

To celebrate Lunar New Year (the true New Year holiday in Vietnam), I’m offering 50% off the annual subscription. The offer ends soon; grab it now to get full access to nearly 200 high-quality data engineering articles.
Intro
Over the years, Airflow has been one of the tools I’ve used the most. Hours of writing DAGs, operating, debugging, and deploying pipelines have made working with Airflow feel like second nature—almost like autopilot mode.
However, this comfort made me realize that I’d drifted away from understanding its core principles and fundamentals. So, I decided it was time to revisit Airflow—one of the most popular orchestration tools in modern data engineering.
Note: This article will not provide tutorials on writing DAGs or deploying the Airflow environment. All the example will be delivered in pseudo code, for detailed tutorial and example, you can check Airflow’s official documentation.
The Origin Story
Apache Airflow was created in 2014 at Airbnb when the company was dealing with massive and increasingly complex data workflows. At the time, existing orchestration tools were either too rigid, lacked scalability, or couldn’t accommodate the dynamic nature of data pipelines. To address this challenge, Maxime Beauchemin, a data engineer at Airbnb, spearheaded the creation of Airflow.
The guiding principle was simple: make workflow orchestration flexible, programmable, and maintainable by writing workflows as code. By leveraging Python programming language, Airflow gave data engineers a familiar and intuitive way to define workflows while integrating seamlessly into modern software engineering practices.
Airflow quickly gained traction and, in 2016, joined the Apache Software Foundation, becoming an open-source project with a robust and growing community.
If you've joined a new company these days, you're likely to work with Airflow.
Overview
Orchestrating a complete data pipeline presents numerous challenges.
When should we schedule the pulling of data from a third-party API?
How do we effectively manage dependencies between the API call and the data processing job?
What happens in the event of a failure? Can we observe it? If so, can we retry and execute backfilling?
Apache Airflow simplifies this problem by allowing engineers to define workflows as code and automating their execution.
At its core, Airflow operates on the concept of Directed Acyclic Graphs (DAGs) to model workflows. It is essentially a roadmap for the workflow and contains two main components:
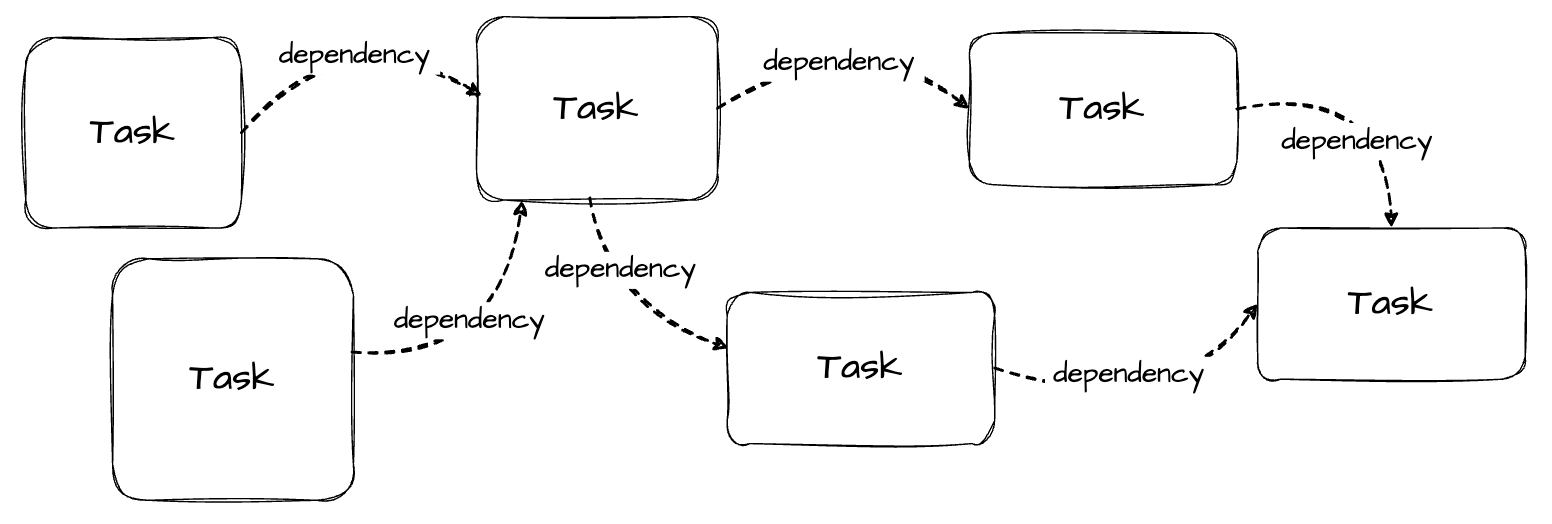
Tasks (Nodes) are individual work units, such as running a query, copying data, executing a script, or calling an API.
Dependencies (Edges): The relationships between tasks that define their execution order (e.g., preprocessing is executed only after retrieving data from a third-party API).
Airflow ensures tasks are executed sequentially or in parallel (based on their dependencies), retries are automatically managed on failure (based on their retry configuration), and task execution is thoroughly logged for monitoring and debugging purposes.
In the next section, we will look closer at Airflow's internals.
The Internals
There are several components inside Airflow:
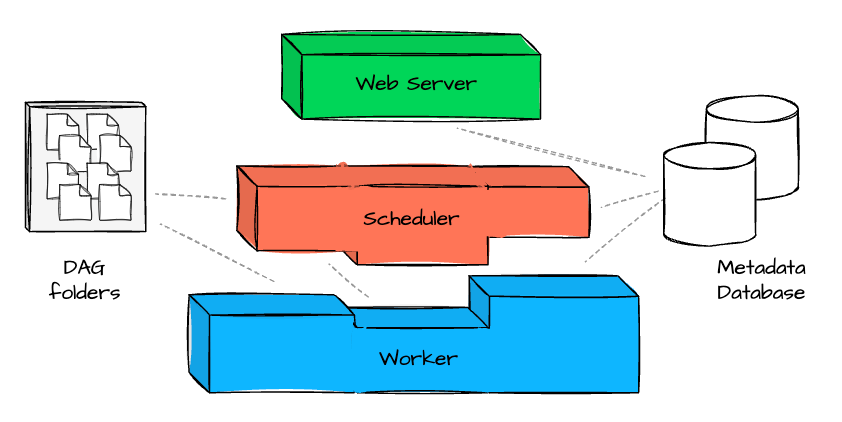
Scheduler: The component responsible for parsing DAG files, scheduling tasks, and queuing them for execution based on their dependencies and schedules.
Web Server provides the Airflow UI, allowing users to visualize workflows, monitor task execution, inspect logs, and trigger DAG runs.
Metadata Database: A central database that stores all metadata, including DAG definitions, task states, execution logs, and schedules. It’s essential for tracking the history of workflows.
DAG folders: It contains DAG files defined by users.
Workers: Components that execute the tasks assigned by the executor. Depending on the executor (e.g., Celery or Kubernetes), tasks are distributed across one or more worker nodes.
To celebrate Lunar New Year (the true New Year holiday in Vietnam), I’m offering 50% off the annual subscription. The offer ends soon; grab it now to get full access to nearly 200 high-quality data engineering articles.
Workflow Between Components
The workflow between Airflow’s components can be broken down into the following steps:
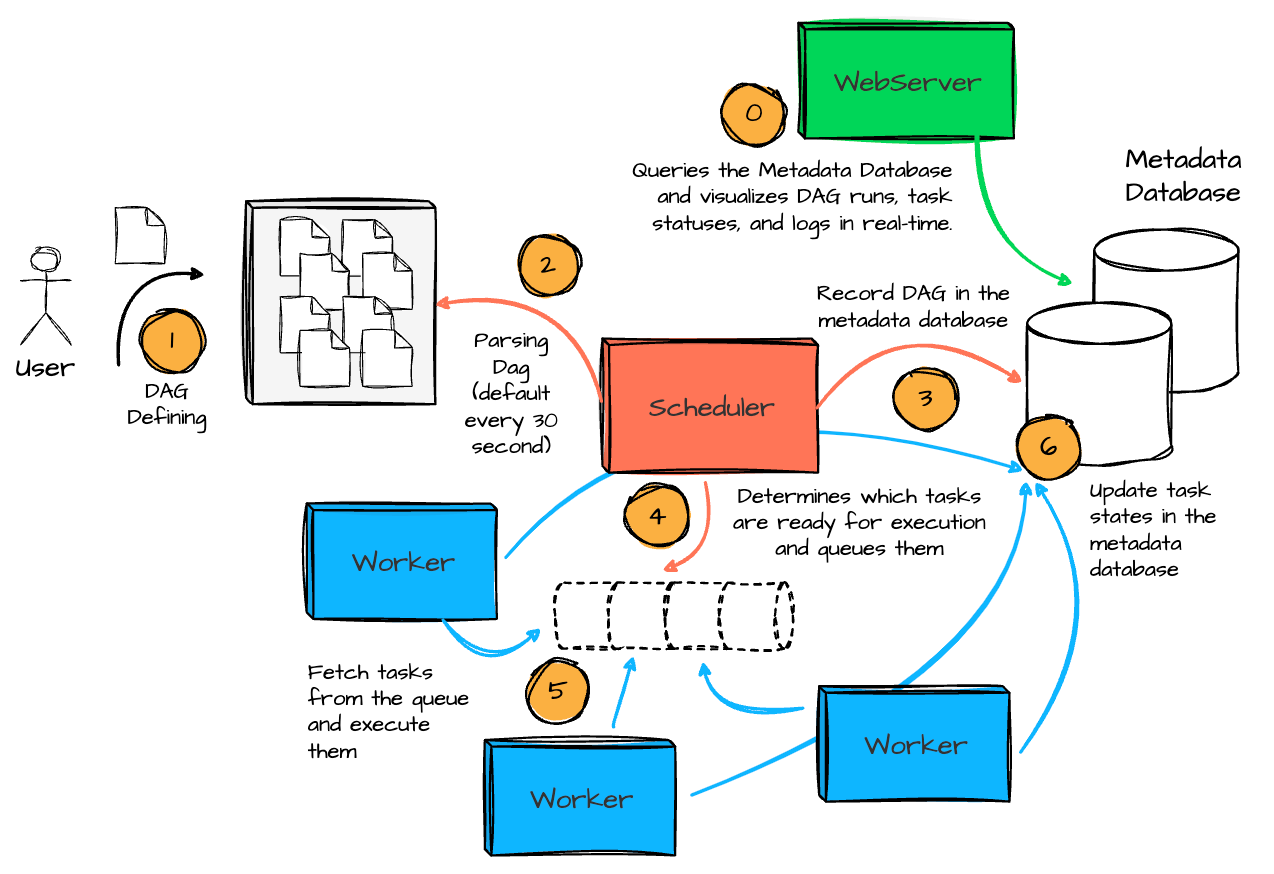
DAG defining: The users define the DAG with desired tasks and logic, including when to begin running it and the scheduled interval.
DAG Parsing: The Scheduler scans the DAG directory, parses the DAG file, and loads them into the Metadata Database.
Scheduling: Based on the DAG definitions and schedule intervals, the Scheduler determines which tasks are ready for execution and queues them.
Task Execution: The Executor fetches the queued tasks and assigns them to available Workers. The Workers execute the tasks, and task states are updated in the Metadata Database.
Monitoring: The Web Server queries the Metadata Database and visualizes DAG runs, task statuses, and logs in real-time. Users can monitor task progress, inspect logs, or trigger manual DAG runs from the UI.
Retries and State Updates: If a task fails, the Scheduler ensures retries are handled according to the task configuration. The Executor updates task states in the database until all tasks are completed successfully or fail beyond retry limits.
DAGs and Tasks
To define the workflow, we define the DAG in a Python script.
Each task represents a specific operation in the pipeline, and we can define task dependencies using a simple syntax.
Here is a pseudo-Python code of Airflow’s DAG and tasks:

Exchanging data between tasks
Airflow offers a mechanism for sharing data between tasks called XCom (Cross-Communication) when one task needs to consume data from another.
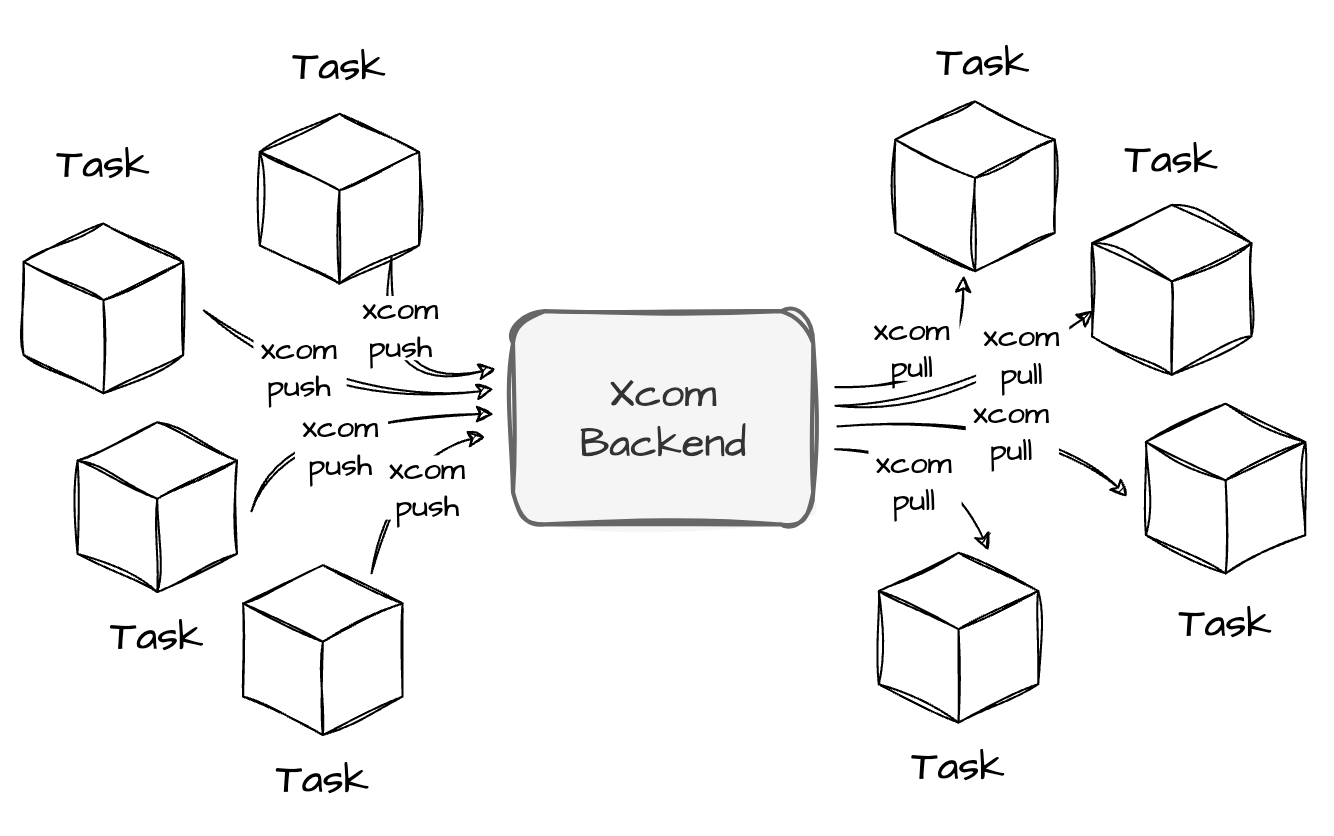
XCom allows tasks to push and pull small amounts of data during execution. For example, one task can push a result using xcom_push (or achieve by simply returning in the execute method ) and another task can retrieve that result using xcom_pull.
The way the data in XCom is stored, written, and retrieved can be controlled by the XCom backend. The default one will store the XCom data in the metadata database. In addition, we can configure Xcom to be stored in Object Storage or desired custom backend.
Task Concurrency and Resource Management
Airflow allows fine-grained control over task concurrency and resource management to optimize pipeline execution:
DAG-Level Concurrency: We can configure the
max_active_runsparameter to limit the number of active DAG runs for a single DAG.Task-Level Concurrency: The
max_active_tasksparameter controls how many tasks in a DAG can run concurrently.Pools: Resource pools allow you to limit the number of parallel tasks that share specific resources (e.g., database connections).
Queue Management: Tasks can be assigned to specific queues to prioritize execution based on resource availability or criticality.
Operators and Hooks
Airflow provides a robust system of operators and hooks that effectively interact with external systems and define task functionality. These components are essential building blocks for creating modular and reusable workflows.
Operators
We use operators to define the tasks. They encapsulate the logic for what a task should accomplish. An operator is simply a Python class that contains needed logic and implements a required method called execute , which act as the entry point for the worker to execute the task; operators can be categorized as:
Action Operators: Perform specific actions such as running a Python function, executing a Bash command, or triggering an API call. Examples include
PythonOperator,BashOperator, andSimpleHttpOperator.Transfer Operators: Facilitate moving data between systems, such as
S3ToGCSOperatororMySqlToPostgresOperator.Sensor Operators: Wait for an external condition to be met before proceeding. Examples include
FileSensor(waiting for a file) andExternalTaskSensor(waiting for another DAG to complete).
Operators are designed to be highly configurable and composable, making it easy to build tasks tailored to your specific needs; providers or Airflow itself offers many existing operators to make our life easier (most cloud vendors like Google or AWS have supported operators to work with their service); also, we can write custom operators based on our need (e.g., existed dbt operators only work with Cloud version, so a local-dbt operator is needed here). The custom operators are expected to be seamless here; we only need to inherit the BaseOpertor class and add the required logic.
Hooks
We use Hooks to define interfaces that manage connections to external systems. They handle authentication, session management, and other connection-related functions. Hooks are often used within Operators to simplify integration with services like databases or APIs. Examples include:
Database Hooks:
PostgresHook,MySqlHook, andMongoHookfor interacting with different database systems.Cloud Service Hooks:
S3Hook,GCSHook, andAzureBlobStorageHookfor connecting to cloud storage.API Hooks:
HttpHook: For making HTTP requests or interacting with REST APIs.
Like operators, we can use existing hooks or create custom ones if needed.
Executors
Executors in Airflow are responsible for determining how tasks are executed. Different executors offer varying levels of scalability, concurrency, and complexity, allowing you to choose the right one for your specific workload:
SequentialExecutor: Ideal for testing and development, this executor runs tasks sequentially in a single process. It's simple but unsuitable for production due to its lack of parallelism.
LocalExecutor supports parallel execution on a single machine using multiple processes. It is suitable for small—to medium-sized workflows that require concurrency but don't need distributed execution.
CeleryExecutor: A distributed task execution framework that uses a message broker (e.g., RabbitMQ or Redis) to distribute tasks across multiple worker nodes. It is highly scalable and a common choice for production environments.
KubernetesExecutor: Designed for cloud-native and containerized environments, this executor dynamically creates Kubernetes pods for each task. It provides excellent resource isolation, scalability, and fault tolerance, making it ideal for large-scale workflows.
DebugExecutor: This executor is primarily used for debugging. It runs tasks locally using the same process as the Airflow Scheduler, simplifying troubleshooting during DAG development.
Deployment
Deploying Airflow ranges from running a lightweight local instance for testing and development to setting up a robust, scalable, and production-ready environment. Here's an overview of the deployment process:
On a single machine
Airflow can be deployed directly on a single machine (airflow standalone) for testing and development. This setup will initiate all the required components (scheduler, web server, database) as a separate process on our machine.
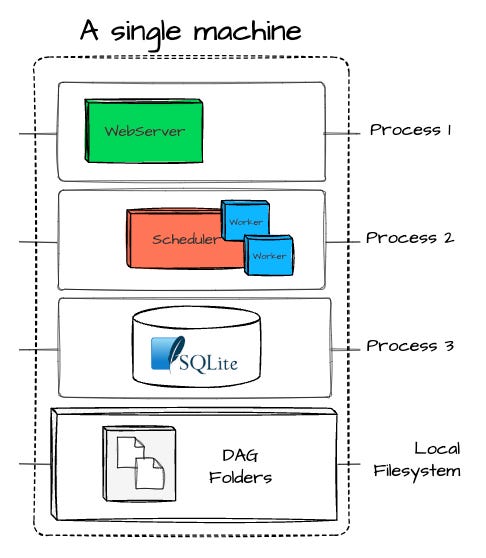
Another way to deploy Airflow on a single machine is by separting each process into a separate container (via Docker or on a local Kubernetes cluster such as Minikube)
However, a single-machine deployment is insufficient when operating Airflow in production, which requires scalability, availability, and fault tolerance.
Distributed Deployment
Airflow can be deployed in a distributed architecture; components are deployed independently and redundantly; each element is live on a separate machine and can be optionally deployed in multiple instances on different machines. (e.g., scheduler and webserver are on two other machines, the scheduler can have three instances deployed on three machines)
This setup allows for better load distribution, making it suitable for handling large-scale workflows.
The most common approach for Airflow distributed-architecture deployment I observed is using Kubernetes.
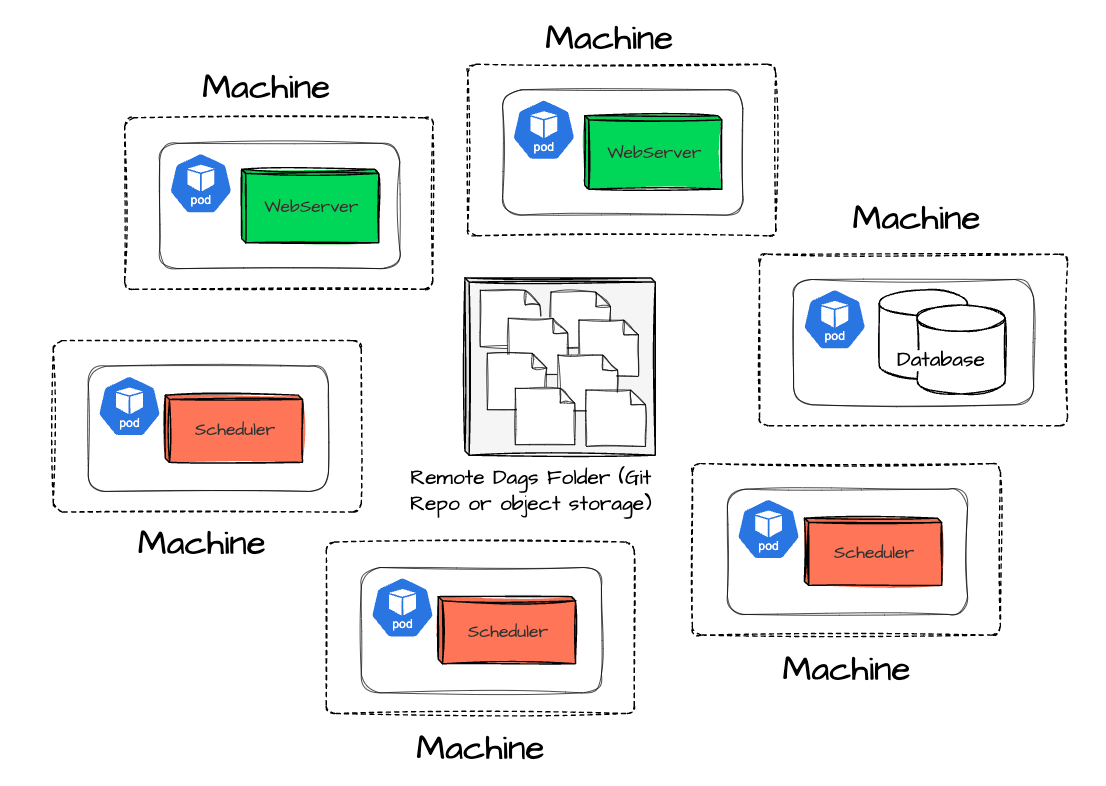
If you use Airflow managed by a cloud vendor like AWS or Google, your Airflow environment is deployed on a Kubernetes cluster, and all the DAGs files are stored in the object storage (S3 for AWS and GCS for Google Cloud)
Outro
Throughout this article, we have explored Apache Airflow’s origins, core concepts, and internal architecture. We have seen how Airflow uses Directed Acyclic Graphs (DAGs) to orchestrate workflows and manage dependencies. We have discussed its core components, such as the Scheduler, Web Server, and Metadata Database.
We also covered Airflow’s abstractions, such as Operators and Hooks, the different executor options, and the deployment approaches, which range from single-machine setups to distributed and Kubernetes-based environments.
Thank you for reading this far.
Please give feedback or correct me in the comments if you see I missed anything.
Now, it's time to say goodbye. See you on my next pieces.
References
[1] Apache Airflow Official Documentation
[2] Apache Airflow from Wikipedia
[3] Airbnb Engineer, Airflow: a workflow management platform (2015)
It might take you five minutes to read, but it took me more than five days to prepare, so it would greatly motivate me if you considered subscribing to receive my writing.
If I am not mistaken the dag files parsing changed a bit in airflow 3.0
Great . i love this .. is there any tutorial for beginners to try hands on ..