


6 technical skills every data engineer should have
Based on my observations

I will publish a paid article every Tuesday. I wrote these with one goal in mind: to offer my readers, whether they are feeling overwhelmed when beginning the journey or seeking a deeper understanding of the field, 15 minutes of practical lessons and insights on nearly everything related to data engineering.
I invite you to join the club with a 50% discount on the yearly package. Let’s not be suck as data engineering together.

Intro
If I were to enter the data engineering field at the moment, I would feel extremely overwhelmed. Tons of tools, tools of skills, and I didn’t even put AI-related stuff on the table.
I read somewhere that the most effective approach to learning in this era is to learn things that would not change. Looking back on my journey as a data engineer, I realized that, indeed, there are a few things like that.
In this article, I shared my six technical skills that I believe every data engineers should equip themself with. They won’t be obsolete anytime soon.
Before we move on

For me, the most important aspect of learning something is having a solid feedback loop. Getting someone to provide you with feedback. Your friend, your senior colleague, or the internet community. Asking Gemini or ChatGPT to act like someone who knows what you’re doing (e.g., “imagine you’re a data engineer with 20 years of experience, help me to give feedback on this transform SQL script”) is not a bad option.
The key is to know whether what you’re doing is on the right track or not.
Data modeling
Why?
You will soon realize a fact that every subsequent process—every pipeline, every query, every machine learning model—is built upon the structure defined by the data model.

If the data warehouse is a building, data modeling is the blueprint. Without it, we have no clue what to do next. We can survive several months of blindly loading and querying data; however, the nightmare soon comes:
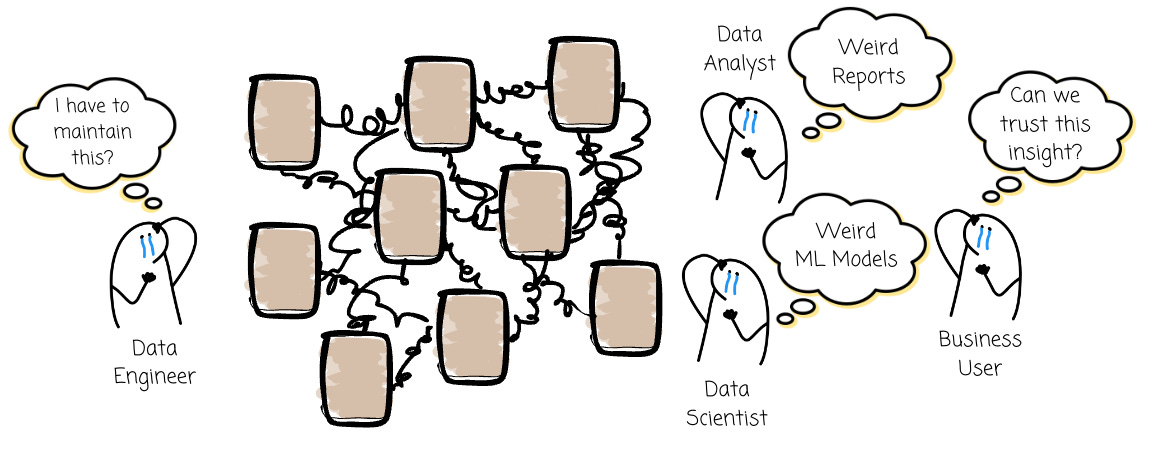
Maintenance Cost: Without a clear blueprint, we are left with a mess of SQL scripts and tables, making maintenance a costly and frustrating process
Inefficient Processing: Queries against a poorly designed structure are usually slow and resource-intensive
Data Integrity Problems: Without the enforcement of relationships and constraints, it’s hard to ensure data integrity, which could render the information unreliable.
Weird Insights: Without reliable data and standard ways to load and retrieve data, a high chance that analysts and data scientists create bad reports and ML models.
No Trust: Business users then use these weird insights to make decisions, which can lead to costly mistakes. The process soon has one more step: check if the insight is valid.
Let’s imagine a brighter scenario, if we have our nicely designed data modeling sitting there:
A Common Language: With data modeling, we have a shared, unified view of the organization's data, facilitating clear communication between stakeholders.
Data Quality and Integrity: Modeling constraints and relationships gives us a good starting point for ensuring data quality.

Reduces Errors: A data analyst knows exactly how to query a piece of insight. A data engineer knows exactly the location where the data is going to be loaded. Every necessary transformation is performed beforehand, leaving the data nicely organized and ready to be served. A good data model limits errors as much as possible.