

I spent 3 hours learning how Uber manages data quality.
I spent 3 hours learning how Uber manages data quality.
From the standard to the data quality platform

My name is Vu Trinh, and I am a data engineer.
I’m trying to make my life less dull by spending time learning and researching “how it works“ in the data engineering field.
Here is a place where I share everything I’ve learned.
Not subscribe yet? Here you go:
Intro
If you've been following my writing for a while, you might have noticed that I’ve spent a lot of time covering the technical aspects of OLAP systems, table formats, and how big companies manage their data infrastructure.
I’ve mainly focused on the "engineering" side and seemed to have overlooked the "data"—the most crucial part for anyone who works with it daily!
Thus, I’ve decided to dedicate more time to learning and writing about the "data" itself: data modeling, data management, data quality, and more.
This article will be the first you’ll read about "data" on my site.
(Hopefully, it won’t be the last!)
Today, you and I will dive into how Uber manages their data quality.
Overview
Uber extensively leverages data to provide efficient and reliable transportation worldwide, supported by hundreds of services, machine learning models, and thousands of datasets.
Being a data-driven company means that poor data can significantly impact operations—something Uber understands better than most.

To address this, they built a consolidated data quality platform that monitors, automatically detects, and manages data quality issues. This platform supports over 2,000 datasets, detecting around 90% of data quality incidents.
The following sections explore how Uber established data quality standards and built an integrated workflow to achieve operational excellence.
Challenges
To address data quality issues at Uber's data scale, they had to overcome the following limitations:
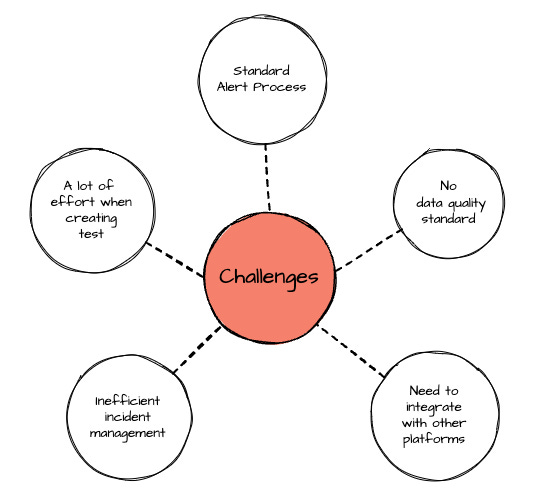
Lack of standardized data quality measurements across teams.
Creating tests for datasets involved significant manual effort.
The incident management process required improvement.
Integration with other data platforms was necessary to provide a centralized experience for all of Uber's internal data users.
A standardized, automated method for creating alerts was needed.
Data Quality Standardization
Here are some common data issues when Uber tried to collect feedback from internal data users and analyze significant data incidents in the past:
Data arriving late after
Data are missing or duplicated entries
Data discrepancies between different data centers
Data values are incorrect.
Following these insights, they define the below test categories, which expect to cover all data quality aspects:
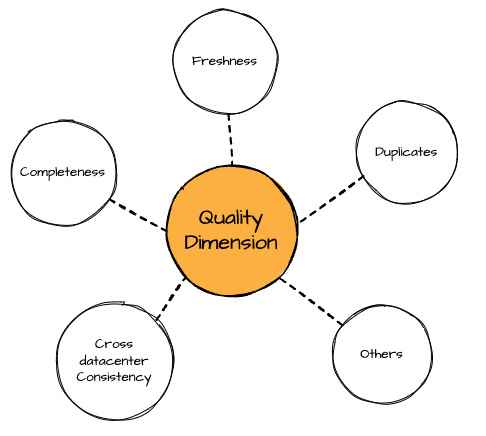
Freshness: the delay after which data is 99.9% complete
Assertion pass if current_timestamp – latest_timestamp where data is 99.9% complete < freshness SLA
Completeness: the row completeness percentage.
Assertion pass if downstream_row_count / upstream_row_count > completeness SLA
Duplicates: the percentage of rows that have duplicate primary keys
Assertion pass if (1 – primary_key_count ) / total_row_count < duplicates SLA
Cross-datacenter Consistency: the percentage of data loss by comparing a dataset copy in the current data center with the copy in the other data center.
Assertion pass if min(row_count, row_count_other_copy) / row_count > consistency SLA
Others: any test with complicated checks based on business logic
Based on User-defined tests
Data Quality Platform Architecture
From a 10,000-foot view, Uber's data quality architecture consists of the following components:
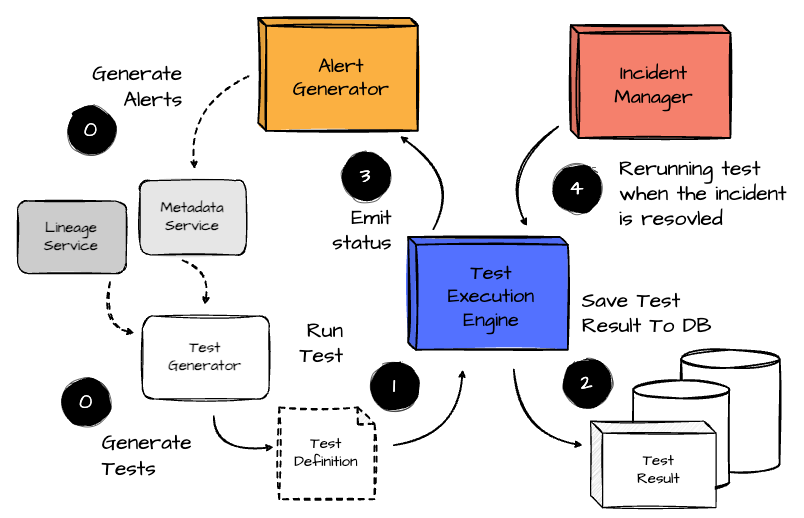
Test Execution Engine
Test Generator
Alert Generator
Incident Manager
Platform’s success metrics
Consumption Tools
The Test Execution Engine runs onboarded tests on schedules or on-demand using various query engines, with the results stored in databases. The other components leverage this engine to cover the entire data quality lifecycle.
Test Generator
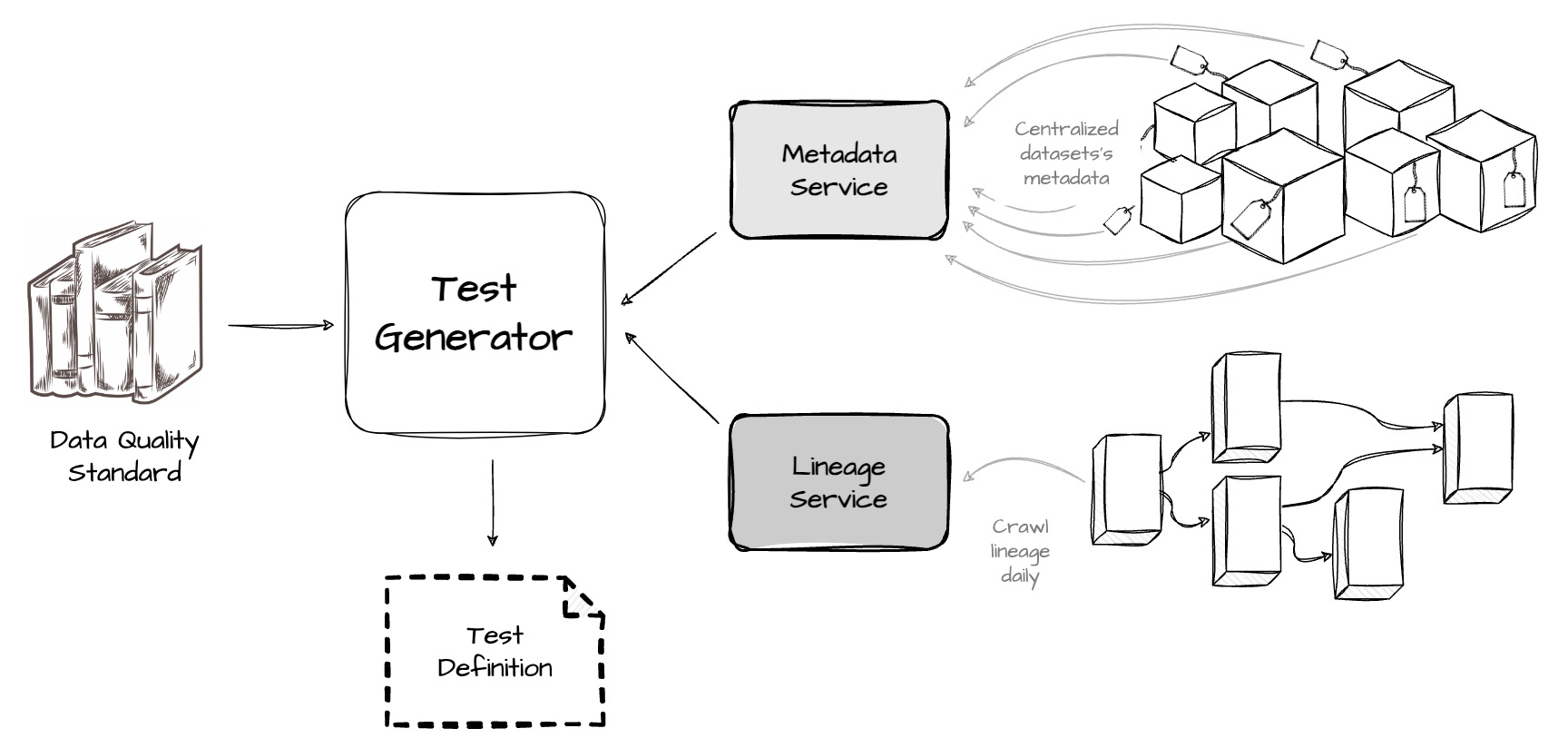
This component is designed to automatically generate the standard tests defined in the "Data Quality Standardization" section. The tests are generated using the dataset’s metadata, fetched from Uber’s centralized metadata service. Key fields required during the test auto-generation process include the dataset’s SLAs, partition keys (for large tables that test only the latest data partition), and primary keys.
Uber also supports auto-generating tests for all upstream and downstream tables, leveraging internal lineage service. Uber created a daily Spark job to fetch the latest lineage to support this use case. The job also refreshes all auto-generated test definitions to reflect any metadata change and accordingly updates the logic of the test generation process.
Test Execution Engine
The engine is the Celery-based web service supporting approximately 100,000 daily executions of about 18,000 tests. Tests can be auto-generated (like mentioned above) or defined by users. Each test is characterized by an assertion that must be true for it to pass.
The tests can be reduced to a few logical assertions. The most basic is comparing a computed value with a constant number. Another common pattern is comparing one computed value with another computed value. Uber observed that most data quality tests are defined by one of these two simple assertion patterns.
Uber uses assertion patterns to construct the test expression, which is a string of symbols representing instructions that the execution engine can interpret.
The string is a flattened Abstract Syntax Tree (AST) that contains expressions and parameters to control the execution. At execution time, the expression is parsed into a tree and evaluated in a post-order traversal. In this approach, every test can be represented as an AST and processed by the execution engine.
Alert Generator
Alerts can also be auto-generated following templates and business rules. The process needs extra parameters which can be retrieved from the metadata service, such as table owners, or alert email. Uber will create alerts per dataset (table A or table B) per test category (freshness or completeness) based on results generated by the test execution engine. Moreover, Uber’s engineers also need to prevent false alerts and provides good user experience.
Uber introduced a sustained period indicating the table SLA allowing test failures. If the test has a sustained period of 3 hours, the platform will set its status as WARN until the test failures violate the sustained period.
Even for real alerts, the unnecessary number of alerts can overwhelm users. For example, when data arrive late, the freshness alert will trigger, and the Completeness and Cross-datacenter Consistency alerts are very likely to be triggered at the same time—three alerts for one issue.
Uber tries to limit the alert count in this case by default setting the Freshness alert as a dependency of other categories, so other alerts will be ignored to avoid duplicate notifications about the same root cause.
Incident Manager

After users had received an alert, investigated the root cause, and mitigated the quality issue, Uber added an internal scheduler to rerun failed tests with exponential backoff automatically. Thanks to this, users can validate whether the incident has been resolved successfully if the same test passes again and resolve the alert automatically without any user manual intervention.
Uber also developed a tool that allows users to annotate an incident and trigger a rerun manually. Users can report any incidents they discover while consuming data, and the data quality platform will check for overlap with any auto-detected incidents. Data producers are notified to acknowledge reported incidents. Uber aggregates both auto-detected and user-reported incidents to ensure that the final data quality status reflects all quality-related factors.
Consumption Tools
Uber also provides a variety of different tools to let users understand their datasets’ quality:
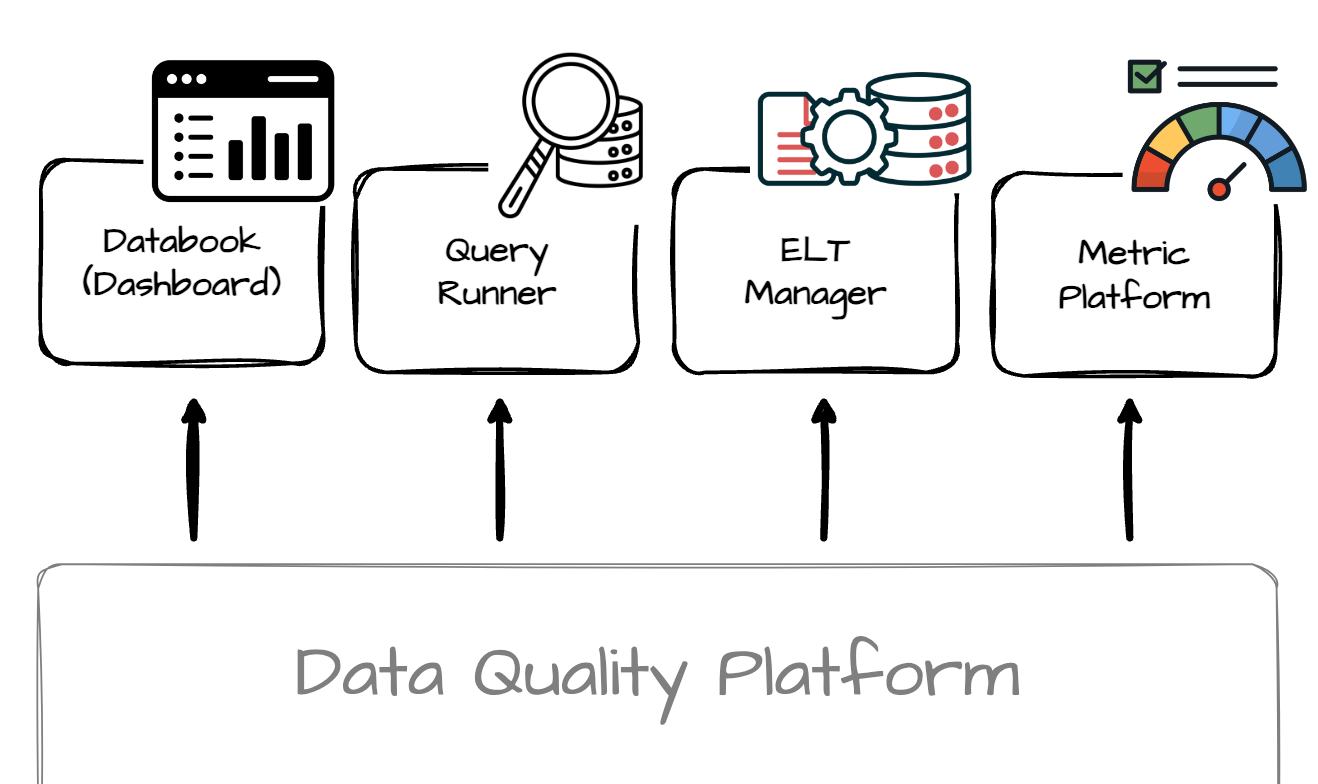
Databook is the centralized dashboard that manages metadata for all Uber datasets. Uber integrated the quality platform with Databook to show data quality results in the UI.
Uber has a Query Runner tool that can access any data storage, such as MySQL, Postgres, or Hive. The data quality platform integrates with this tool to help users query quality status. The query API takes the dataset name and time range and verifies whether the query time range overlaps with any ongoing data incidents.
The ETL Manager serves as the controller for all Uber data pipelines. It can call the data quality platform to trigger new test executions immediately after a pipeline finishes, ensuring a quality check is performed. Additionally, before scheduling a data pipeline, the ETL Manager can consume data quality results for its input datasets. If the quality of any dataset fails to meet the SLA, the ETL Manager will not run the pipeline.
Uber has a metric platform that consolidates business metrics definitions and calculates and serves metrics using raw datasets. The data quality platform is closely integrated with the metric platform by defining specific standard tests for metrics and providing metric-level quality through the metric platform's query layer.
Outro
Thank you for reading this far.
In this article, we've explored how Uber established data quality standards across internal teams and built a platform capable of efficiently testing data quality across Uber's vast number of datasets.
See you in my next blog.
References
[1] Uber Engineering Blog, How Uber Achieves Operational Excellence in the Data Quality Experience (2021)
Before you leave
If you want to discuss this further, please leave a comment or contact me via LinkedIn, Email, or Twitter.
It might take you five minutes to read, but it took me more than five days to prepare, so it would greatly motivate me if you considered subscribing to receive my writing.
This was a great read. Thank you! I’m looking to automate data quality monitoring at my job and this article has given me so many ideas and validates some approaches I’m working towards.