
I spent 7 hours learning Amazon S3
S3 for data engineers: what it is, why it's popular in data engineering, and how to use it effectively. These insights can also help you work with other object storage services.

I will publish a paid article every Tuesday. I wrote these with one goal in mind: to offer my readers, whether they are feeling overwhelmed when beginning the journey or seeking a deeper understanding of the field, 15 minutes of practical lessons and insights on nearly everything related to data engineering.
I invite you to join the club with a 50% discount on the yearly package. Let’s not be suck as data engineering together.

Intro
The rise of cloud computing brings a new approach to software development, eliminating the need for planning how many servers or which licenses need to be purchased. With a few clicks on the AWS or Google Cloud console, companies can have their backends, databases, or AI models up and running.
Cloud vendors want to make sure they can adapt to this rapidly changing world. They add new services, support more features for the existing ones, catch up with the most advanced hardware, or even deprecate less adopted services.
Things we’re seeing on AWS or Google Cloud are very different compared to 15 years ago. However, there is undoubtedly one service that has been there from the very beginning. It’s not obsolete; it even evolves to serve an increasing number of use cases, playing a crucial part in the data infrastructure of many organizations.
In this article, we will delve into the infamous object storage, specifically Amazon S3, exploring what it is under the hood, its key characteristics, why it is gaining increasing attention in the data engineering field, and finally, some essential considerations for using it effectively.
Note: Although the article primarily focuses on Amazon S3, I believe the insights listed could help you work with other cloud object storage services.
What is it
Object storage is a technology that manages data as units called objects. Unlike a file hierarchy on a computer, this storage organizes objects in a flat structure within containers called buckets.
Amazon Simple Storage Service (S3) is AWS's pioneering object storage service. It was first introduced in 2006. Since then, it has become the most widely used object storage platform globally. Each S3 object has:
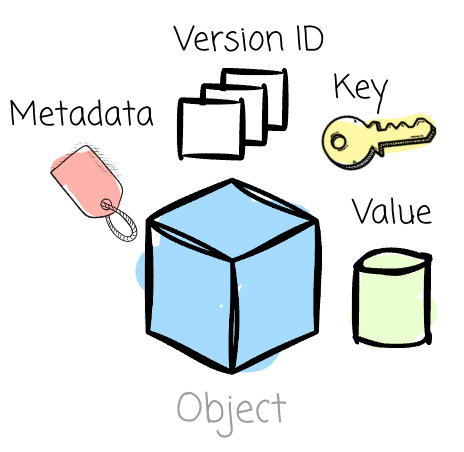
Keys: Every object within a bucket is assigned a unique key, which serves as its identifier.
Prefix: Object storage does not have folders. However, users can organize the data using a prefix to make it look like folders. A prefix is a string of characters at the beginning of the object key.
For example, two objects with the keys
reports/2025/sales.csvandreports/2025/inventory.csvwill appear to be in a2025folder, which is inside areportsfolder.However, they are just two distinct objects in the bucket that happen to share the
reports/2025/prefix. No actual folders here.Prefix plays a crucial role in how S3 distributes the workload; we will dive into that later.
Version ID: S3 lets users preserve multiple versions of the same object. When object versioning is enabled, S3 will generate a not-null version ID for that object’s version. To identify an object in the bucket, S3 uses the object key + version ID.
Value: The actual content in the object. S3 virtually supports any data in any format, as it views the object’s value as a sequence of bytes.
Metadata: There are two types of metadata:
System metadata: This metadata is assigned by S3 to manage the object
User-defined metadata: This metadata is assigned by users.
We interact with S3 not like a local hard drive, but through a set of APIs to manage objects. (Even if you can interact with this service via the console, the frontend is calling the APIs on your behalf.)
High-level services
S3 has 350+ microservices in each of AWS’s regions. At a high level, S3 has the following services:
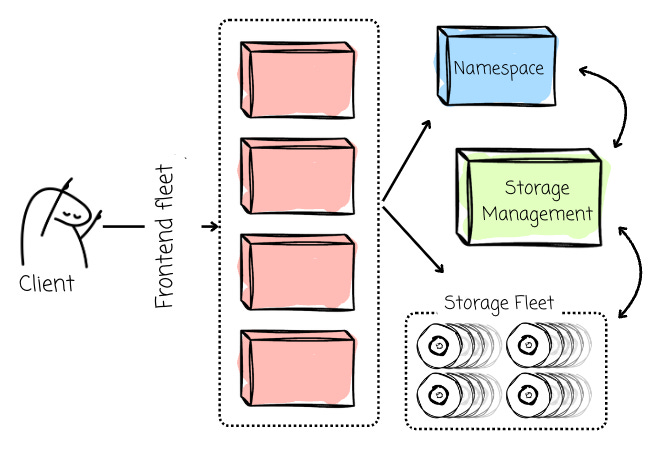
The frontend fleet to serve the REST API
The namespace services
A storage fleet with a lot of hard disks (millions of drives)
The storage management fleet that takes care of all the background operations (e.g., expiring objects, replicating objects…)
How does it distribute the load?
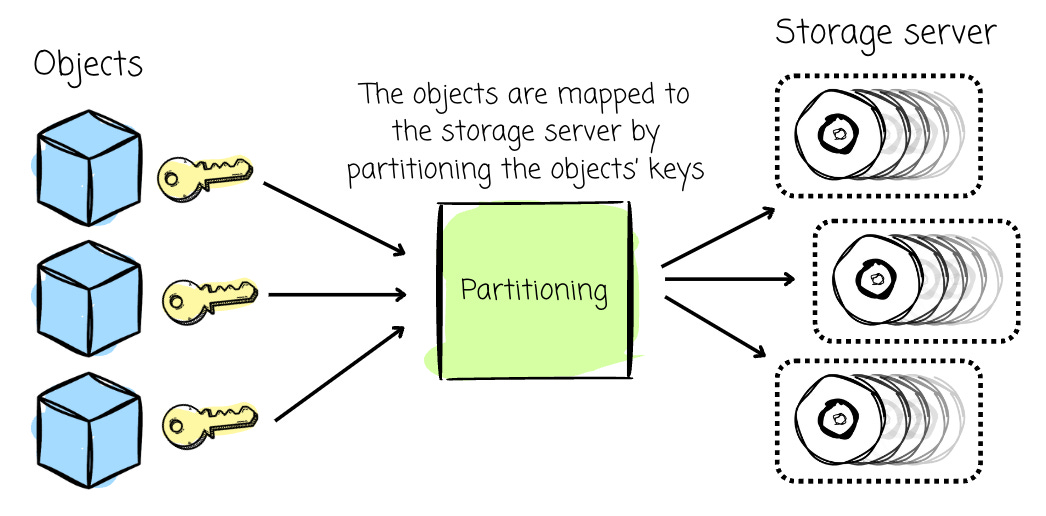
When users want to upload objects, they issue `PUT` requests, which are handled by the front end. The objects are mapped to the storage server by partitioning the objects’ keys (more specifically, the prefixes) over multiple servers in a lexicographically ordered manner. Therefore, when clients want to read these objects, the workload can be distributed among multiple servers.
Keep reading with a 7-day free trial
Subscribe to VuTrinh. to keep reading this post and get 7 days of free access to the full post archives.