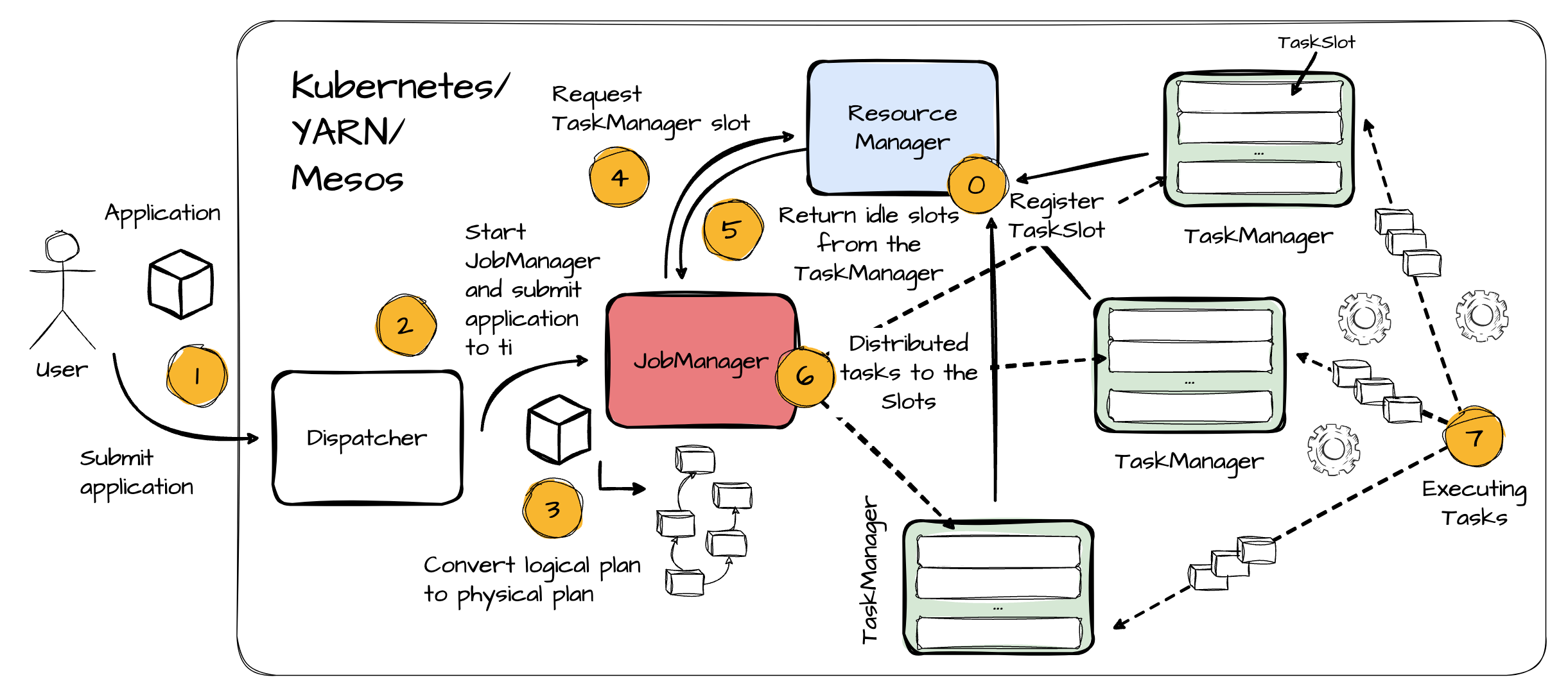
When a TaskManager starts, it registers its slots to the Resource Manager.
An application is submitted to the Dispatcher.
The Dispatcher starts the JobManager and submits the application.
An application includes the logical dataflow graph and a JAR file that packs all required dependencies to execute the graph. The following section covers dataflow programming in more detail.
When the JobManger receives an application, it converts the logical plan into the physical one, which includes tasks that can be executed in parallel.
After that, the JobManager requires the resource manager's resources (TaskManager slots).
The ResoruceManager instructs the TaskManager with idle slots and offers them to the JobManager. If the ResourceManager does not have enough slots to fulfill the JobManager’s request, it communicates to a resource provider to initiate more TaskManager processes.
When the JobManager gets the required slots, it distributes tasks from the physical graph to the TaskManager slots.
TaskManagers start executing the task.
During execution, the JobManager is also responsible for all actions that require central coordination, such as checkpointing.
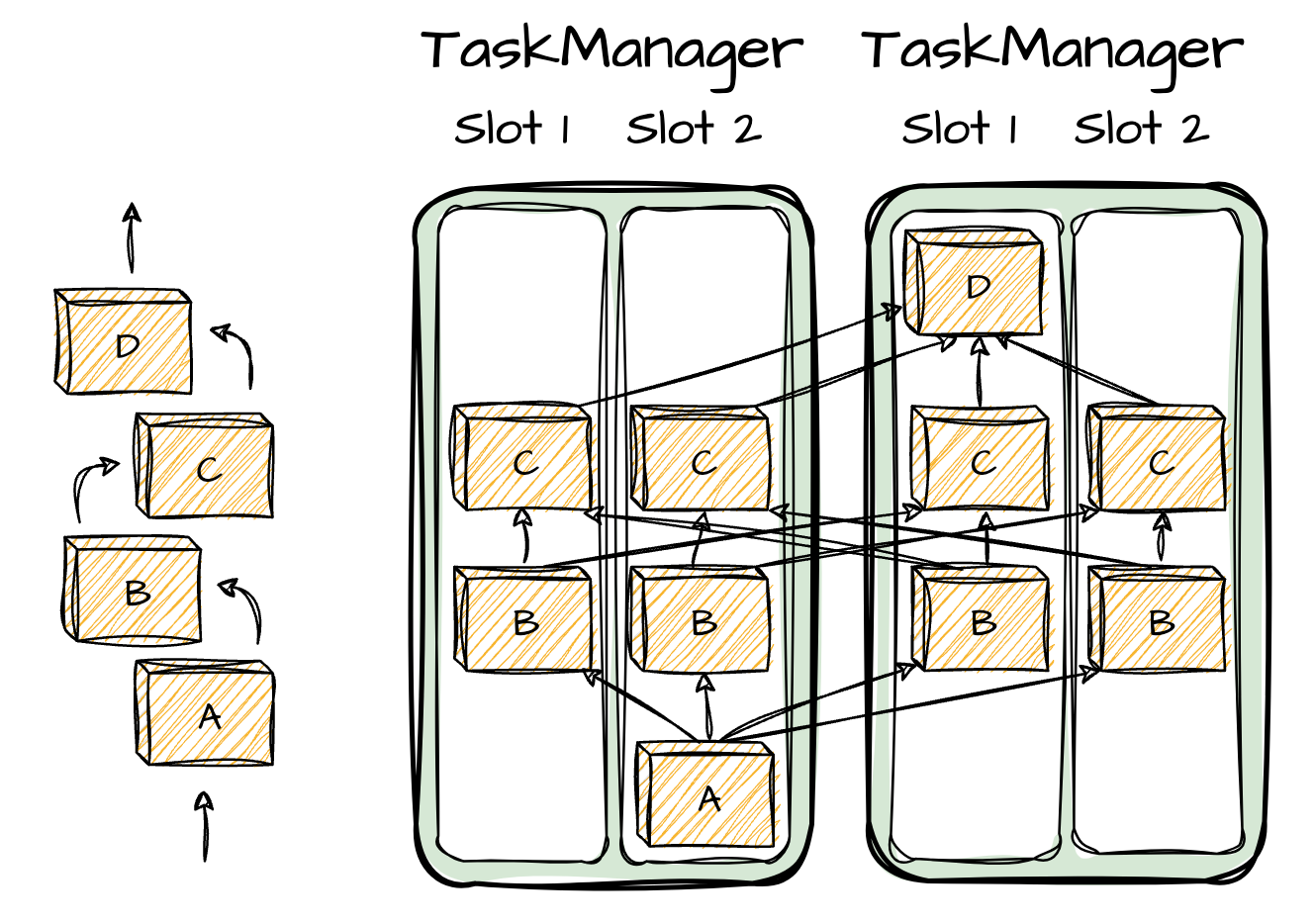
Some notes on the task execution of the Task Managers. It can execute several tasks at the same time. These tasks can be:
The subtasks are from the same operator. Each task handles a subset of data. Data can be logically partitioned based on its key; events with the same key belong to one partition. A task can handle more than one partition.
The tasks are from a different operator.
The tasks are from a different application.
As said before, a TaskManager provides a limited number of slots to control the number of concurrent tasks.
Here is an example of a physical graph with four operators. Each non-source/sink operator has a parallelism level of 4 (4 tasks). There are also two TaskManagers, each with two slots.
Model
To express data processing logic in Flink, users have to use a dataflow programming paradigm. This paradigm represents a program as a directed graph, where nodes are operators (representing computations), and edges represent data dependencies.
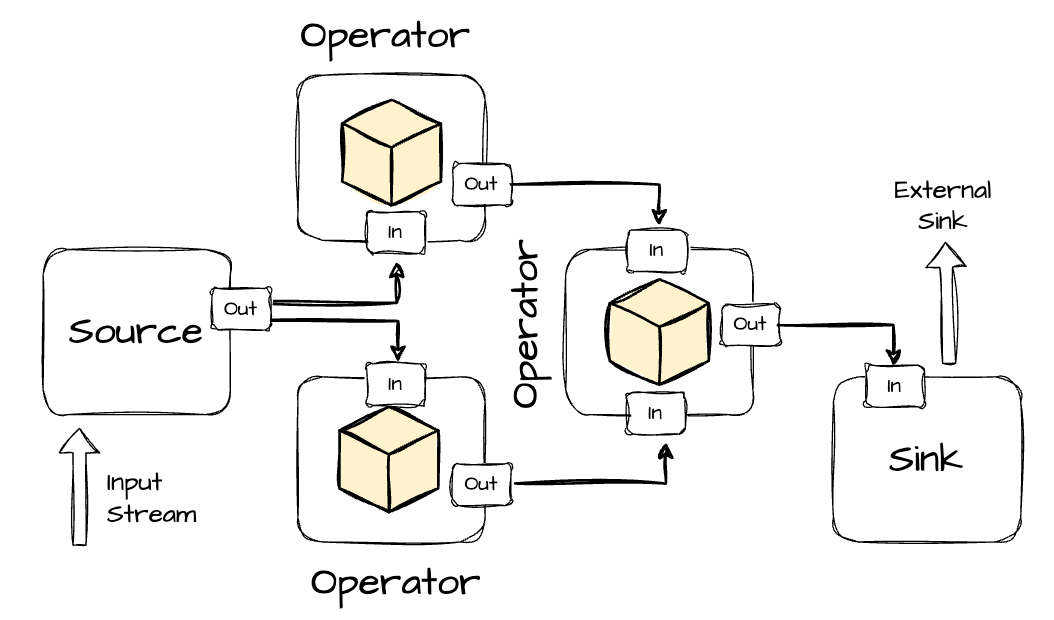
Operators consume data from inputs (external sources or other operators), apply some logic, and output the processed data to destinations, which can be external systems or subsequent operators.
A dataflow graph can exist on two levels: a logical graph and a physical graph. The logical graph provides a high-level view of the computation logic, while the physical graph (derived from the logical plan) details how the program will be executed.
So far, we’ve only discussed dataflow programming in general. Let’s now delve into it through the lens of parallel stream processing.
Stream processing engines like Flink usually offer a set of operations to ingest, transform, and output the data stream. An operation can be stateless or stateful. The stateless one doesn’t keep any state; the processing event does not depend on historical events. The independence of stateless data processing means parallelizing or restarting the processing is more straightforward.
The other type of operation is stateful, which keeps information about processed data (e.g., accumulate count calculation). This type is more challenging to parallelize or restart.
That’s how the operations are categorized based on the state; for functionality, there are types of operations: ingest (consume input data), egress (produce output data), transformation, rolling aggregation, or window:
The transformation process of each event is independent; it consumes one event after the other and applies some transformation to the data.
The rolling aggregation updated the aggregation (e.g., min, max, sum, count) with each input event. This operation is stateful; it combines the historical state with the input event to update the aggregate value.
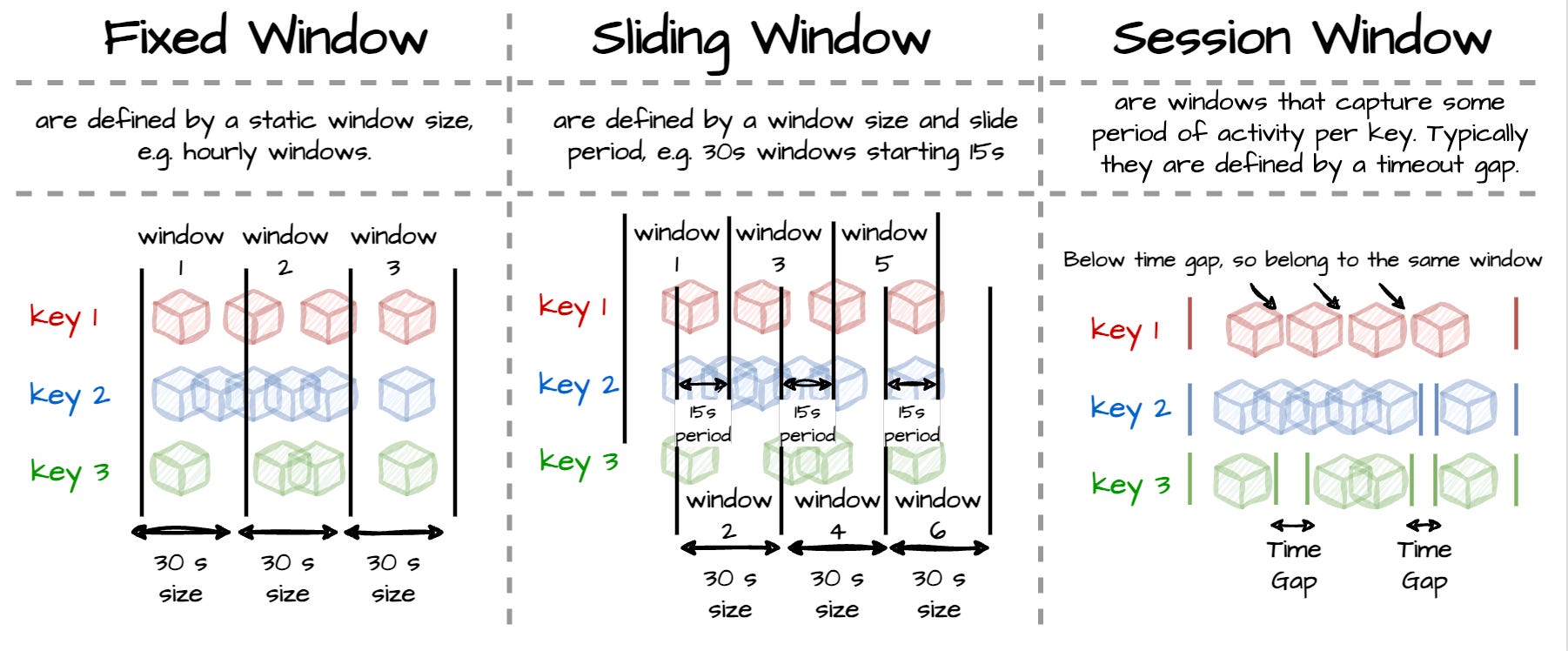
The two above processes process one event at a time. Windows operations align a finite data set called windows from the unbounded stream. There are three common types of windows:
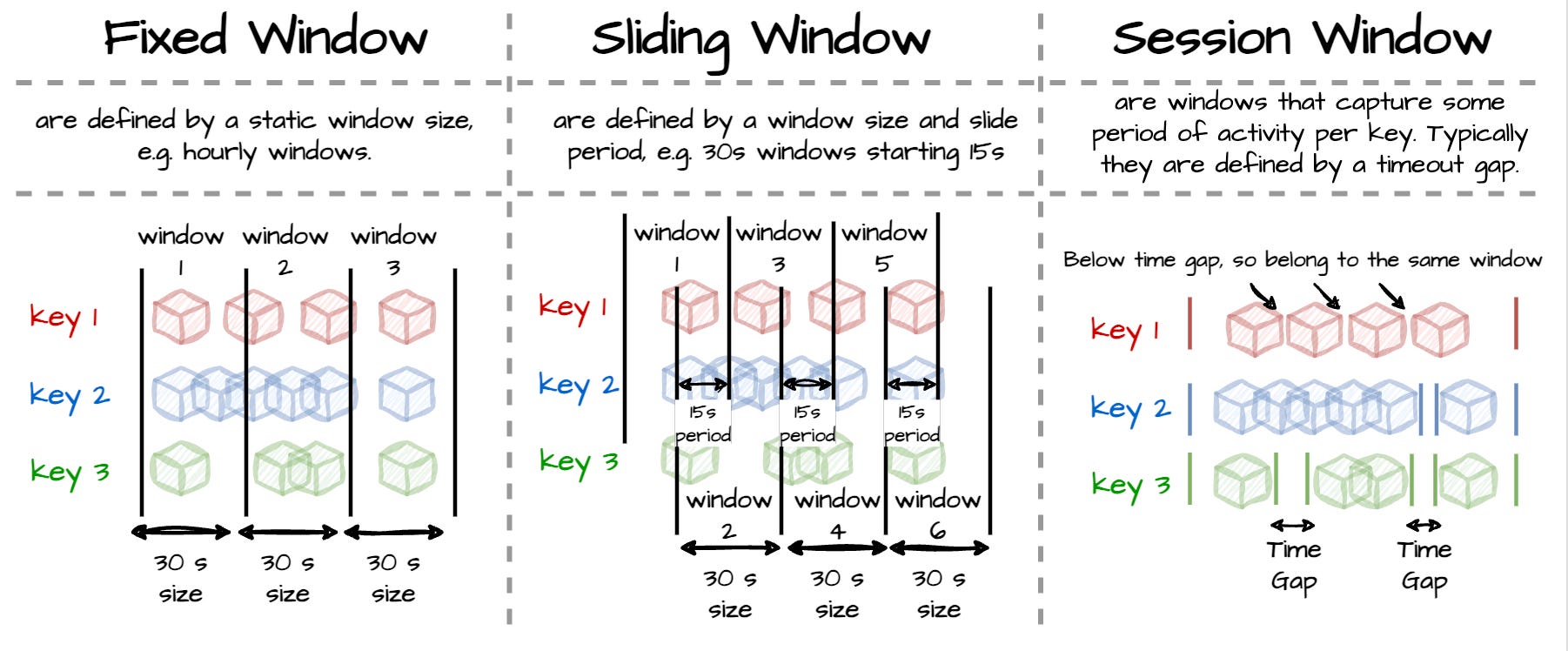
Image created by the author. Fixed (Tumpling): data is assigned into the nonoverlapping windows of fixed size (e.g., every 5 minutes)
Sliding: data is assigned into the overlapping windows of fixed size (e.g., 5 minutes window every 1 minute)
Session: data is assigned to a window based on an “inactivity gap” (e.g., the user does not use the app for 6 minutes).
Window operations are closely related to time semantics and state management. In the following sections, we will explore these concepts.
Time Semantics
When handling time-related events data, there are two domains of time:
Event Time: the time the event itself happened. For example, if the system device recorded you purchasing a game item at 11:30, this is considered the event time.
Processing Time: The time at which an event is observed at any given point during processing. For example, the purchased game item is recorded at 11:30 but only arrives at the stream processing system at 11:35; this “11:35“ is the processing time.
Event time will never change, but processing time changes constantly for each step that the data flows through. This is a critical factor when analyzing events in the context of when they occurred.
The difference between the event_time and the processing_time is called time domain skew. The skew can result from many potential reasons, such as communication delays or time spent processing in each pipeline stage.
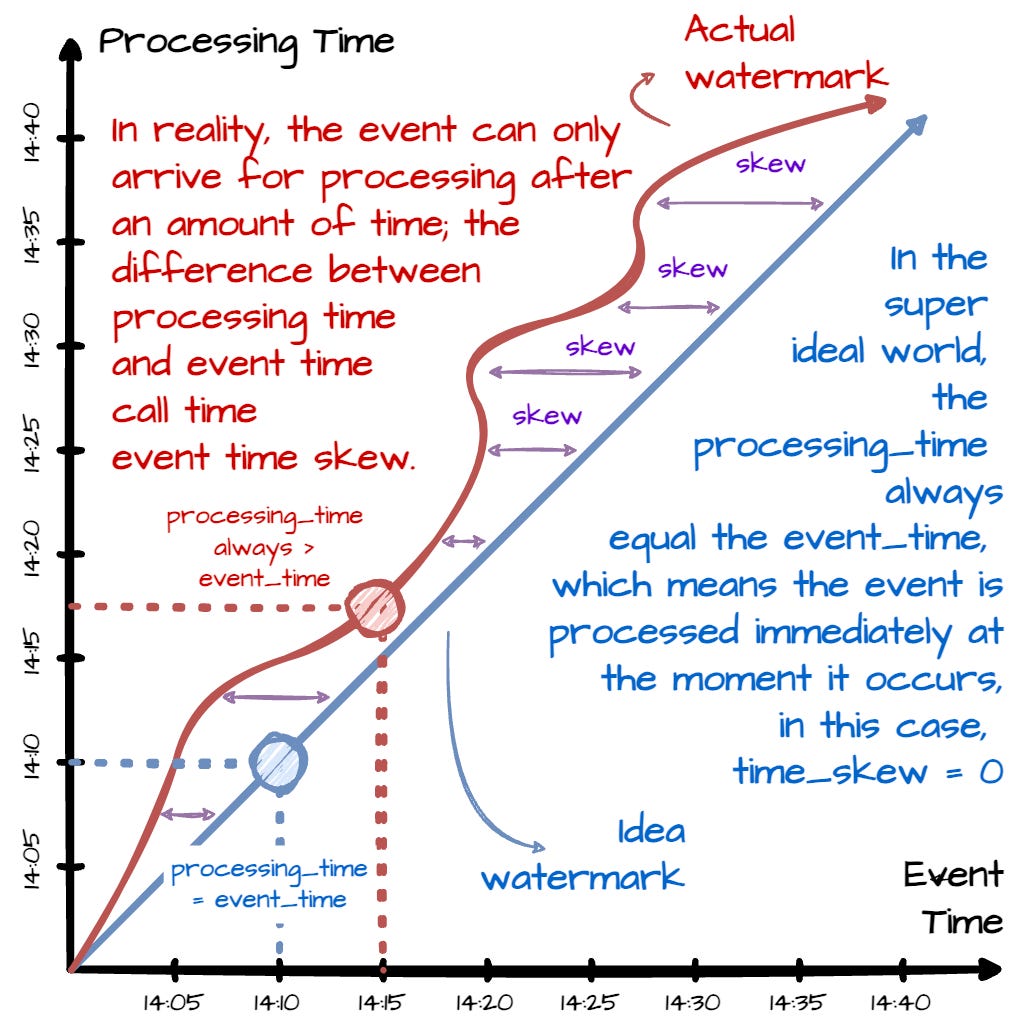
Metrics, such as watermarks, are good ways to visualize the skew. These watermarks tell the system that “no more data which have event time sooner this time will arrive.”
In a super-ideal world, the skew would always be zero; we could always process all events right when they happen.
If the watermark is T, the system can assume that no events with a timestamp less than T will appear. The watermark offers a configurable tradeoff between accuracy and latency. Eager watermarks ensure low latency but provide potentially lower accuracy; late events might arrive after the watermark. On the other hand, if watermarks are too relaxed, data might have a chance to catch up but might increase processing latency due to the time spent waiting.
In Flink, to work with event-time-based processing, all events must have a timestamp, typically representing the time when the event happened. The operators will use this timestamp to evaluate event-time-based operations, such as assigning an event to the fixed window.
Besides the timestamp, the application also needs to provide the watermarks. In Flink, watermarks are special events with a timestamp as a long value; they flow in a stream just like regular events.
State Management
If you are still confused by the “state,” imagine it as a task variable that needs to be maintained and updated with upcoming data to produce the final result.
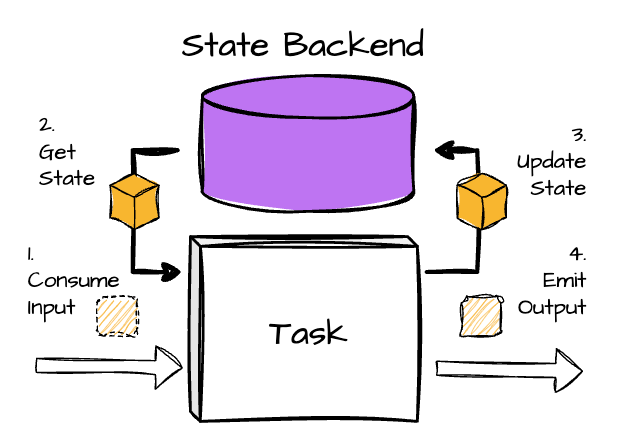
The logic of reading and writing the state is straightforward; however, managing the state efficiently is more challenging.
Type of state
State in Flink is always associated with an operator (via the operator’s states registering). There are two types of states:
Operator State: It is scoped to an operator task; all records processed by the same parallel task have access to the same state. Other tasks from different/the same operators can not access the state.
Key State: Flink keeps one state instance per event’s key and partitions all records in a way that records with the same key go to the same operator task that has a state for this key
State Backend
Flink offers different state backends that define how and where the state is stored. Flink allows users to specify the state back for the Flink jobs. Some options that can be listed are Java’s heap/off-heap memory or StartRock DB.
Checkpointing
Checkpoints help Flink achieve fault tolerance by allowing the state and the corresponding stream positions to be recovered.
The naive approach of taking a checkpoint is:
Pausing the application
Checkpointing
If a failure occurs, resume using the checkpoint.
However, this approach is impractical; it requires the whole pipeline to stop before checkpointing, resulting in higher latency.
Flink implements checkpointing using the Chandy-Lamport algorithm. It does not force the application to pause and de-couple the checkpointing from the data processing.
Flink uses a special record called a checkpoint barrier. The source operators inject it into the data stream. The barrier contains a checkpoint ID to define the checkpoint it belongs to and split the stream into two parts:
Preceded-barrier state modifications belong to this checkpoint.
Followed-barrier state modifications belong to the next checkpoint.
Let’s explore the checkpoint process in Flink:
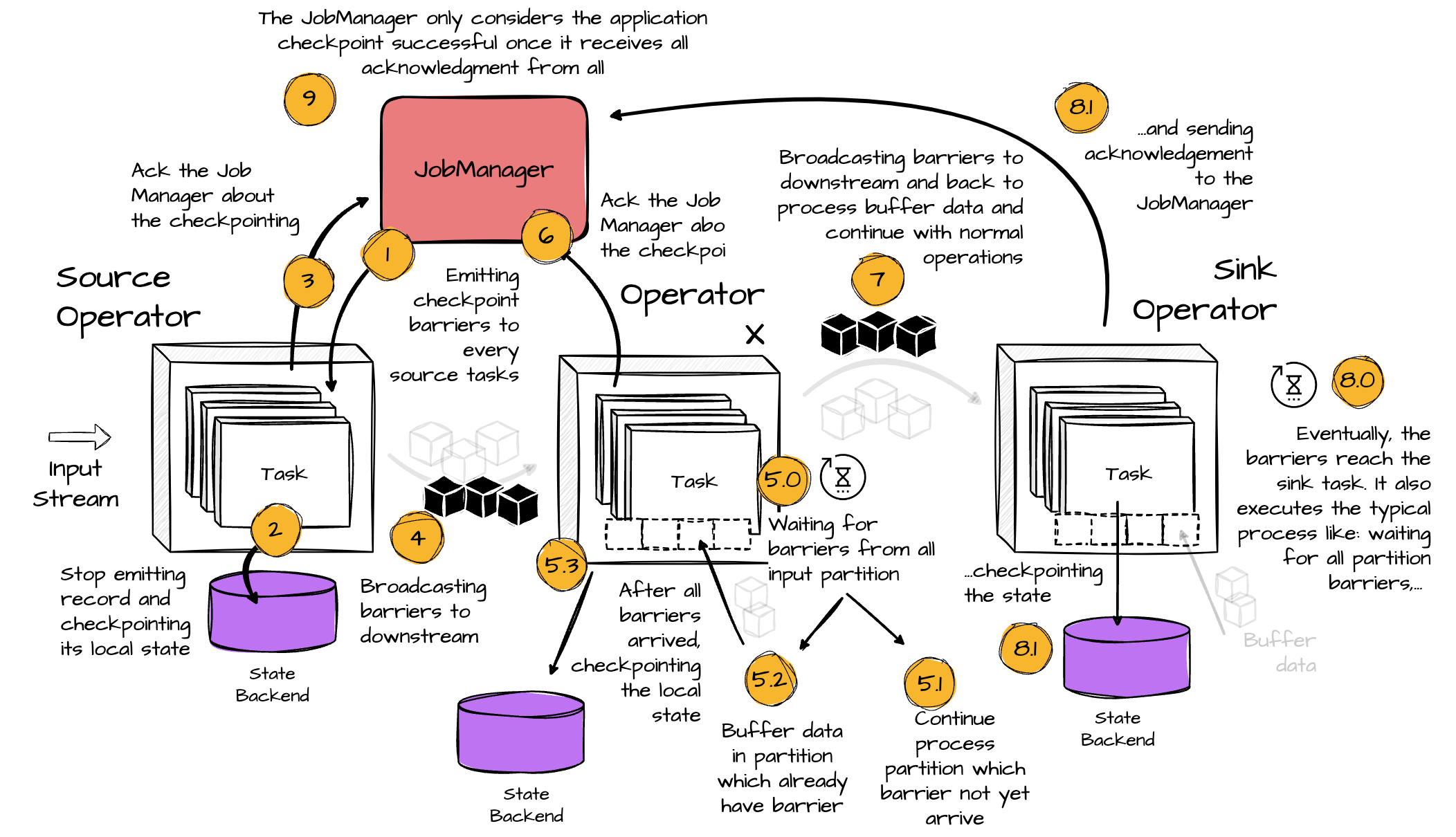
The JobManager initiates a checkpoint; it sends a checkpoint barrier with the checkpoint ID to every source operator. (each partition has one associated barrier)
When a source receives this message, it pauses emitting events to downstreams and triggers a checkpoint of its local state to the state backend. It then broadcasts the barrier to all outgoing stream partitions.
The backend notifies the task once it has completed checkpointing the state. The task sends the checkpoint confirmation to the Job Manager.
After broadcasting the barriers, the source gets back to its regular operation.
When a connected task receives the broadcast barrier, it waits for barriers from all its input partitions (a task can handle more than one partition) for the checkpoint. It continues processing data from the partition that did not receive the barrier. On the partition that has the barrier, coming data won’t be processed; instead, it is buffered. This avoids mixing records from before and after the checkpoint barrier.
When a task receives barriers from all its partitions, it starts the checkpoint of the state to the local state backend and broadcasts the checkpoint to its downstream tasks.
Once all partitions' checkpoint barriers are emitted, the task returns to processing buffered data. When buffered data is processed, the task returns to processing its input stream.
In the end, the barriers reach the sink task. It also executes the checkpoint process like the above: waiting for all partition barriers, checkpointing their state, and sending confirmation to the JobManager.
The JobManager only considers the application checkpoint successful once it receives all acknowledgment from all task applications.
Outro
Phew, I think that’s it for the first article about Flink.
Thank you for reading this far.
Writing about this engine turned out to be harder than I expected.
Real-time processing is fundamentally different from batch processing, so I felt the need to introduce some related concepts before diving into Flink. We covered dataflow programming, event-time vs. processing time, watermarks, and window functions. Then, we explored Flink’s architecture and how it manages the state.
I hope you learned something about Flink through this article. If you’d like to read more articles on Flink or real-time processing, please let me know.
Now, it’s time to say goodbye.
See you on my next piece.
References
[1] Flink Official Documentation
[2] Fabian Hueske, Vasiliki Kalavri, Stream Processing with Apache Flink: Fundamentals, Implementation, and Operation of Streaming Applications (2019)
Before you leave
If you want to discuss this further, please leave a comment or contact me via LinkedIn, Email, or Twitter.
It might take you five minutes to read, but it took me more than five days to prepare, so it would greatly motivate me if you considered subscribing to receive my writing.
👏
This is the best explanation of flink’s internals that I’ve read. Definitely want more articles on stream processing, it’s such an interesting topic to explore.