

How AutoMQ Reduces Nearly 100% of Kafka Cross-Zone Data Transfer Cost
How AutoMQ Reduces Nearly 100% of Kafka Cross-Zone Data Transfer Cost
Producing data with the broker in the same availability zone with S3 WAL, self-balancing, and leveraging Kafka rack-awareness

My name is Vu Trinh, and I am a data engineer.
I’m trying to make my life less dull by spending time learning and researching “how it works“ in the data engineering field.
Here is a place where I share everything I’ve learned.
Not subscribe yet? Here you go:
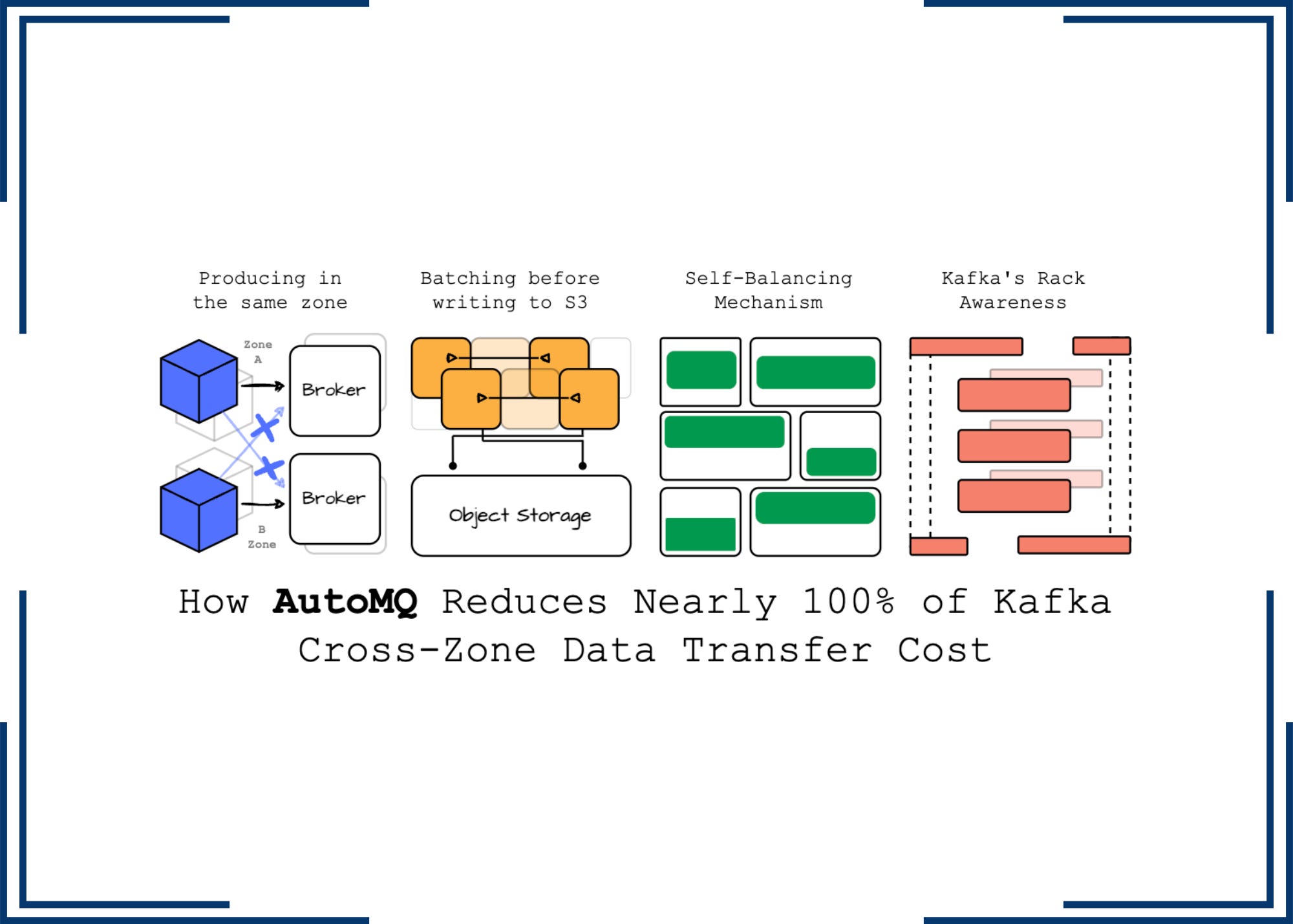
I wrote this article with the help of Kaiming Wan, the Director of Solutions Architecture and Lead Evangelist at AutoMQ. For more information about AutoMQ, you can visit their website here.
Intro
If you're interested in messaging or streaming systems, you've definitely heard of Kafka. Chances are, you've also come across countless solutions claiming to be better than Kafka.
This proves two things: First, more and more companies are incorporating Kafka into their infrastructure thanks to its versatility (a growing market). Second, many users struggle with operating Kafka, especially in this cloud era (pain points to resolve).
When bringing Apache Kafka to the cloud, its replication factor causes the leader to send received data to other followers in different Availability Zones (AZs). The data transfer cost may not seem obvious at first compared to compute and storage costs; however, based on observations from Confluent, cross-AZ transfer costs can surprisingly account for more than 50% of the total bill (more on this later).
In the WarpStream article that I published not long ago, we found that WarpStream avoids cross-AZ transfer costs by hacking the service discovery to ensure that the client always communicates with the broker in the same AZ. WarpStream’s rewriting of the Kafka protocol plays a vital role here.
This week, we will explore how AutoMQ, a 100% Kafka-compatible alternative solution, can help users significantly reduce cross-AZ transfer costs. The solution is designed to run Kafka efficiently on the cloud by leveraging Kafka’s codebase for the protocol and rewriting the storage layer so it can effectively offload data to object storage with the introduction of the WAL.
I’ve written a detailed article about AutoMQ not long ago; you can find it here.
Here’s the structure of this article: First, we’ll review Confluent’s observation on Apache Kafka. Then, we’ll provide an overview of AutoMQ, and finally, we’ll discover how AutoMQ can help users reduce data transfer costs.
For my convenience in delivering insights, AutoMQ features are described using AWS services such as S3 or EBS.
Cross AZ cost
Apache Kafka was originally developed at LinkedIn to meet the company’s intense log processing demands. It was purpose-built for LinkedIn's environment, where engineers optimized Kafka by leveraging the page cache and a sequential access pattern on disk. This approach allowed them to achieve very high throughput while keeping the system relatively simple, as the operating system handled most of the storage-related tasks.
Kafka relies on replication to ensure data durability. When messages are written to leader partitions, they must be replicated to follower partitions. Initially developed at LinkedIn, Kafka operated primarily in self-hosted data centers, where the infrastructure team did not consider network costs when leaders replicated messages to followers across different data centers.
However, the situation changes when users move Kafka to the cloud. Leaders replicate data to followers in different Availability Zones (AZs) to ensure data availability in case of AZ failures, but cloud providers impose network fees for data transfer across zones. According to observations from Confluent, the cost of cross-AZ data transfer due to replication can surprisingly account for more than 50% of infrastructure costs when self-managing Apache Kafka.

Here are some numbers to make it easier to imagine: giving a Kafka cluster with three brokers distributed across three different availability zones. If one broker in a zone goes down, the cluster can still serve users with the two remaining followers. A well-balanced cluster will try to place partition leaders across three zones, implying that the producers will write to a leader in another zone roughly two-thirds of the time.
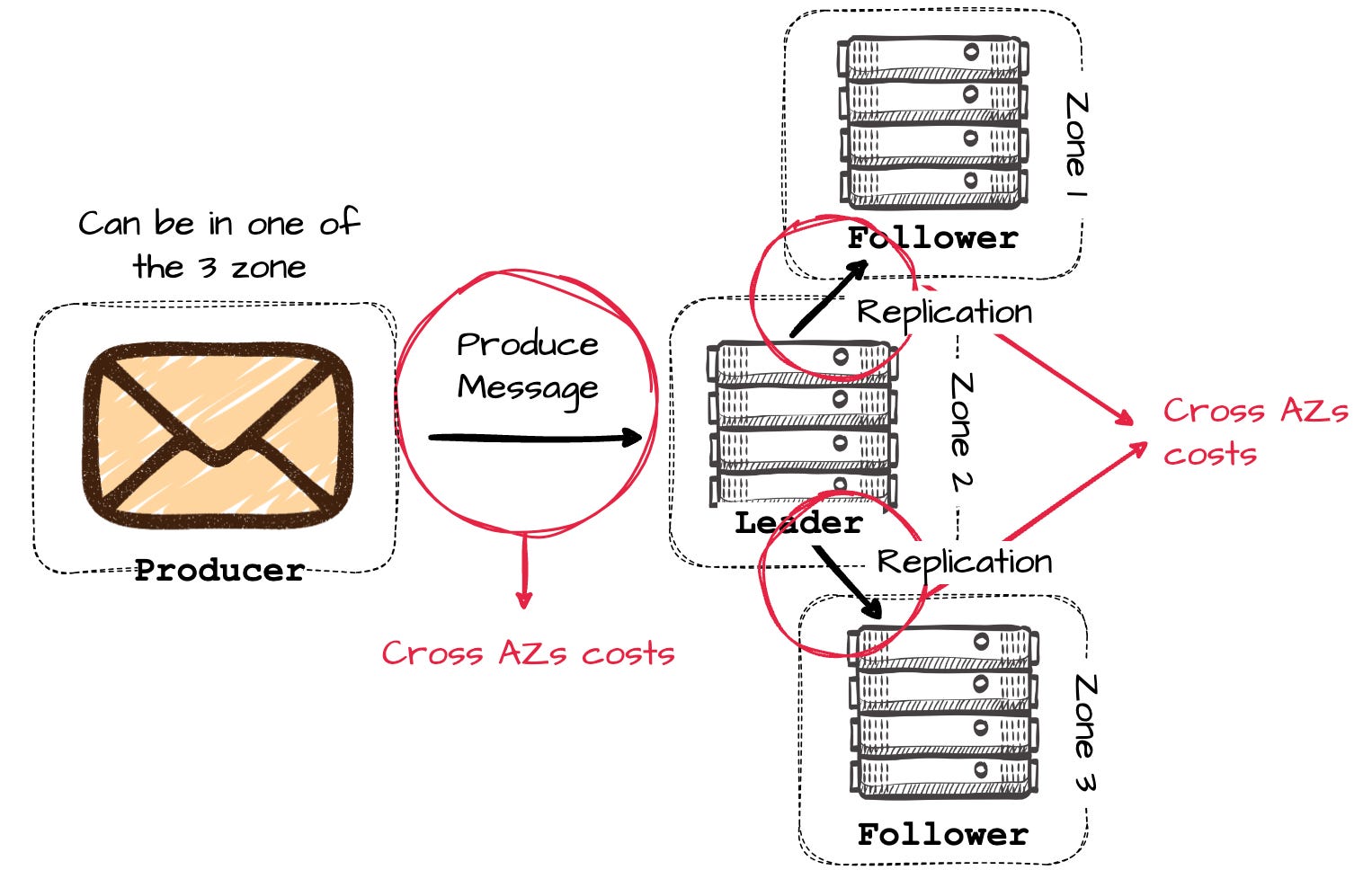
Once the leader receives the message, it will replicate the data to brokers in other AZs to ensure high data reliability, which results in generating twice the cross-AZ traffic of the initial produce request.
In short, Apache Kafka's multi-AZ deployment architecture will generate at least (2/3 + 2) times the unit price of cross-AZ traffic ($0.01/GB in AWS, with ingress and egress charged separately).
The calculation below does not account for the consumer cross-AZ cost.
If we use three r6i.large (2 cores - 16GB RAM) brokers, which provide a write throughput of 30MiB/s, the monthly cross-AZ traffic cost for Apache Kafka can be calculated as follows:
30 * 60 * 60 * 24 * 30 / 1024 * (2 / 3 + 2) * 0.02 = $4050
The VM cost, however, is only 3 * 0.126 $/h (the r6i.large unit price) * 24 * 30 = $272. (6.7% of the cross-AZ traffic cost)
The following sections will explore how AutoMQ helps users reduce cross-AZ costs. But first, let's briefly overview AutoMQ.
AutoMQ Overview
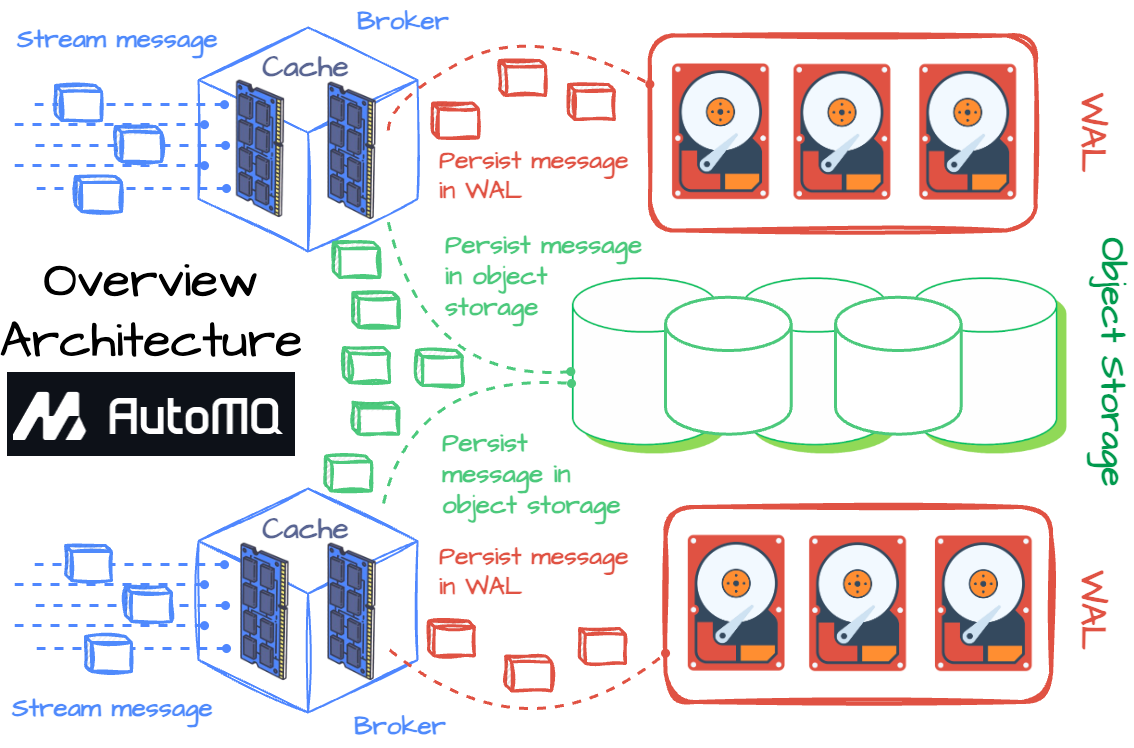
AutoMQ aims to enhance Kafka's efficiency and elasticity by enabling all messages to be written to object storage without compromising performance.
AutoMQ reuses Apache Kafka's code for computation and protocol to achieve this, introducing a shared storage architecture to replace the Kafka broker’s local disk. From a high-level perspective, the AutoMQ broker writes messages into a memory cache. Before transferring the message to object storage asynchronously, the broker must write the data into the Write-Ahead Log (WAL) storage to ensure durability.
A write-ahead log is an append-only disk structure used for crash and transaction recovery. Database changes are first recorded in this structure before being written to the database.
AutoMQ employs an off-heap cache memory layer to handle all message reads and writes, providing real-time performance. The EBS device acts as WAL for AutoMQ; when the broker receives a message, it writes messages to the memory cache and returns acknowledgments only once they persist in WAL. The EBS is also used for data recovery during broker failures.
All AutoMQ data is stored in object storage using AWS S3 or Google GCS. The broker writes data to the object storage asynchronously from the log cache. For metadata management, AutoMQ leverages Kafka's draft mode.
A great feature of AutoMQ's WAL is its flexibility, allowing users to choose different storage options to suit their specific use cases. For instance, if AWS releases a more advanced disk device in the future, users can seamlessly adopt this new storage option to enhance AutoMQ's performance.
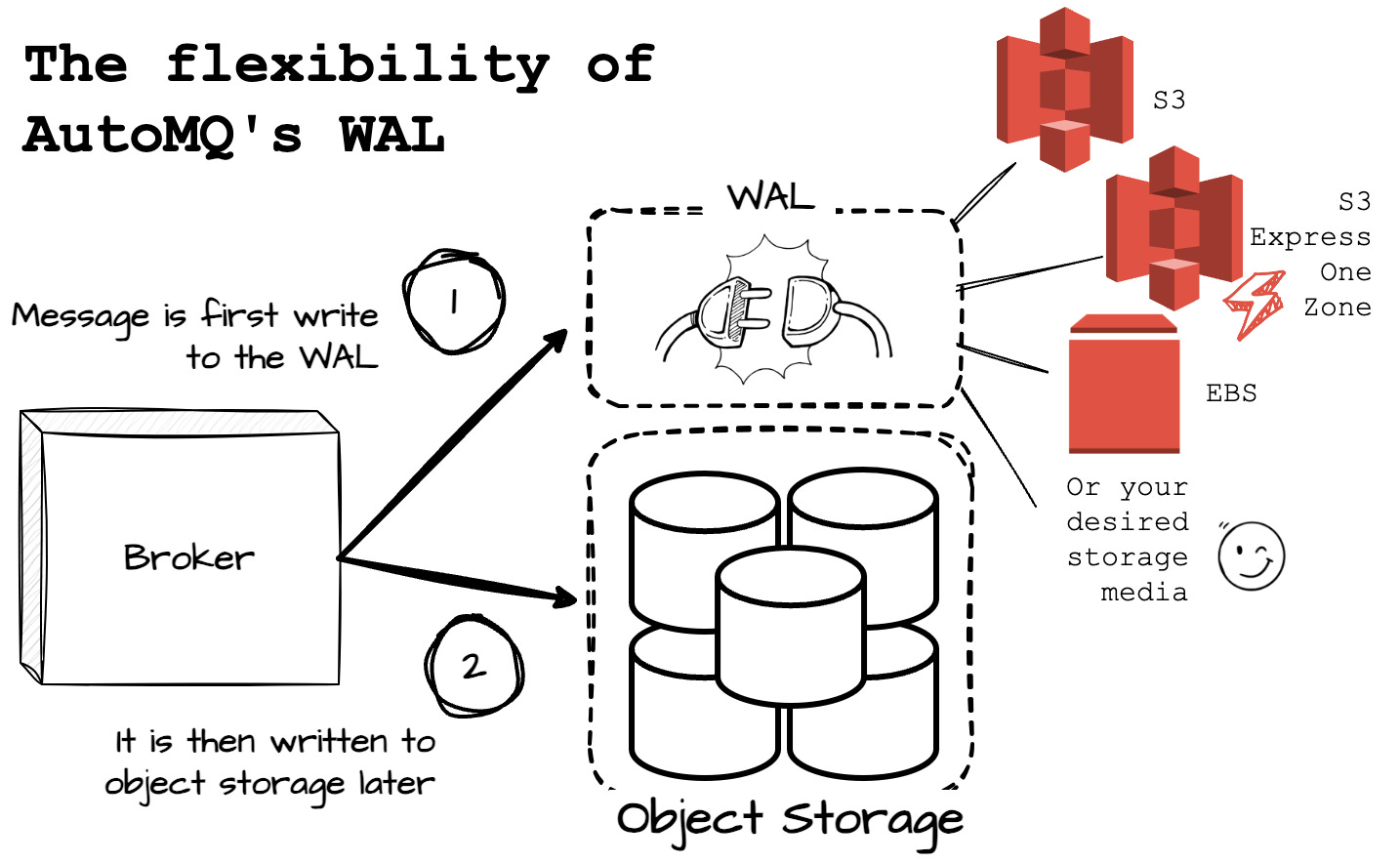
In the next section, we will explore how AutoMQ has developed an intriguing solution when using S3 as the WAL to reduce cross-AZ costs by nearly 100%.
How AutoMQ Reduces Cross-Cost
Produce path
With EBS WAL, although cross-AZ data transfer costs cannot be eliminated, AutoMQ significantly reduces these network costs since data is stored in S3 and doesn't require replication between brokers. However, customers are still charged for cross-AZ data transfer when producers send messages to leader partitions.
AutoMQ introduced a solution where the WAL is implemented using S3 to eliminate cross-AZ data transfer costs. Instead of landing data on EBS before writing it to S3, the S3 WAL allows the broker to write data directly to S3, ensuring the producer sends messages only to a broker within the same AZ.
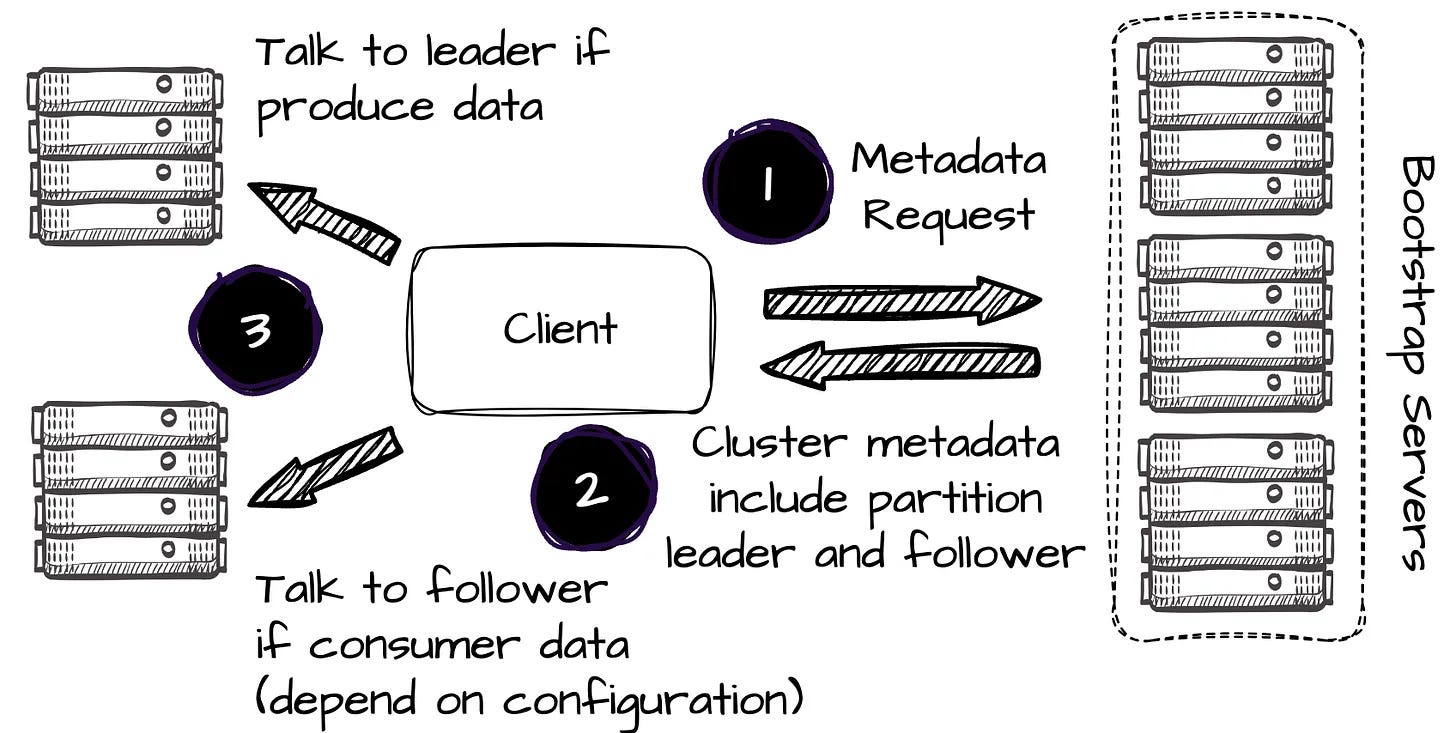
In Kafka, the producers send metadata requests to bootstrap servers to retrieve metadata, including the identity of the partition leader broker, before sending messages. When producing data, the client always attempts to communicate with the leader of a given topic partition.
In Kafka, write always done via the leader.
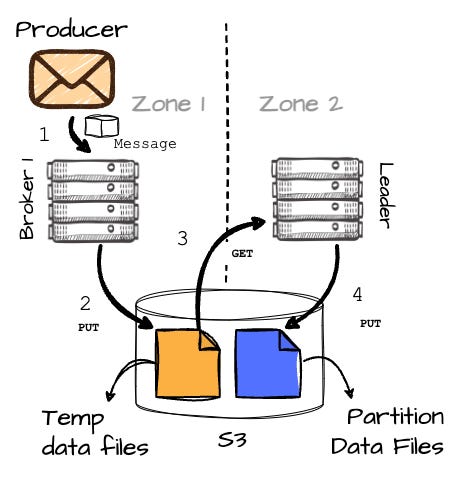
Things get different with S3 WAL in AutoMQ. Imagine a scenario where the producer is in the AZ1, and the leader (B2) of Parition 2 (P2) is in the AZ2. In the AZ1, there is also a broker 1 (B1). Let's check out the full path of message production in this approach.
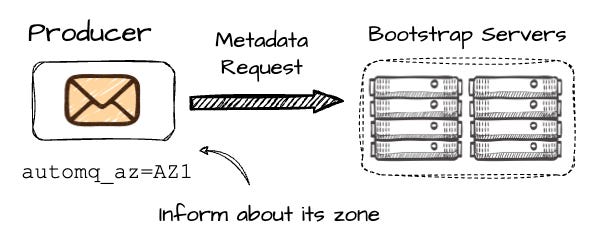
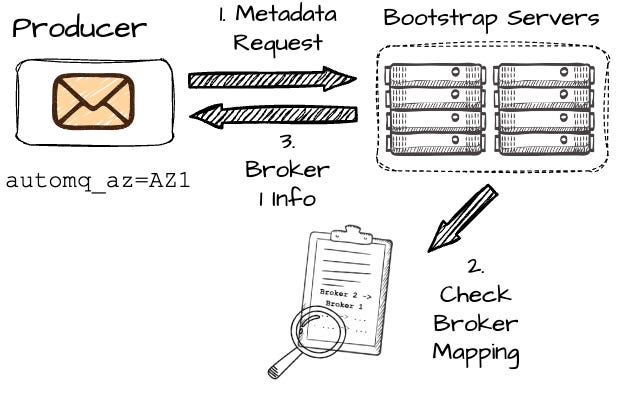
When the producer wants to write to the P2, it first makes the metadata request to the set of bootstrap brokers; the producer must include information about its AZ, which in this case is AZ1.
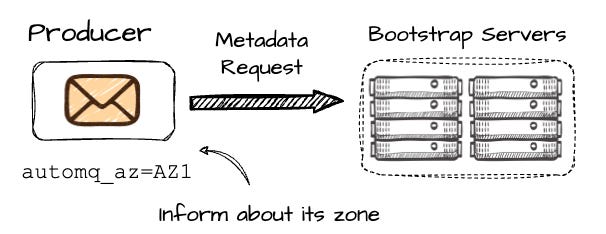
Image created by the author.
In Kafka, after making a metadata request, the producer may receive information about broker B2, which is in a different AZ than the producer, resulting in cross-AZ costs. However, AutoMQ aims to avoid this.
On the AutoMQ side, brokers are mapped across different AZs using a consistent hash algorithm. For instance, let’s assume AutoMQ maps B2 in AZ2 to B1 in AZ1. Since AutoMQ knows that producer Pr1 is in AZ1 (based on the metadata request), it will return the information of B1 for this request. If the producer is in the same AZ as B2, it will return the information of B2. The core idea is to ensure the producer always communicates with a broker in the same AZ, effectively avoiding cross-AZ communication.
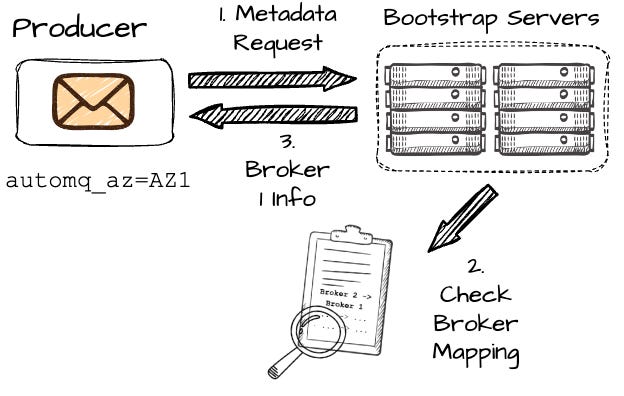
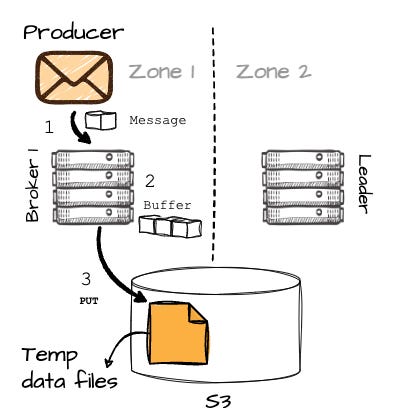
Image created by the author. After receiving the information about B1 (keep in mind, this broker isn't responsible for the desired partition.), the producer will begin sending messages to B1.
B1 buffers the messages in memory, and when it reaches 8MB or after 250ms, it writes the buffered data into object storage as a temporary file.
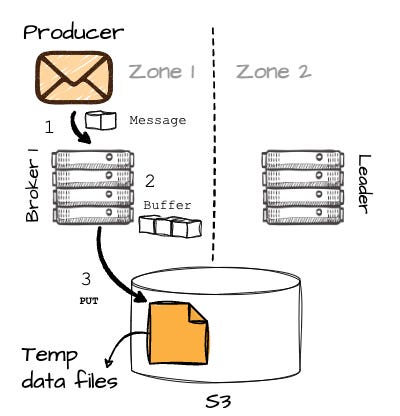
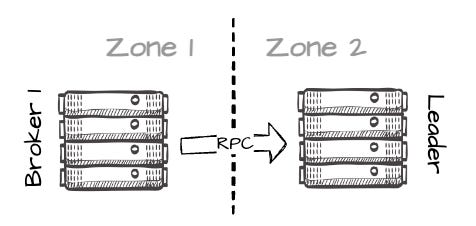
Image created by the author. Here’s where it gets interesting: after successfully writing the messages to S3, B1 makes an RPC request to B2 (the actual leader of the partition) to inform it about the temporary data, including its location (this will result in a small amount of cross-AZ traffic between brokers in different AZs.)
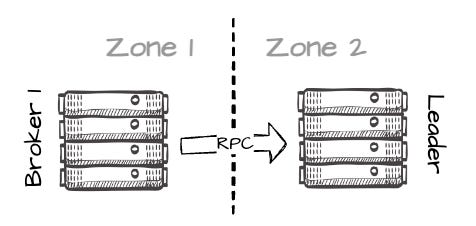
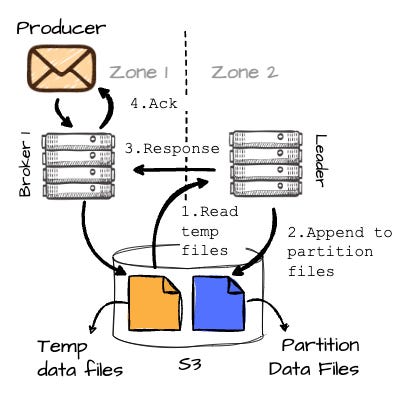
Image created by the author. B2 will then read this temporary data back and append it to the destination partition (P2). Once B2 has completed writing the data to the partition, it responds to B1, which then finally sends an acknowledgment to the producer.
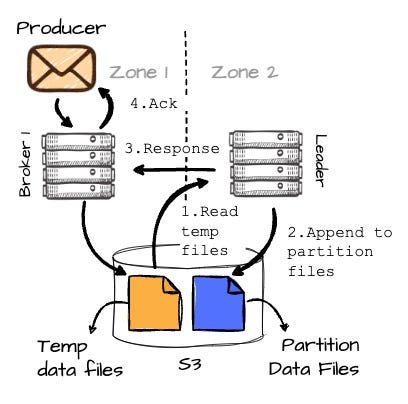
Image created by the author.
Here is a diagram to help you grasp the entire process:
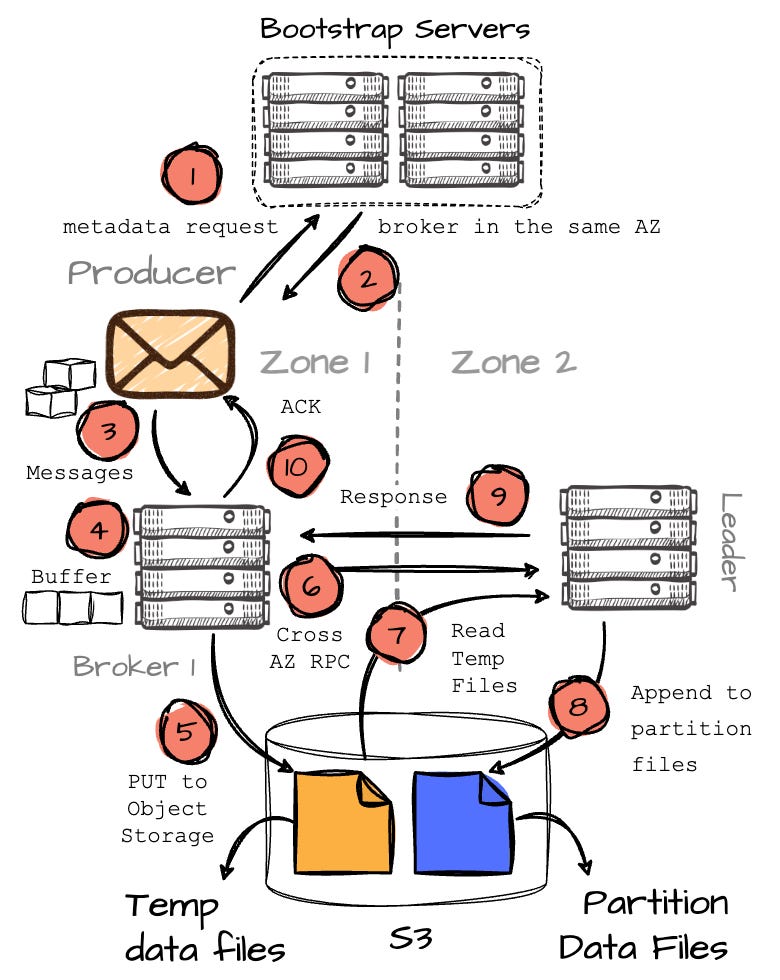
This approach eliminates cross-AZ data transfer costs entirely, but customers need to set up more VM instances (brokers) than with EBS WAL. The reason is tied to the VM and network throughput limitations in the cloud. Compared to EBS WAL, additional data must be read from S3, which consumes the VM’s network bandwidth. In other words, S3 WAL requires more VMs to handle the increased network throughput, ensuring it maintains the same write and read performance as EBS WAL.
Consume Path
For the consume path, the process is almost identical to Kafka. Thanks to 100% Kafka compatibility, AutoMQ consumers can take advantage of Kafka's rack-awareness features for the data consumption path, ensuring they pull data from brokers in the same AZ.
One more important factor to note regarding how AutoMQ helps consumers eliminate cross-AZ costs is its internal self-balancing mechanism. This mechanism includes built-in rack-aware partition scheduling, which ensures AutoMQ balances partitions across brokers from multiple AZs.
Although Apache Kafka supports the rack-aware mechanism, this feature alone cannot entirely eliminate cross-AZ traffic. To prevent cross-AZ traffic costs, Apache Kafka would require that partition balance across AZs remain intact throughout the entire operation, even during scaling, partition migration, or other processes. AutoMQ, with its self-balancing mechanism, automatically manages these operations for users. This not only ensures traffic is balanced and the system self-heals in case of failures, but it also plays a crucial role in reducing cross-AZ traffic costs.
I will try to cover the AutoMQ’s self-balancing mechanism in the future
Observation
Users can choose between WAL implementations for the optimal solution depending on different scenarios. For latency-sensitive scenarios, such as anti-fraud, financial transactions, or real-time data analysis, EBS WAL is preferable. For use cases where latency is not a priority, such as log collection or observability data ingestion, S3 WAL can lead to significant cost savings.
From what we’ve learned above, the WAL implementation plays a crucial role in AutoMQ. The WAL is designed to be pluggable, meaning if there are more advanced cloud storage options, like the recent S3 Express One Zone, users can easily integrate them into the WAL. This approach allows AutoMQ to fully leverage the advantages of emerging cloud storage solutions to adapt to various user scenarios. By abstracting the WAL, AutoMQ can quickly harness the benefits of different cloud storage media, embodying what AutoMQ calls 'One for All.’
Outro
In this article, we learned that cross-availability zone costs can make up a large portion of the cloud bill when users run Apache Kafka in the cloud. These costs come from two main factors: producer traffic to the leader in a different AZ and the need to replicate data across brokers.
Next, we explored how AutoMQ addresses this challenge by enabling producers to send messages to brokers within the same AZ. The data is written to S3 in batches, and the leader partition later picks up that data and appends it to the correct partition. In this way, AutoMQ helps reduce nearly 100% of cross-AZ costs. (There is still a small amount of cross-AZ traffic when brokers issue RPC requests across zones.)
Thank you for reading this far. See you in my next blog!
References
[1] With the help of Kaiming Wan, Director of Solutions Architect & Lead Evangelist @ AutoMQ
[2] AutoMQ official documentation
[3] AutoMQ blog
Before you leave
If you want to discuss this further, please leave a comment or contact me via LinkedIn, Email, or Twitter.
It might take you five minutes to read, but it took me more than five days to prepare, so it would greatly motivate me if you considered subscribing to receive my writing.