
Apache Arrow For Data Engineers
Everything you need to know, from what it is, its motivation, and how it provides value?

To celebrate Lunar New Year (the true New Year holiday in Vietnam), I’m offering 50% off the annual subscription. The offer ends soon; grab it now to get full access to nearly 200 high-quality data engineering articles.
Intro
Polars, Pandas, Spark, Snowflake, BigQuery, DuckDB, DataFusion, Clickhouse.
Besides the fact that all of these are solutions for handling analytics data, do you know what one thing they have in common?
They all leverage Apache Arrow.
From improving data transfer (BigQuery, Snowflake, Clickhouse…) to in-memory data representation (Pandas, Polars, DataFusion)
Fairly speaking, the data engineering field will be different if we don’t have Arrow.
This article will delve into Apache Arrow, exploring what it is, its motivation, how it organizes data, and finally, how it can help us.
Overview
The Apache Arrow format project began in February 2016, focusing on columnar in-memory analytics workloads. Unlike Parquet or CSV, which specify how data is organized on disk, Arrow focuses on how data is organized in memory.
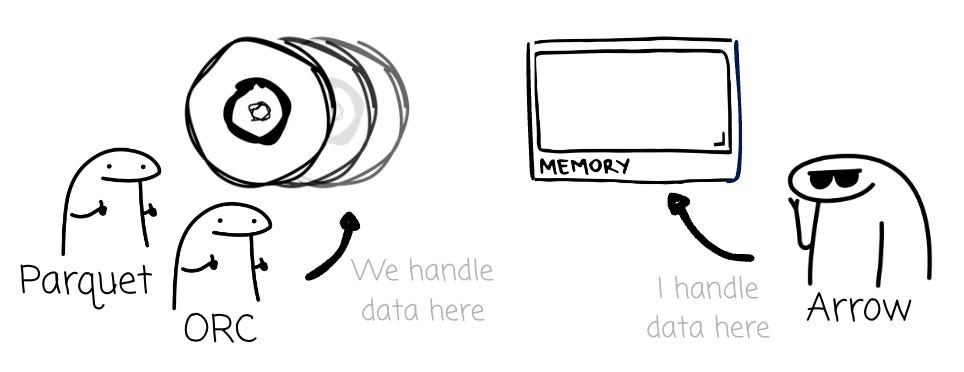
The creators try to build Arrow as a community standard in-memory format for workload analytics. These foundations attract many contributors from projects such as Pandas, Spark, Cassandra, Apache Calcite, Dremio, and Ibis.
Beyond a standard for organizing data in memory, the Apache Arrow project offers libraries that implement the format in various languages, including C++, Java, Python, Rust, Go, C#, and R, enabling developers to create, manipulate, and share Arrow data natively.
How does it organize the data for a single column?
Terminology
To understand how Arrow organizes data, let’s check out some terminology in the Arrow:
An array is a logical sequence of values with a defined length, all sharing the same type. Array is immutable.
A chunked array is a list of arrays.
A slot is a single logical value within an array.
The Buffer is a sequential virtual address space with a fixed length, where any byte can be accessed via a pointer offset within the region’s length. You can think of a buffer as a physical container for the array.
Inside an array
Arrow represents a single column of values using the array object, which is defined by a few pieces of metadata and data:
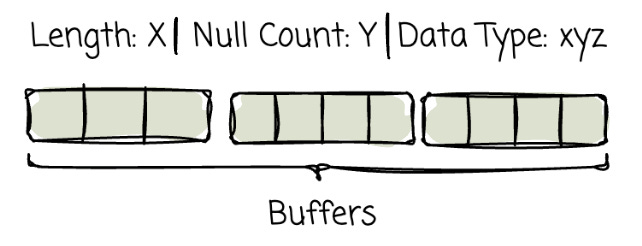
The array’s length: A 64-bit signed integer, and the null count
The null count: Also a 64-bit signed integer.
The data type
Buffers:
Validity bitmap: Almost all array types have a validity bitmap memory buffer, which encodes the null information for each array's slot value.
Offset Buffer: Some array types, such as Variable-size Binary Layout, have offset buffers to locate the start position of each slot in the data buffer.
Value Buffer: The buffers contain the array’s data
There are more buffers for some complex types, such as Size Buffer (ListView Layout) or Types Buffer (Union Layout)
Next, we will explore some examples to understand how Arrow represents the three types of arrays: arrays of fixed-size primitive values and arrays of variable-size binary values.
Fixed-size primitive
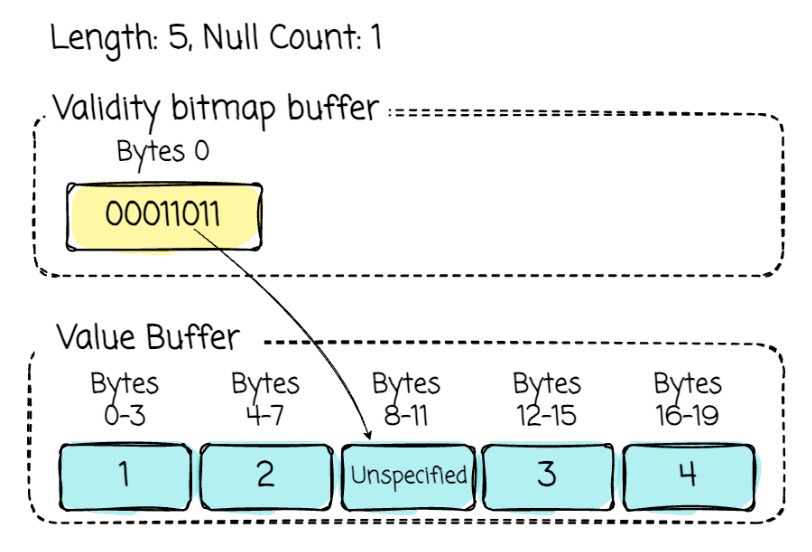
This is the most straightforward one, as all values have the same size, thus each will be stored in the same slot width.
Given an integer column: [1, 2, Null, 3, 4]. Here is the Arrow layout of this data:
Variable-size binary
A variable-size binary has an additional buffer, called an offset, in addition to the data buffer. The offset buffer’s length equals the value array’s length + 1. This buffer encodes the start position of each slot in the data buffer.
The value length in each slot is the difference between the offset at that slot’s index and the subsequent offset.
Offsets must increase monotonically, even for null slots, ensuring that all values are well-defined and accessible via their corresponding offsets. Typically, the first slot in the offsets array is 0, and the last slot is the length of the values array.
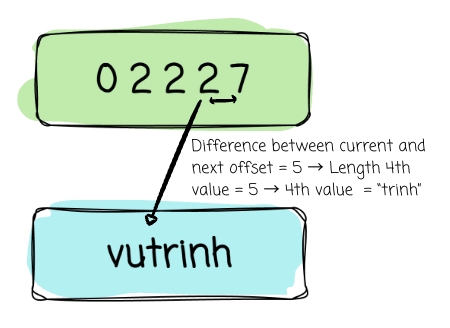
Given a column [“vu“, null, null, “trinh“]
The array will be organized as follows:
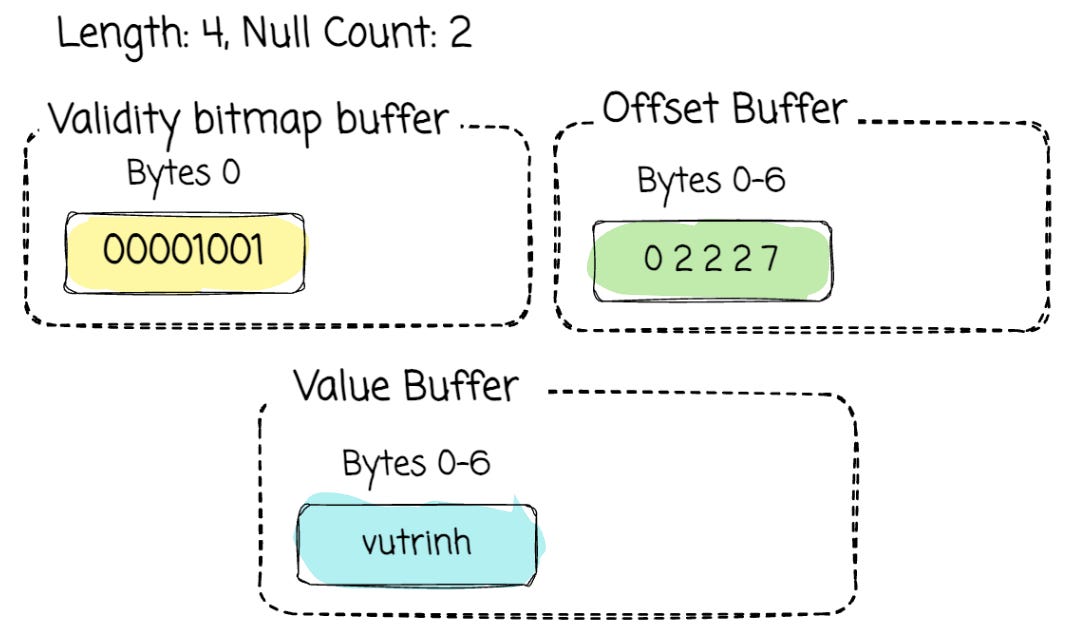
The not-null values will be stored continuously in the value buffer. To locate the value for each array slot, the reader can utilize the offset buffer. In this case, it is [0, 2, 2, 2, 7].
To read each slot, we begin with its start offset, which corresponds to the position in the offset buffer. Then the length of this value is calculated by the difference between the next offset and the current offset from the offset buffer.
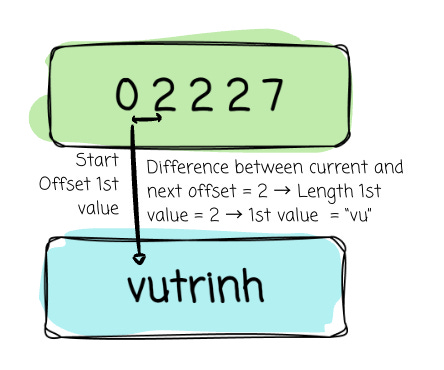
1st value slot:
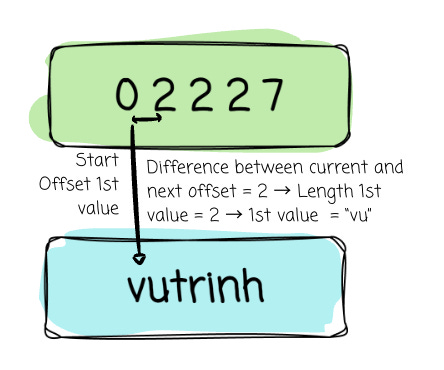
Start offset: offset_buffer[0] = 0
Length = next offset - current offset = 2 - 0 =2
→ Value = “vu“
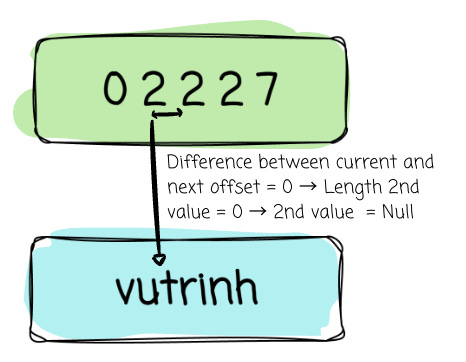
2nd value slot:
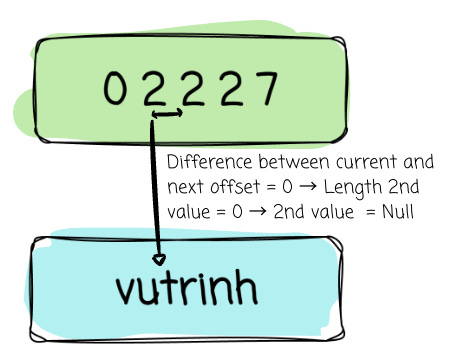
Start offset: offset_buffer[1] = 2
Length = next offset - current offset = 2 - 2 = 0
→ Value = Null
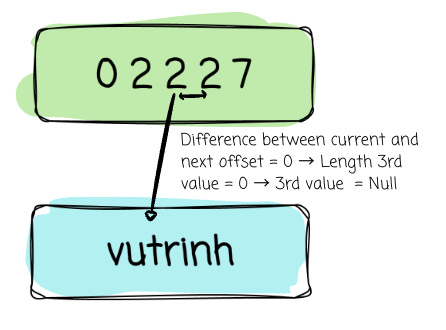
3rd value slot:
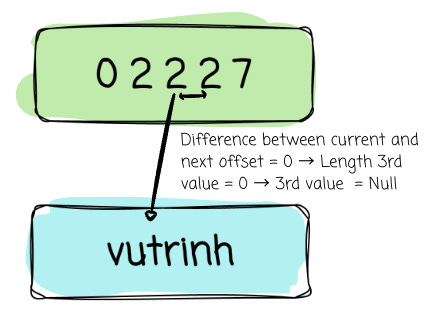
Start offset: offset_buffer[2] = 2
Length = next offset - current offset = 2 - 2 = 0
→ Value = Null
4th value slot:
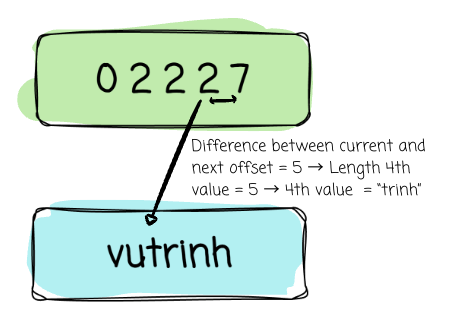
Start offset: offset_buffer[3] = 2
Length = next offset - current offset = 7 - 2 = 5
→ Value = “trinh“
The above are only two examples of how Arrow organizes different data types. It supports a wide range of types, including complex ones such as Map or Struct. All are suited to the array abstraction. You can check more here.
A Record Batch
To represent tabular data, the Arrow specification introduces the Record Batch abstraction. It is used in many serialization and computation functions. It has:
To celebrate Lunar New Year (the true New Year holiday in Vietnam), I’m offering 50% off the annual subscription. The offer ends soon; grab it now to get full access to nearly 200 high-quality data engineering articles.